
- 「SLM(小規模モデル)という言葉を聞くけど、ただ『性能が低いAI』のこと?」
- 「スマホで動くほど小さいのに『賢い』と言われる理由が理解できない」
- 「LLM(巨大モデル)とSLM、結局どちらをビジネスで使えばいいの?」
- SLMが小さくても賢い理由(「教科書学習」という大革命)
- パラメータ数という「脳のシワ」の概念と、性能の因果関係
- 投資家や技術者が知るべき、SLMがもたらすコスト革命の構造
SLM(小規模言語モデル)が小さいのに賢い最大の理由は、「学習データの質(良質な教科書)」にあります。ネットの雑多な情報を詰め込んだLLMに対し、SLMは厳選された高品質なデータだけを徹底的に学ぶことで、「パラメータ(脳の容量)が少なくても、専門業務ならLLMに匹敵する推論力」を身につけた革新的なAIです。
「巨大化の限界」とSLM誕生の背景
これまでAI業界は「パラメータ数(脳の神経細胞の数)」をひたすら増やせば賢くなる、というアプローチをとってきました。しかし、それが限界(コストと電力の壁)に達したことで、まったく新しいアプローチで生まれたのがSLMです。
・結果:超賢いが、超重い
・動作場所:巨大データセンター
・結果:小さくて、特定のタスクに強い
・動作場所:スマホやPC(エッジ)
AIの「脳の容量」や「シワの数」に相当する数字です。GPT-4は数兆個と言われますが、SLMは数十億個(数千分の一)に抑えられています。
【完全図解】エッジAI・SLMとは?AIの「巨大化」から「分散化」への大転換を解説 →

なぜパラメータが少ないのに「賢い」のか?
SLMの性能を劇的に引き上げた技術的ブレイクスルー、それが「教科書品質(Textbook Quality)のデータによる学習」です。Microsoftの「Phi」シリーズなどがこの手法で世界に衝撃を与えました。
インターネット上のあらゆる文章(スパム、フェイクニュース、日記なども含む)を無差別に大量に読み込ませる。「量」で勝負するため巨大な脳が必要。
LLMに「論理的な教科書」や「完璧なコード例」を作らせ、その純度の高いデータだけを徹底的に読み込ませる。「質」で勝負するため脳が小さくて済む。
LLMは「図書館の本を端から端まで全部読んだ、頭でっかちな大人」。一方、SLMは「東大生が作った完璧な参考書だけを繰り返し勉強した、超優秀な小学生」です。知識の幅(雑学)では大人に負けますが、特定の問題を解く力(推論)は小学生でも互角以上に戦えます。

一目でわかる!LLMとSLMの構造比較
では、ビジネスや実務において、どちらをどう使い分けるべきなのでしょうか。構造的な違いを表にまとめました。
| 項目 | LLM(巨大モデル) | SLM(小規模モデル) |
|---|---|---|
| パラメータ数 | 数百億〜数兆 | 数億〜百億程度(1/100以下) |
| 動作環境 | 巨大なクラウドDC(GPU必須) | 個人のPC・スマホ・AI PC |
| 得意なこと | 高度な企画立案、汎用的な対話 | 要約、翻訳、定型業務、検索 |
| コスト・遅延 | API利用料が高い。通信ラグあり | 無料(電気代のみ)。瞬時に反応 |
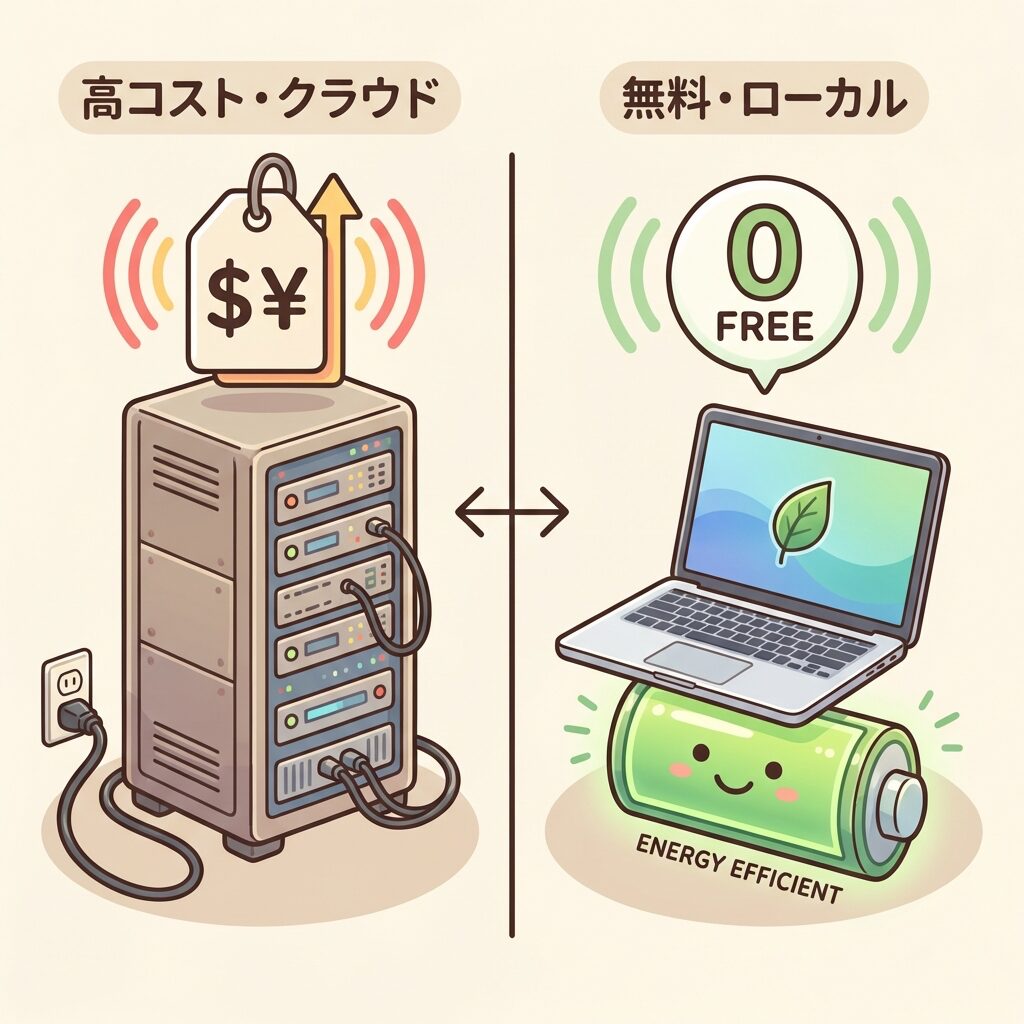
「SLMの進化」があなたにもたらす意味
この技術的ブレイクスルーは、AI産業の構造を根底から覆しつつあります。
投資家:SLMの進化により「クラウドに依存しないAI」が実用化しました。これにより、デバイス側で推論を処理する「AI PC」やエッジ半導体(NPU)関連企業への投資マネーの流入が加速しています。
学生:「巨大なGPUがないとAIの研究ができない」時代は終わりました。手元のノートPCで最新のSLMを動かし、独自の学習をさせる(ファインチューニング)スキルが、今後の就活で最強の武器になります。
技術者:企業は「ChatGPTのAPI代が高すぎる」「機密情報が出せない」と悩んでいます。そこにオープンソースのSLMを使った「セキュアな社内専用AI」を提案・構築できる人材が急激に求められています。
AIの「地産地消」が始まる。なぜ日本企業はローカルAIを急ぐのか? →

よくある誤解:「SLMがあればLLMはもう不要になる?」
SLMの性能が上がったからといって、巨大なデータセンターで動くLLMが不要になるわけではありません。両者は「対立」するものではなく「連携」する関係にあります。

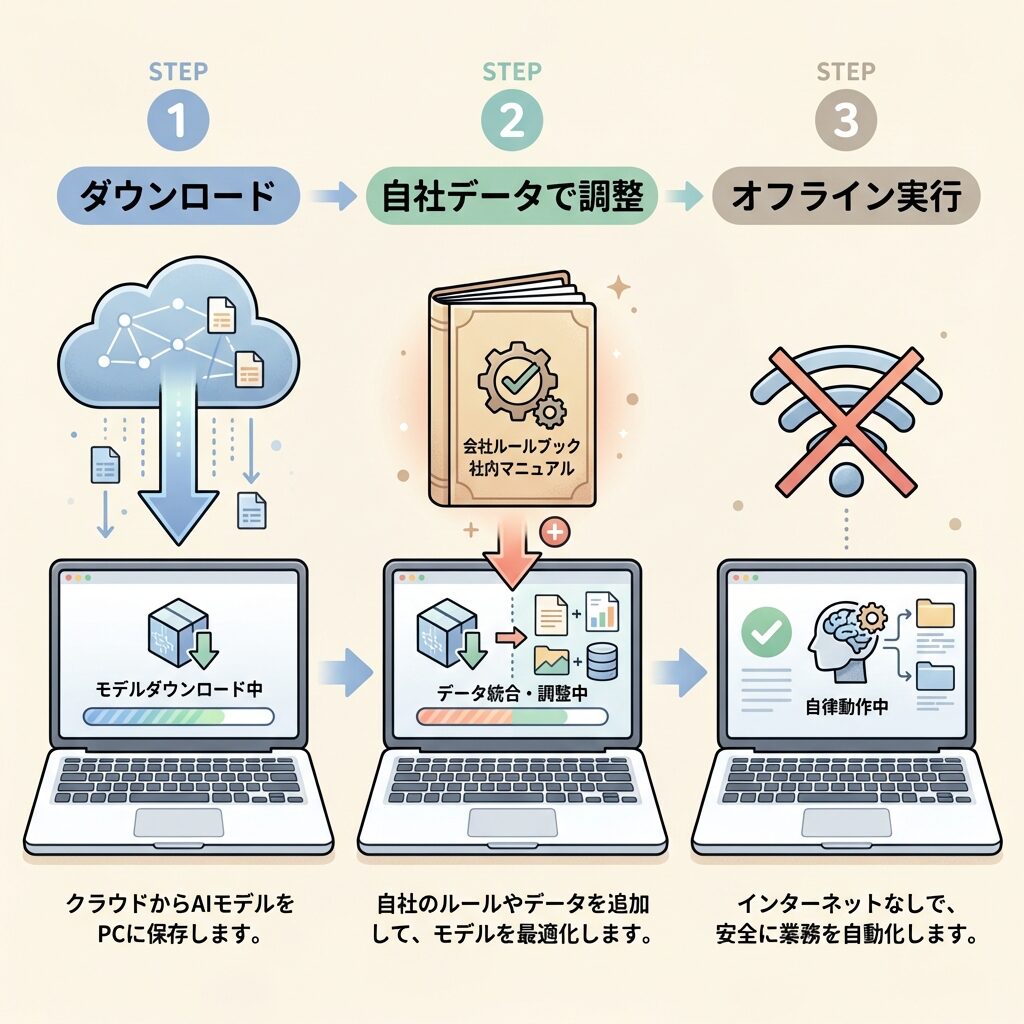
SLMを業務に組み込む3ステップ
実際に企業や個人がSLMを使う場合、どのように進めるのか。シンプルなフローを見てみましょう。
【完全図解】AI PCとは?NPUの役割と「普通のPC」との決定的な違い →
❓ よくある質問(FAQ)

- SLMは脳(パラメータ)が小さくても、「教科書学習」によって驚くほど賢くなった
- 巨大なLLMは汎用性に優れ、SLMは特定業務の処理スピードとコスト削減に優れる
- SLMの普及により、企業は「安全で無料の社内専用AI」を手軽に作れるようになった
- この技術革新が、エッジAI(AI PCやローカルAI)の爆発的な普及を支えている
📖 【完全図解】エッジAI・SLMとは?AIの「巨大化」から「分散化」への大転換を解説 →
この記事は上記ロードマップの「技術深掘り編」です。全体像を復習したい方はこちらへ。


コメント