
「ローカルAI」という言葉、最近よく目にするようになりましたよね。でも、こんなふうに感じていませんか?
- 「ローカルAI」と「クラウドAI」って、結局何が違うの?
- 「オンプレミス」という言葉も出てくるけど、ローカルAIと同じもの?
- なぜ企業は「データを外に出したくない」と思うのか、構造がわからない
- ChatGPTを使うのとローカルAIを使うのと、何がどう変わるの?
- 自分のPCでもAIが動かせるって本当?
- ローカルAIの定義を30秒で理解──「どこで計算するか」がすべて
- クラウドAIとの「データの流れ」の決定的な違いを図解
- 「オンプレミス」「エッジAI」との関係と使い分け
- なぜデータを外に出したくないのか──プライバシーとセキュリティの構造
- ローカルAIのメリット4つとデメリット3つ
- OllamaやLM Studioなど今すぐ試せるツールの紹介
- 学生・技術者にとっての意味と行動指針
ローカルAIとは、インターネット上のクラウドサーバーを使わず、手元のPC・スマートフォン・社内サーバーなど「自分の管理下にある環境」でAIを動かす仕組みのことです。ChatGPTやGeminiのようなクラウドAIは、質問のたびにデータをインターネット経由で外部サーバーに送りますが、ローカルAIはデータが一切外に出ないのが最大の特徴です。「AIは使いたいけど、機密データを外部に送りたくない」──この企業の切実なジレンマを構造的に解決するのがローカルAIであり、2025年以降、AI活用の「第2の選択肢」として急速に注目を集めています。
この記事では、「ローカルAIとは何か」をデータの流れとセキュリティの構造という2つの視点から、初心者でもすっきり理解できるように解説します。技術的な詳細よりも「なぜこの仕組みが必要なのか」という構造の理解を優先しました。
ローカルAIとは?──「どこで計算するか」がすべて
💻 一言でいうと「自分の手元で動くAI」
ローカルAI(Local AI)とは、インターネット上のクラウドサーバーを使わず、手元のPC・スマートフォン・社内サーバーなど「自分の管理下にある環境」でAIの計算・推論を実行する仕組みのことです(出典:テクノ社)。
ここで最も大事なポイントは、「AIの性能の違い」ではなく「AIが計算する場所の違い」です。
クラウドAIは「レストランで食事すること」。食材(データ)をお店(外部サーバー)に持っていき、プロの厨房(高性能GPU)で調理してもらう。おいしいけど、食材は一度お店の外に出すことになる。
ローカルAIは「自宅のキッチンで料理すること」。食材は家から一歩も出ない。自分のキッチン(手元のPC)で全部作る。レストランほど豪華な設備はないけど、食材の安全は完全に自分で管理できる。
ChatGPT・Gemini等
データが外に出る
Ollama・LM Studio等
データが外に出ない
機密データはローカル
それ以外はクラウド
ローカルAIとクラウドAIの違いは「AIの賢さ」ではなく、「計算する場所」と「データの行き先」の違いです。同じAIモデル(例:Llama 3)でも、クラウドで動かせばクラウドAI、手元のPCで動かせばローカルAIになります。

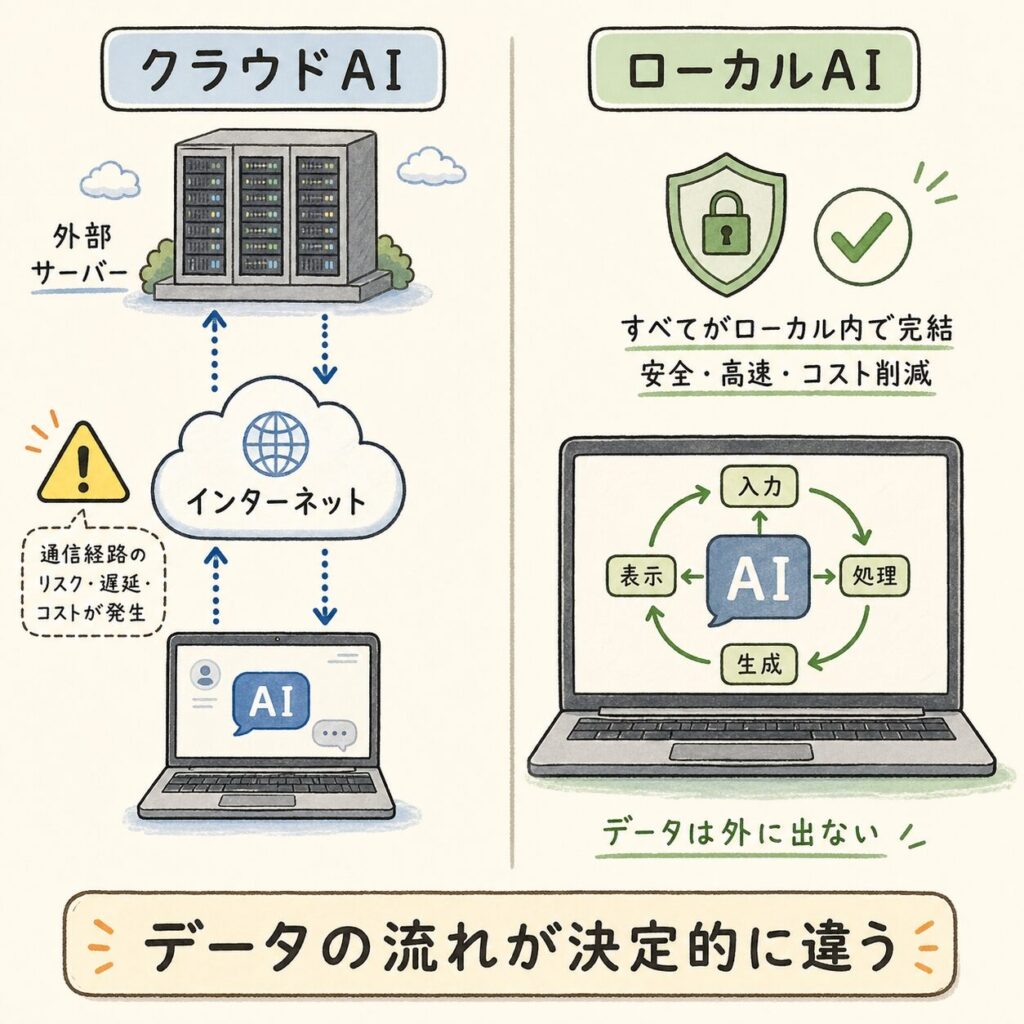
クラウドAIとの違い──「データの流れ」で見ると一目瞭然
🔄 データはどこを通る? 2つの流れを並べて比較
ローカルAIとクラウドAIの違いを理解する最短ルートは、「データがどこを通って、どこで処理されるか」を追うことです。以下の図を見比べてみてください。
「この契約書を要約して」
OpenAI / Google等のDCで処理
回答を受け取る
「この契約書を要約して」
手元のGPU/CPUで推論実行
回答を受け取る
📊 7項目で比較──クラウドAI vs ローカルAI
| 比較項目 | ☁️ クラウドAI | 💻 ローカルAI |
|---|---|---|
| 処理する場所 | 外部のデータセンター | 手元のPC・社内サーバー |
| データの行き先 | 外部に送信される | 外に出ない |
| インターネット | 必須 | 不要(オフラインでも動く) |
| 性能(最大値) | 非常に高い(GPT-4o等) | 中〜高い(ハードに依存) |
| コスト構造 | 月額 or 従量課金 | 初期投資(PC/GPU)+電気代 |
| カスタマイズ | 制限あり | 自由度が高い |
| 代表的なサービス | ChatGPT / Gemini / Claude | Ollama / LM Studio / llama.cpp |
出典:比較内容は テクノ社、Rentec Insight を参考に構成
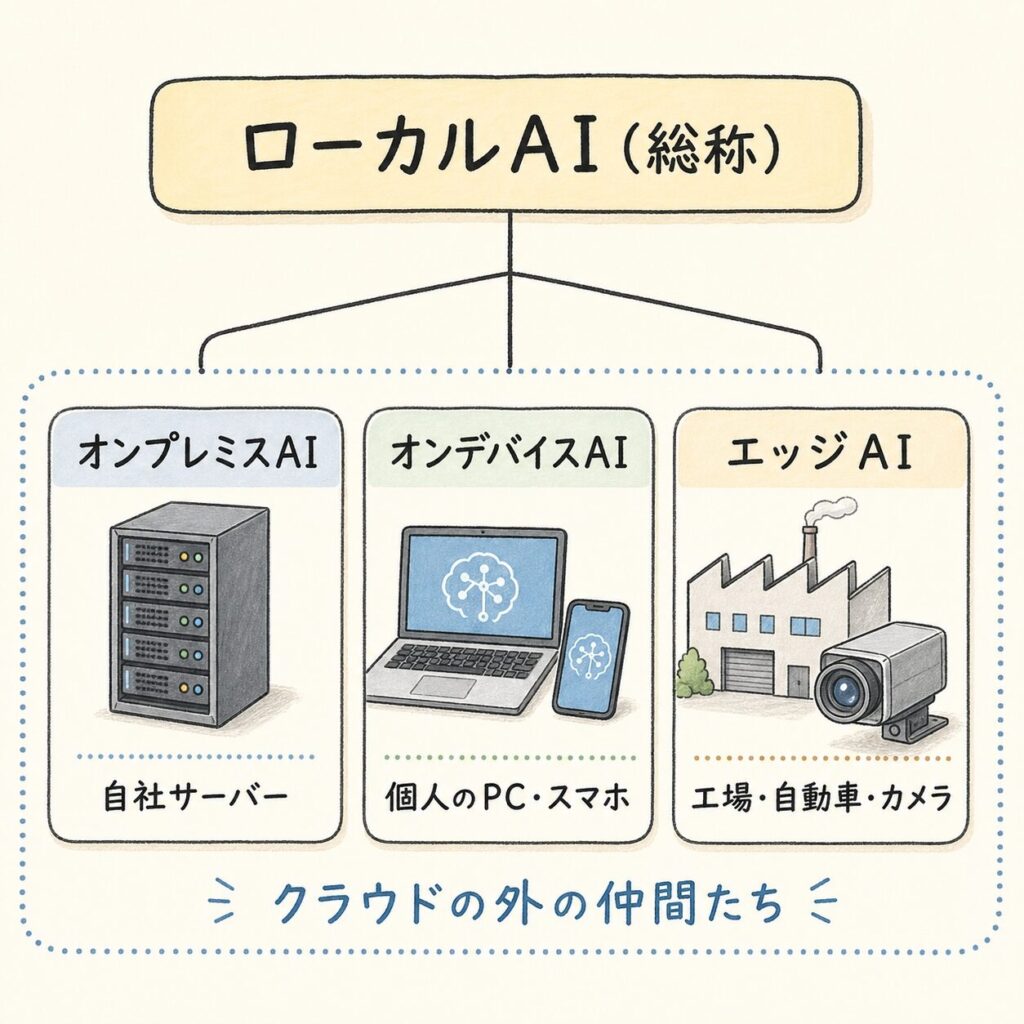
「オンプレミス」「エッジAI」とどう違う?──用語の関係を整理
🗂️ 似た言葉が多すぎる問題を一発で解決する
「ローカルAI」「オンプレミス」「エッジAI」「オンデバイスAI」──似た言葉がたくさん出てきて混乱しますよね。これらはすべて「クラウドの外でAIを動かす」という共通点を持っていますが、スケール(規模)と場所が異なります。
🏢 オンプレミスAI:自社のサーバールームや社内DCに設置。企業の大規模利用向け。「オンプレ」は「自社施設の中に」の意味。
📱 オンデバイスAI:スマートフォン・PC・タブレットなど個人のデバイス上で動作。Apple Intelligence、Copilot+ PC等。
🏭 エッジAI:工場の製造ライン・自動車・カメラなど「現場の端末」で動作。リアルタイム性と低遅延が最優先。
| 用語 | 動作する場所 | 規模 | 代表例 |
|---|---|---|---|
| オンプレミスAI | 自社サーバー・社内DC | 大〜中規模 | NEC・富士通等の法人向けLLMサービス |
| オンデバイスAI | 個人のPC・スマホ | 小規模 | Ollama・LM Studio・Apple Intelligence |
| エッジAI | 工場・自動車・カメラ | 超小規模〜中規模 | NVIDIA Jetson・工場検査AI |
「自社の施設の中に」という意味のIT用語。サーバーやソフトウェアを、クラウドではなく自社のサーバールームやデータセンターに設置して運用する形態を指す。「オンプレ」と略されることが多い。ローカルAIの企業向け実装形態のひとつ。
これらの用語は「敵同士」ではなく「仲間」です。すべて「クラウドに頼らず、自分の近くでAIを動かす」という同じ思想を持っています。違いは「どのスケールで、どんなデバイスで動かすか」だけ。この記事では、これらを包括する概念として「ローカルAI」という言葉を使っています。
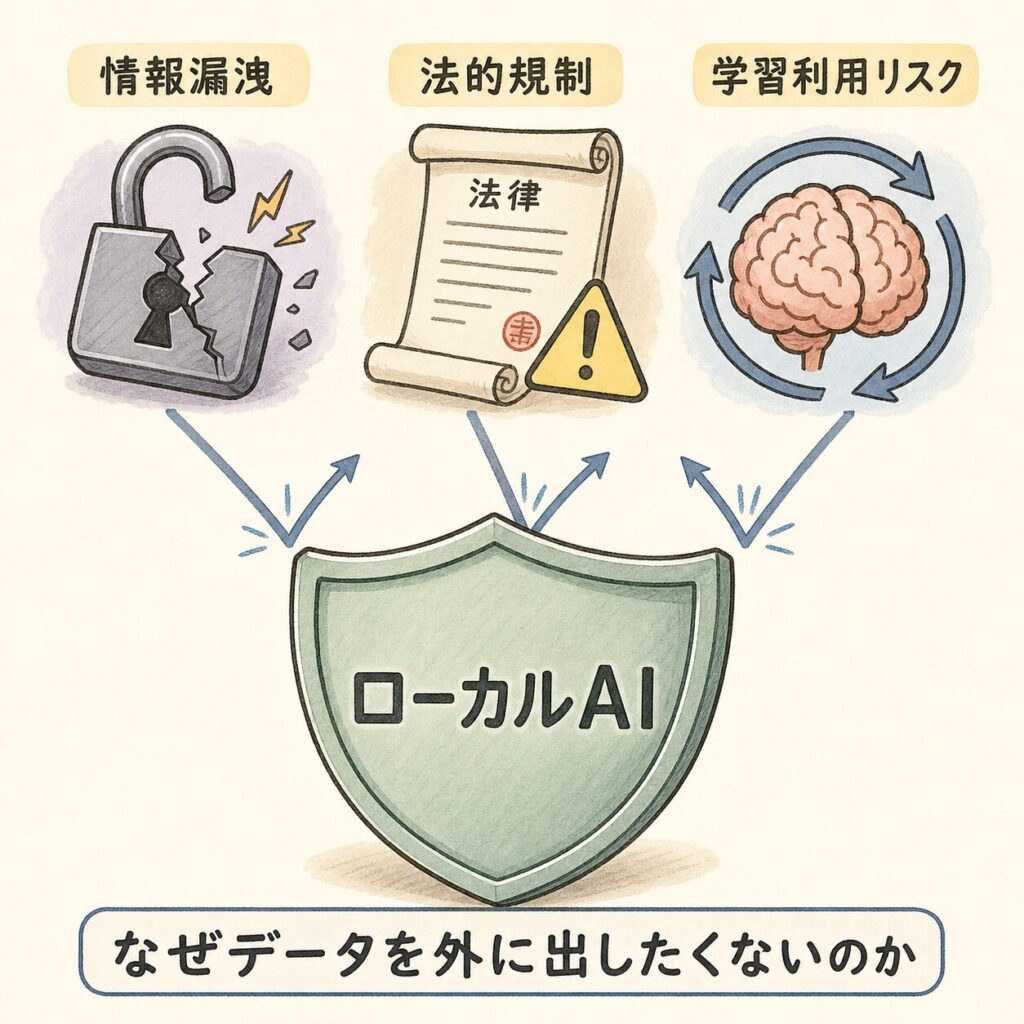
なぜデータを外に出したくないのか──プライバシーとセキュリティの構造
🔒 「AIは使いたい、でもデータは出せない」──企業の切実なジレンマ
ローカルAIが急速に注目されている最大の理由は、「AIを使いたいが、データを外部に送れない」という企業の切実な問題を解決できるからです。では、なぜデータを外に出したくないのか? その構造を整理しましょう。
クラウドAIにデータを送ることは、「自分の日記を、赤ペン先生に郵送で添削してもらう」ようなものです。添削の質は素晴らしいけど、日記は一度自分の手を離れて郵便(インターネット)を通り、先生の家(外部サーバー)に届く。途中で誰かに読まれるかもしれないし、先生が日記の内容を他の生徒の指導に使うかもしれない。
ローカルAIは、「自分の部屋に先生を呼んで、目の前で添削してもらう」イメージです。日記は一歩も外に出ない。
🏛️ 「データ主権」──国もデータの居場所を気にし始めた
近年、国家レベルでも「自国のデータは自国内で処理すべき」という「データ主権(Data Sovereignty)」の考え方が広がっています。IBMは「データ主権とは、データに対する権限を誰が持つかを決定すること」と定義しています(出典:IBM)。
日本でもNTTデータは「オンプレミス内で全てのAI処理を完結させることで、データ主権を実現できる」と述べています(出典:NTTデータ DATA INSIGHT)。ローカルAIは、この「データ主権」を技術的に実現するための重要な手段なのです。
データがどの国の法律の管轄下に置かれるかを決める概念。たとえば日本の企業データが米国のクラウドサーバーに保存されると、米国の法律(例:CLOUD Act)に基づいて開示要求を受ける可能性がある。ローカルAI/オンプレミスAIは、データを自国・自社内にとどめることでこのリスクを回避できる。
ローカルAIの4つのメリット──なぜ今、選ばれるのか
これらのメリットは独立しているのではなく、因果関係でつながっています。「データを外に出さない」→「だからセキュリティが高い」→「だから機密データをAIに食わせられる」→「だから自社専用AIが作れる」──この連鎖がローカルAIの本質的な価値です。

ローカルAIの3つのデメリット──万能ではない理由
⚠️ 知っておくべき3つの「壁」
ローカルAIを快適に動かすには、GPU(グラフィックボード)とVRAM(GPUメモリ)が必要です。一般的な事務PCでは力不足で、VRAM 16GB以上のGPUが実用ラインとされています。初期投資として数十万円〜の出費が伴います(出典:テクノ社)。
GPT-4oやClaude Opus 4のような最先端クラウドAIは、数千台のGPUを使う巨大インフラで動いています。手元のPC1台では同等の性能を出すことは物理的に難しく、ローカルで動かせるのは中規模〜軽量モデルが中心です。ただし、特定の業務(文書要約・翻訳・社内Q&A等)では十分な性能を発揮します。
モデルの選定・インストール・アップデート・トラブルシューティングを自社で行う必要があります。クラウドAIなら「登録してすぐ使える」のに対し、ローカルAIは「環境構築」という準備フェーズが伴います。IT部門や外部ベンダーの支援が必要になる場合も。
「ローカルAI = 性能が低い」と思われがちですが、これは正確ではありません。2025年時点で、Llama 3.3 70BやQwen 2.5 72Bなど、オープンソースの中規模モデルはGPT-3.5を大きく上回る性能を持っており、業務用途では十分実用的です。「最先端の頂点には届かないが、実務に必要な水準は超えている」──これが現在のローカルAIの正確な立ち位置です。

「とりあえず触ってみたい」人へ──今すぐ試せるローカルAIツール
🛠️ 3つの代表的な無料ツール
「理屈はわかったけど、実際にどうやって始めるの?」──その答えは、以下の3つの無料ツールのどれかをインストールすることです。すべてオープンソースで、個人PCで今すぐ試せます。
Large Language Modelの略。ChatGPTやGeminiの裏側で動いている「テキストを理解・生成するAIモデル」のこと。Meta社のLlama、Alibaba社のQwen、Mistral社のMistralなど、無料で使えるオープンソースLLMが急速に増えている。これらをローカルに導入して動かすのが「ローカルLLM」。
① Ollamaの公式サイトからインストーラーをダウンロード → ② ターミナル(コマンドプロンプト)で ollama run llama3.2 と入力 → ③ AIとの会話が始まる。たったこれだけです。モデルは自動でダウンロードされ、すべてPC内で完結します(参考:Qiita ローカルLLM入門)。

よくある誤解を整理する
| ❌ よくある誤解 | ✅ 実際はこう |
|---|---|
| 「ローカルAI = 性能が低い」 | 最先端クラウドAIには及ばないが、業務用途(文書要約・翻訳・Q&A)では十分実用的。Llama 3.3 70Bは旧世代GPT-3.5を大きく上回る。 |
| 「ローカルAIにはスーパーコンピュータが必要」 | VRAM 16GBのGPU(RTX 4060 Ti等)で十分動くモデルが多数ある。10万円台のPCでも始められる。Apple Silicon Macでも快適に動作。 |
| 「ローカルAI = エンジニア専用」 | LM StudioはGUIで操作でき、コマンド不要。Ollamaもコマンド1行で起動。非エンジニアでも始められるツールが揃っている。 |
| 「クラウドAIとローカルAIは二者択一」 | 実際にはハイブリッド運用が最も現実的。機密データはローカル、それ以外はクラウド──とデータの性質に応じて使い分けるのが主流。 |
| 「ローカルAIは無料」 | ソフトウェア(Ollama等)は無料だが、それを動かすハードウェア(GPU搭載PC)には投資が必要。電気代も発生する。「ソフトは無料、ハードは有料」が正確。 |

あなたにとっての意味──実務者・学生の視点
「AIを導入したいが、セキュリティポリシーでクラウドAIが使えない」──こんな壁にぶつかっていませんか? ローカルAIは、この壁を技術的に正面から突破できる手段です。特に製造業・金融・医療・法務・防衛関連では、ローカルAIの導入検討がすでに始まっています。まずはOllamaで「自分のPCでAIが動く」体験をしてみてください。経験があるだけで、社内のAI導入議論で圧倒的な発言力を持てます。
ローカルAIは「AIの中身を自分で触れる」最短ルートです。クラウドAIはAPIを叩くだけですが、ローカルLLMを動かすとGPUのVRAM消費量・推論速度・量子化のトレードオフを肌で感じられます。これは情報系だけでなく、電気工学(GPU設計)・機械工学(冷却)・材料工学(半導体パッケージ)とも接続する知識です。ポートフォリオに「ローカルLLMを触った経験」があると、就活でも研究でも差別化になります。

まとめ:ローカルAIの全体像
① ローカルAIとは:手元のPC・スマホ・社内サーバーなど「自分の管理下にある環境」でAIを動かす仕組み。データが一切外に出ないのが最大の特徴。
② クラウドAIとの違い:違いは「AIの賢さ」ではなく「計算する場所」と「データの行き先」。同じモデルでも動かす場所で分類が変わる。
③ 関連用語の整理:オンプレミスAI・オンデバイスAI・エッジAIはすべてローカルAIの仲間。スケールと場所が違うだけ。
④ なぜ必要か:情報漏洩リスク・法的規制・学習利用リスクという3つの構造的問題をローカルAIが解決する。「データ主権」の技術的実現手段でもある。
⑤ メリット:データが外に出ない・従量課金なし・自由にカスタマイズ・オフラインでも動く。これらは因果の連鎖でつながっている。
⑥ デメリット:高性能ハードが必要・最先端には届かない・運用知識が必要。ただし実務用途では十分な性能のモデルが揃っている。
⑦ 始め方:Ollama・LM Studio・llama.cppが代表的な無料ツール。迷ったらOllamaを入れてコマンド1行で体験できる。
結局こういうことです。ローカルAIとは「データを外に出さずにAIを動かす仕組み」であり、その本質は「AIの性能の選択」ではなく「データの安全の設計」にあります。AIの進化が加速するほど、「どこでAIを動かすか」「データを誰に預けるか」という問いの重要性は増していきます。ローカルAIはその問いに対する、構造的な解答のひとつなのです。
❓ よくある質問(FAQ)
📚 次に読むべき記事
ローカルAIの「対極」にあるクラウドAIは、AIデータセンターで動いています。その構造を知ると、ローカルAIの意味がさらに深まります。
ローカルAIを動かすのに必要な「GPU」の役割を構造から理解。CPUとGPUの違い、なぜGPUがAIに必要なのかがわかります。
クラウドAIの「見えないコスト」=電力消費の構造。ローカルAIが環境面でも注目される背景がわかります。
ローカルAIの性能を左右する「VRAM」の正体。HBMを理解すると、AIハードウェアの構造が見えてきます。
📩 記事の更新情報を受け取りたい方へ
新しい記事が公開されたら、Xアカウント @shirasusolo でお知らせします。AIインフラの構造を一緒に学んでいきましょう。


コメント