「GPUサーバー」「AIサーバー」──最近、AIやデータセンターのニュースで本当によく見かける言葉ですよね。でも、こんなふうに感じていませんか?
- GPUサーバーって、普通のサーバーと何が違うの?
- 「AIサーバー」と「GPUサーバー」は同じもの? 違うもの?
- なぜGPUが入ると消費電力や発熱が激増するの?
- GPUサーバーが増えるとデータセンターの設計が変わるって、どういうこと?
- CPUサーバーとGPUサーバーの構成の違いを図解で比較
- AIサーバーとGPUサーバーの関係性と使い分け
- なぜAI処理はGPU向きなのか──「仕事のやり方」の根本的な違い
- GPUサーバーが発熱・消費電力を増やし、データセンター全体の設計を変えるメカニズム
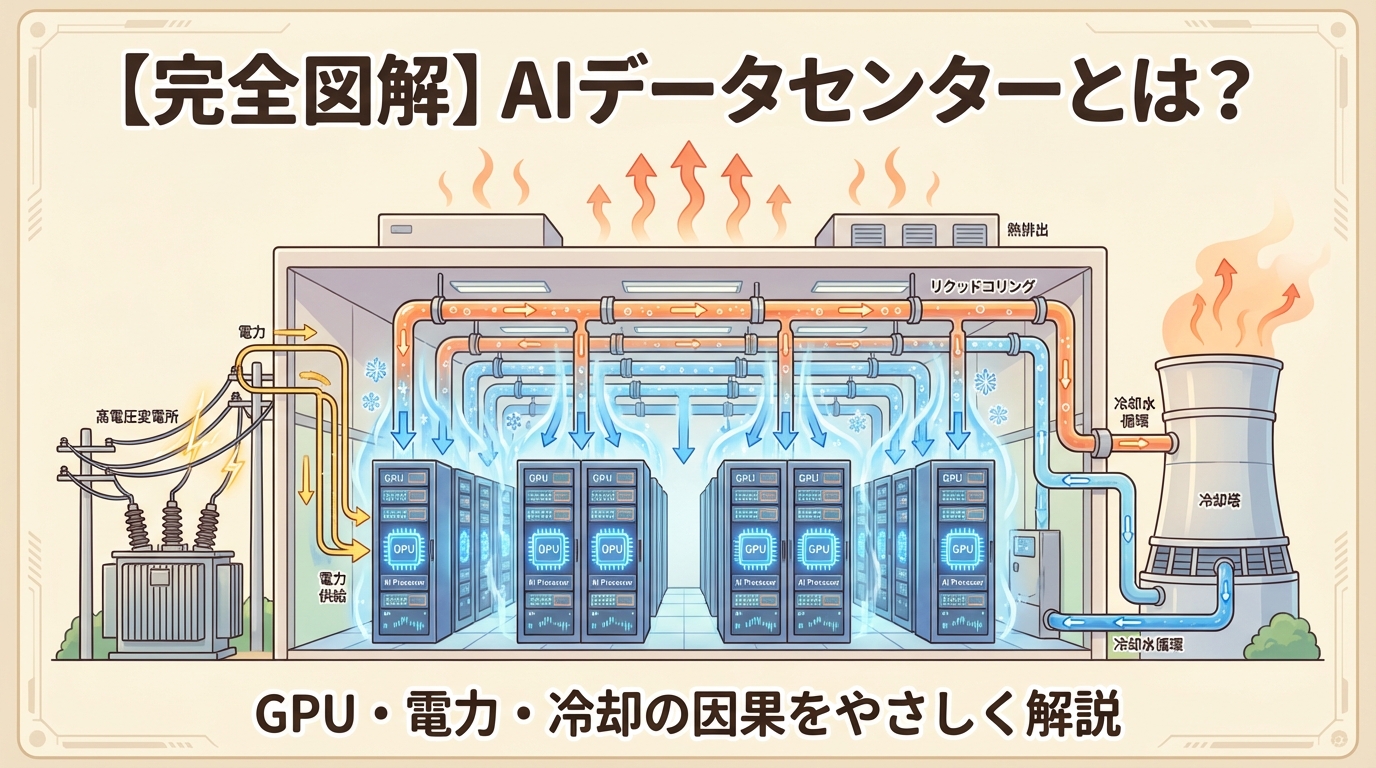
GPUサーバーとは、GPU(画像処理装置)を複数搭載し、大量のデータを並列処理できるサーバーのことです。従来のCPUサーバーが「万能な頭脳を1つ持つ作業者」なら、GPUサーバーは「同じ作業を数千人が一斉にこなすチーム」。この圧倒的な並列処理力がAIの学習・推論に不可欠なのです。ただし、GPUを大量に搭載すると消費電力はCPUサーバーの数倍〜10倍以上に跳ね上がり、発熱も桁違いになります。これが「液冷の必要性」「電力設備の刷新」「データセンター設計の根本的な変化」を引き起こす原因です。AIサーバーは、このGPUサーバーをAI処理に特化させたものであり、技術的にはほぼ同義と考えて問題ありません。
この記事では、「そもそもGPUサーバーって何が違うの?」という疑問に、図解と比喩を使って丁寧に答えていきます。AIデータセンターの全体像を理解するうえで、GPUサーバーの理解は「最初の一歩」です。ここを押さえれば、電力問題も冷却問題も、すべて「なぜそうなるのか」が見えてきます。
GPUサーバーとは? ── まずは30秒で理解する
🖥️ 一言でいうと「GPUを積んだ専用計算マシン」
GPUサーバーとは、GPU(Graphics Processing Unit:画像処理装置)を複数搭載したサーバーのことです。
「サーバー」とは、ネットワークの向こう側で処理をしてくれるコンピュータのこと。普段みなさんがWebサイトを見たり、メールを送ったりするとき、裏側で動いているのがサーバーです。そのサーバーのなかに「GPU」という特殊なチップをたくさん積んだものが、GPUサーバーです。
もう少し身近な例えで説明しましょう。
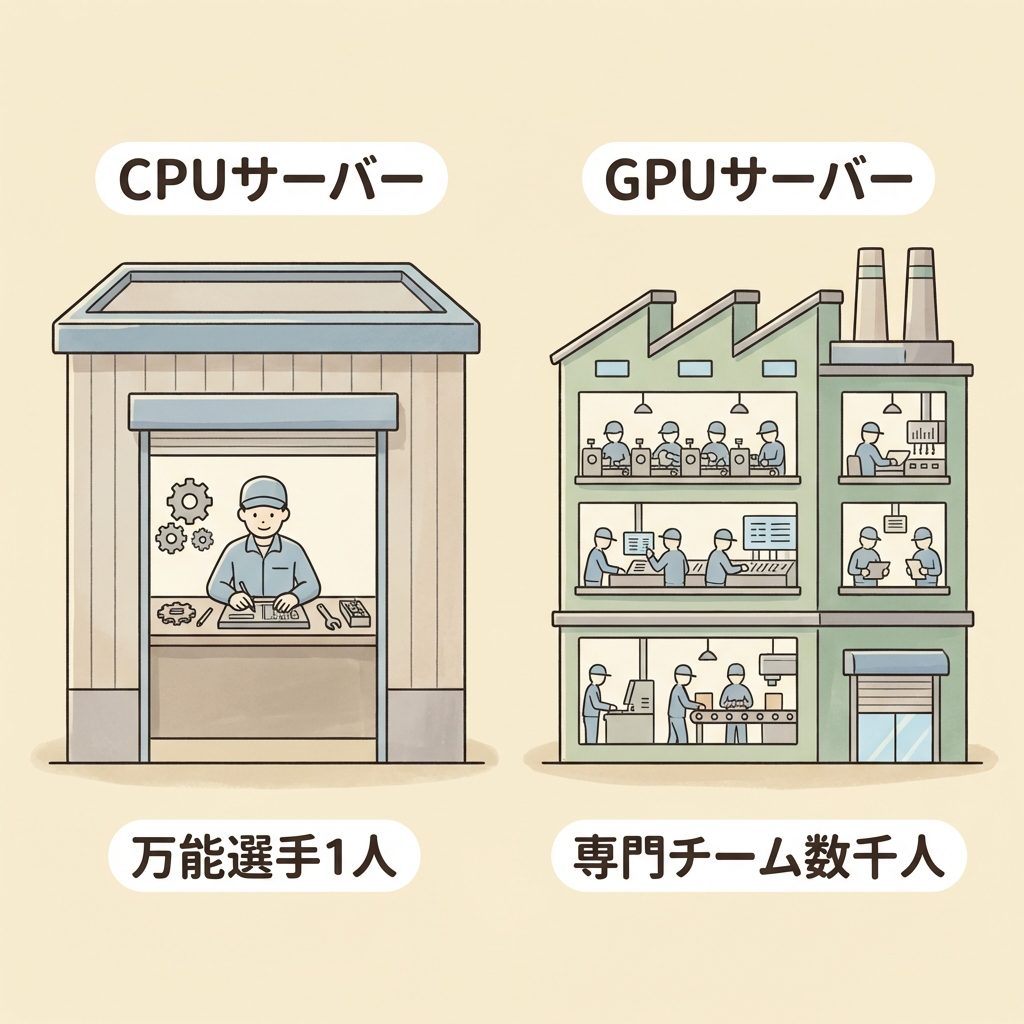
普通のサーバー(CPUサーバー)
いろんな仕事をなんでもこなせる万能選手が、一人で順番に仕事を片付けていく。メール配信、Webサイト表示、データ管理──幅広い仕事に対応できる。
GPUサーバー
同じ作業を一斉にこなす専門チームが数千人規模で配置されている。決まったパターンの計算を超大量にさばくのが得意。AI学習や映像処理に最適。
HPE(ヒューレット・パッカード・エンタープライズ)は、GPUサーバーを「標準のCPUに加えてGPUを備えたサーバーの一種」と定義しています(出典:HPE公式)。ポイントは、GPUサーバーにもCPUは入っているということ。GPUだけで動くわけではなく、CPUが全体の管理を行い、GPUが大量計算を担当するという「役割分担」で成り立っています。
GPUサーバー =「GPUだけのマシン」ではありません。CPUが指揮官、GPUが大量の作業員。この2つが協力して動く仕組みです。CPUなしにGPUは動けませんし、GPUなしにAIの大量計算はできません。
CPUとGPUの「仕事のやり方」はこんなに違う
🧑🍳 料理で例えると、一目でわかる
CPUとGPUの違いは、「仕事のやり方」がまるで違うことに尽きます。性能の高い低いではなく、得意分野が根本的に異なるのです。
料理に例えてみましょう。
CPU = 超一流シェフ 1人
フレンチも和食も中華も、なんでも作れる凄腕。ただし1人なので、注文が100件きたら1つずつ順番にこなすしかない。複雑な料理を高速に仕上げるのは得意だが、「同じ料理を100人前同時に」は苦手。
×数千人
GPU = 同じ料理を作る専門調理師 数千人
1人1人は「おにぎりを握る」しかできない。でも数千人が一斉に握るので、100人前でも1000人前でも一瞬で完成する。「同じ作業を超大量に同時にこなす」のが圧倒的に得意。
📊 スペックで見る違い ── コア数が桁違い
料理の例えを数字に戻しましょう。CPUとGPUで決定的に違うのが「コア」の数です。コアとは、実際に計算を行う処理ユニットのことです。
| 比較項目 | CPU(例:サーバー用) | GPU(例:NVIDIA H100) |
|---|---|---|
| コア数 | 数十個(例:64コア) | 数千〜1万個以上(例:14,592コア) |
| 1コアの能力 | 高い(複雑な処理が得意) | 低い(単純な計算に特化) |
| 得意な処理 | 複雑な判断を順番にこなす (逐次処理) |
同じ計算を大量に同時実行 (並列処理) |
| 例えるなら | 超一流シェフ1人 | 専門調理師 数千人チーム |
CPUのコアが数十個なのに対して、GPUのコアは1万個以上。この桁違いのコア数が、「同じ計算を超大量に同時にこなす」並列処理力を生んでいます。
🤖 なぜAI処理にはGPUが必要なのか?
AIの学習(トレーニング)で何が起きているかというと、大量のデータに対して「同じような計算を何兆回も繰り返す」という処理をしています。
たとえばChatGPTのような大規模言語モデルの学習では、数兆個のパラメータ(数値の重み)を、膨大なテキストデータを使って少しずつ調整していきます。この「少しずつ調整する計算」は、1回1回は単純なのですが、それを数兆回繰り返す必要があるのです。
兆単位で繰り返す
数千個同時実行
数ヶ月→数日に短縮
CPUで行えば数ヶ月かかるAI学習が、GPUを数千台並べることで数日〜数週間に短縮できます。これが「AIにはGPUが不可欠」と言われる理由です。GPUはもともとゲームの3D映像描画のために生まれたチップですが、その並列処理能力がAIの計算にぴったりだったのです(出典:デロイト トーマツ)。

一般サーバー(CPUサーバー)とGPUサーバーの構成比較
🔧 中身がまるで違う ── 7つの観点で比較
見た目はどちらもラックに収まる箱型ですが、中身はまったくの別モノです。以下の表で、主要な構成要素を一気に比較してみましょう。
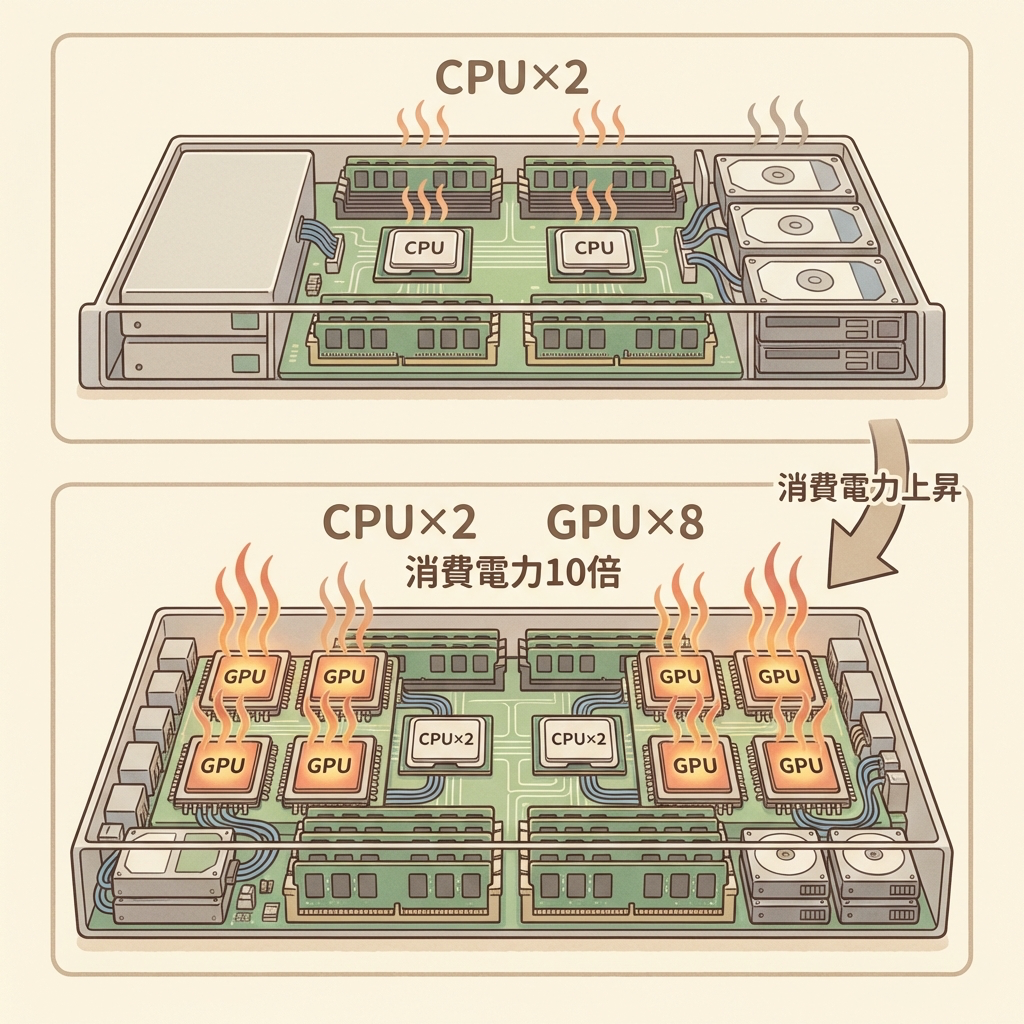
| 構成要素 | CPUサーバー(一般サーバー) | GPUサーバー |
|---|---|---|
| 主な処理チップ | CPU 1〜2基 | CPU 1〜2基 + GPU 4〜8基 |
| GPU搭載数 | なし or 1基(補助的) | 4〜8基(高密度モデルはさらに多い) |
| メモリ(RAM) | 数十〜数百GB | 数百GB(CPU用)+ GPU専用メモリ(HBM)数百GB |
| 消費電力 | 300〜800W 程度 | 3,000〜10,000W(3〜10kW) |
| GPU間接続 | 不要 | NVLinkなど超高速接続が必須 |
| 冷却方式 | 空冷(ファン)で十分 | 空冷 or 液冷が必要(高密度の場合) |
| 主な用途 | Web/メール/DB/業務システム | AI学習・推論、3D処理、科学計算 |
| 価格帯 | 数十万〜数百万円 | 数百万〜数千万円(GPU単体で数百万円) |
🏗️ 構成イメージ ── 「中身のレイアウト」が根本的に異なる
2つのサーバーの内部構成を、簡略化したイメージで見てみましょう。
🖥️ CPUサーバーの内部構成(イメージ)
×1〜2基
数十〜数百GB
SSD/HDD
ネットワーク
構成がシンプル。CPU中心に、メモリとストレージが並ぶ。消費電力:300〜800W程度
🏭 GPUサーバーの内部構成(イメージ)
×1〜2基
数百GB
NVMe SSD
高速NW
GPU×8基がサーバー内の主役。消費電力:5,000〜10,000W(5〜10kW)
見ての通り、GPUサーバーでは内部スペースの大部分をGPUが占めています。NVIDIA DGX H100のような代表的なGPUサーバーは、H100 GPU×8基を搭載し、最大消費電力は約10.2kW(10,200W)に達します(出典:Uvation)。家庭用エアコン3〜4台を同時にフル運転しているのと同程度の電力です。
「GPUサーバーは、普通のサーバーにGPUを後付けしたもの」と思われがちですが、実際は基板設計・電源容量・冷却機構・GPU間の高速接続まで、サーバー全体がGPUを前提に設計されています。「後からGPUを差すだけ」では性能を引き出せません。
「AIサーバー」と「GPUサーバー」は何が違うのか?
🔍 結論:技術的にはほぼ同義。ただし「視点」が違う
「GPUサーバー」と「AIサーバー」──この2つの言葉を目にして、「結局、同じもの? 違うもの?」と混乱する方は多いです。結論から言えば、技術的にはほぼ同じものです。ただし、名前を付ける「視点」が異なります。
GPUサーバー
ハードウェア視点の呼び方。「GPUを搭載したサーバー」という構成上の特徴に注目した名称。AI以外にも、3Dレンダリングや科学計算にも使われる。
AIサーバー
用途視点の呼び方。「AI処理に特化したサーバー」という目的に注目した名称。GPU搭載が前提だが、ソフトウェアやネットワーク最適化も含む概念。
TD SYNNEX社の解説では、「AIサーバーは、GPUサーバーとほぼ同義ですが、よりAI処理に特化して最適化したサーバーを指します」と説明されています(出典:TD SYNNEX)。
もう少し厳密に言えば、AIサーバーにはGPU以外の「AIアクセラレーター」(GoogleのTPU、FPGAなど)を搭載するケースもあります。つまり、AIサーバーの方がGPUサーバーより少し広い概念です。ただし現実の市場では、AIサーバーの大半がNVIDIA GPUを搭載しているため、「AIサーバー ≒ GPUサーバー」と考えてほぼ問題ありません。
| 比較項目 | GPUサーバー | AIサーバー |
|---|---|---|
| 名前の視点 | ハードウェア構成 | 用途・目的 |
| 搭載チップ | GPU(NVIDIAなど) | GPU、TPU、FPGA等の AIアクセラレーター全般 |
| 用途 | AI、3D、科学計算など幅広い | AI処理(学習・推論)に特化 |
| 実態 | 現実にはほぼ同じもの(市場の大半がNVIDIA GPU搭載) | |
この記事では、ハードウェアの構成や物理的な特徴を語るときは「GPUサーバー」、AI処理の文脈で語るときは「AIサーバー」と使い分けます。どちらもほぼ同じものを指していると思っていただいて大丈夫です。
GPUの消費電力はどれくらい? ── 世代ごとに急増している
📈 GPU1枚の消費電力が「電気ストーブ1台分」に
GPUサーバーを理解するうえで、絶対に押さえておきたいのが「GPU1枚あたりの消費電力がどんどん増えている」という事実です。NVIDIAのデータセンター向けGPUの消費電力(TDP)の推移を見てみましょう。
| GPU世代 | 消費電力(TDP) | 身近な例え | 登場時期 |
|---|---|---|---|
| A100 | 400W | ドライヤー弱風 | 2020年 |
| H100 | 700W | 電子レンジ運転中 | 2022年 |
| H200 | 700W | 同上(メモリ強化版) | 2024年 |
| B200 | 1,000W | 電気ストーブ1台 | 2024年 |
※TDP=Thermal Design Power(熱設計電力)。チップが最大負荷時に消費する電力の目安。
出典:各世代の仕様は NVIDIA H200公式、NVIDIA Blackwell発表より
A100の400Wから、最新のB200は1,000W。わずか4年で消費電力が2.5倍になっています。GPU1枚で電気ストーブ1台分──これがGPUサーバーに8枚搭載されるのですから、1台のサーバーで「電気ストーブ8台をフル稼働」しているのと同じ状態です。
🔥 GPU×8基 = 1台で10kW超。サーバー1台でこの電力
具体的に計算してみましょう。NVIDIA DGX H100(H100 GPU×8基搭載のサーバー)の最大消費電力は約10.2kWです。これは一般家庭の約3世帯分の電力に相当します。サーバー1台で3世帯分。これが数百〜数千台集まるのがAIデータセンターです。
投資家:GPUの世代が進むたびに消費電力が増大しています。これは「電力設備」「冷却技術」「電力効率化」関連企業に、継続的な需要が生まれることを意味します。GPU世代交代のたびに、インフラ投資の波が来るのです。
学生:AIの進化は「アルゴリズムの進歩」だけでは語れません。電力工学・熱工学の知識が、AI時代においてますます重要になっています。
技術者:受変電、冷却、電力設備の設計・運用スキルは、GPUサーバーの消費電力が増えるほど需要が高まります。あなたの専門知識は時代遅れどころか、最前線で求められています。

なぜGPUサーバーは「発熱の怪物」になるのか?
🌡️ 電力の大部分は「熱」に変わる
GPUサーバーの消費電力が大きいことは前章で見ました。では、その電力はどこへ行くのか? 答えはシンプルです──消費された電力の大部分は「熱」に変わります。
これは物理法則です。半導体チップが電気エネルギーを使って計算すると、その過程でエネルギーの一部が熱として放出されます。GPUは数千のコアが全力で計算を続けるので、発熱量も桁違いになるのです。
わかりやすい比喩で考えてみましょう。
CPUサーバーの発熱
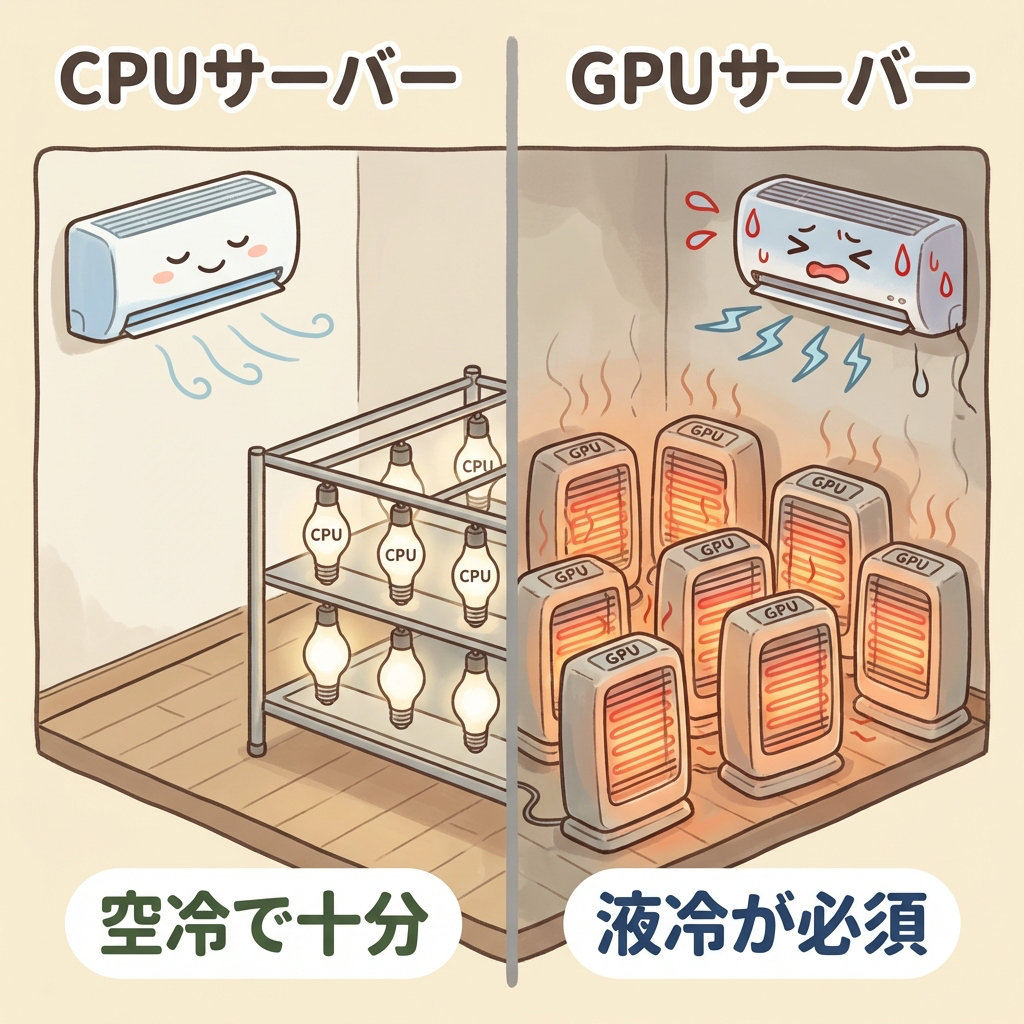
6畳の部屋に白熱電球が数個ある状態。少し暖かいけど、エアコンで十分対処できる。
GPUサーバーの発熱
同じ6畳の部屋に電気ストーブが8台。エアコンでは間に合わない。水冷パイプや冷却液でチップを直接冷やさないと、温度が上がりすぎて壊れてしまう。
🧊 空冷の限界 → 液冷が不可欠に
従来のデータセンターでは、サーバーの冷却は「空冷」が主流でした。強力なエアコンでサーバールーム全体に冷たい空気を送り込む方式です。
しかし、空冷で対処できるのはラックあたり20kW程度が限界とされています(出典:日経クロステック)。GPUサーバーを数台詰め込んだラックは50kW〜120kWに達するため、空冷ではまったく追いつきません。
そこで必要になるのが「液冷」です。水や特殊な冷却液をパイプでチップ直近まで送り、熱を直接奪う方式です。液体は空気に比べて熱伝導率が格段に高いため、高密度なGPUサーバーの冷却に対応できます。
50〜120kW
20kWが限界
直接冷やす
「冷却方式の変化」は単なる技術トレンドではありません。GPUサーバーの消費電力が上がったことによる物理的な必然です。GPUの性能が上がる → 消費電力が上がる → 発熱が増える → 空冷では間に合わない → 液冷が必要になる。この因果関係を押さえれば、AIインフラの構造が一本の線でつながります。
GPUサーバーはデータセンターの設計をどう変えるのか?
🏗️ 「建物」から変えないと、GPUサーバーは置けない
ここまで読んでいただければ、GPUサーバーが「普通のサーバーの強化版」ではないことがおわかりいただけたと思います。消費電力も発熱もケタ違い。これはつまり、GPUサーバーを収容するデータセンターの設計そのものが変わるということです。
家に例えましょう。普通のサーバーが「一般家庭の電化製品」だとすると、GPUサーバーは「業務用の製造設備」です。業務用のオーブンや大型プレス機を家に入れようとしたら、電気の契約を変えて、配線を太くして、排熱ダクトを設置して、床の補強もしなければなりません。同じ「建物に機器を入れる」でも、対応すべきことがまったく違うのです。
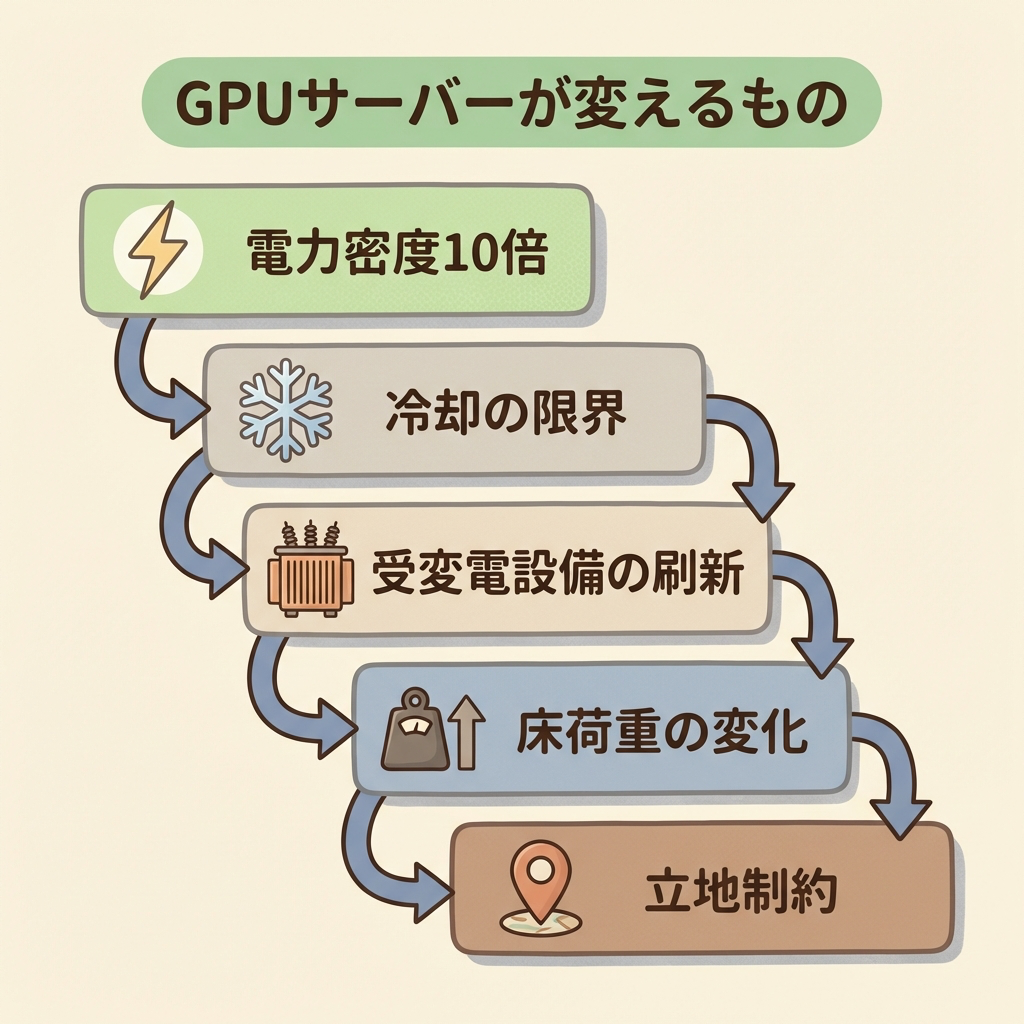
🔗 GPUサーバーがデータセンターに与える影響 ── 5つの連鎖
従来のデータセンターでは1ラックあたり5〜10kWが標準的でした。GPUサーバーを搭載すると50〜120kWに。同じ建物面積でも必要な電力が10倍以上に膨らみます。(出典:NVIDIA GB200 NVL72)
空冷→液冷への移行が必要に。配管設備、防水処理、冷却液の管理設備など、建物のインフラから作り直す必要があります。
数百MW〜GW級の電力を受け入れるには、通常の受変電設備では足りません。専用の変電所レベルの設備が必要になります。
GPUサーバーはCPUサーバーより重く、液冷設備も加わるため、床の耐荷重設計が変わります。既存の建物では対応できないケースも多いです。
莫大な電力を確保できる場所は限られます。日本では電力系統への接続(送電網との接続)が最大のボトルネックになっています。
| 比較項目 | 従来型DC(CPUサーバー中心) | AI対応DC(GPUサーバー中心) |
|---|---|---|
| ラック電力密度 | 5〜10kW | 50〜120kW |
| 冷却方式 | 空冷(エアコン) | 液冷(水冷・液浸) |
| 電力設備 | 一般的な受変電設備 | 専用変電所レベル |
| ネットワーク | 数Gbps〜数十Gbps | 数百Gbps〜Tbps級 |
| 施設全体の電力 | 数MW〜数十MW | 数百MW〜GW級 |
「既存のデータセンターにGPUサーバーを入れればAI対応できる」と思われがちですが、ほとんどの場合それは困難です。ラックあたりの電力密度が10倍以上異なるため、冷却・電力・建物の耐荷重など、施設の根幹から設計し直す必要があるのです(出典:@IT)。
よくある誤解を整理する
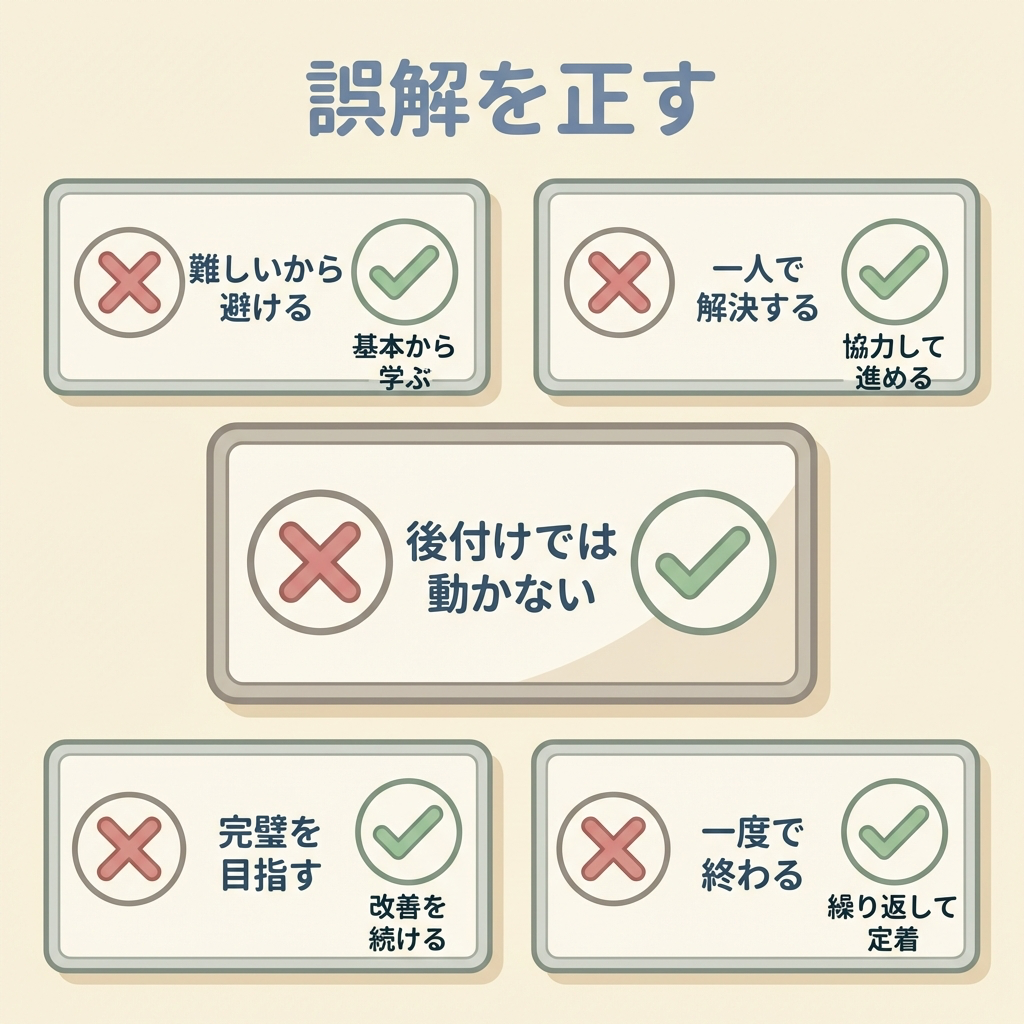
❌ 誤解と ✅ 実際
| ❌ よくある誤解 | ✅ 実際はこう |
|---|---|
| 「GPUサーバーはGPUだけで動く」 | CPUが全体の管理や前処理を担当し、GPUが大量計算を実行する役割分担制。CPUなしにGPUは動けない。 |
| 「普通のサーバーにGPUを後付けすればいい」 | GPUサーバーは基板設計・電源・冷却・GPU間接続が専用設計。後付けではGPUの性能を引き出せない。 |
| 「GPUサーバーとAIサーバーは別物」 | 技術的にはほぼ同じもの。視点の違い(ハードウェア構成 vs 用途)で呼び方が変わるだけ。 |
| 「GPUは性能が高い=CPUの上位互換」 | GPUは並列処理に特化しているが、複雑な逐次処理はCPUの方が得意。上位・下位の関係ではなく、得意分野が違う。 |
| 「既存データセンターにGPUサーバーを入れればAI対応」 | 電力密度が10倍以上異なるため、冷却・電力・床耐荷重から設計し直しが必要。多くの場合、新築の方が現実的。 |
あなたにとっての意味 ── 投資家・学生・技術者の視点
📌 GPUサーバーの理解が、次の一歩を変える
GPUサーバーの構造を理解したことで、「AIの話」が「アルゴリズムの話」だけではないことが見えてきたのではないでしょうか。ここから先、あなたの立場ごとに「何を考え、何を学ぶべきか」を整理します。
AI関連銘柄を見るとき、「NVIDIA(GPU)」だけに目が行きがちです。しかし、GPUサーバーの構造を理解すれば、GPU以外にも巨大な投資先が見えてきます。具体的には、GPU間をつなぐ高速接続技術(NVLink等)、GPUの性能を引き出すHBMメモリ(SK Hynix、Micron等)、液冷・空調設備、受変電設備、データセンター建設──GPUサーバー1台を動かすために、膨大なサプライチェーンが動いています。ボトルネックの場所が、次の成長領域を示しています。
「AIの時代 = 情報系だけが活躍」ではありません。GPUサーバーの構造を見れば、電気工学(電力設計・受変電)、機械工学(冷却・熱交換)、材料工学(半導体パッケージ・冷却素材)、建築設備工学(データセンター設計)がAI産業の最前線に直結していることがわかります。自分の専門分野とAIのつながりを、GPUサーバーという「接点」から探ってみてください。
GPUサーバーの消費電力と発熱を扱えるのは、電気・冷却・設備の実務を知る技術者だけです。AIデータセンターの建設・運用では、電気主任技術者、空調設備の設計者、施工管理技士などの人材が最も不足しています。「自分の仕事はAI時代に不要になるのでは?」と不安に感じる必要はまったくありません。むしろ、あなたの専門がなければAIのインフラは動かないのです。

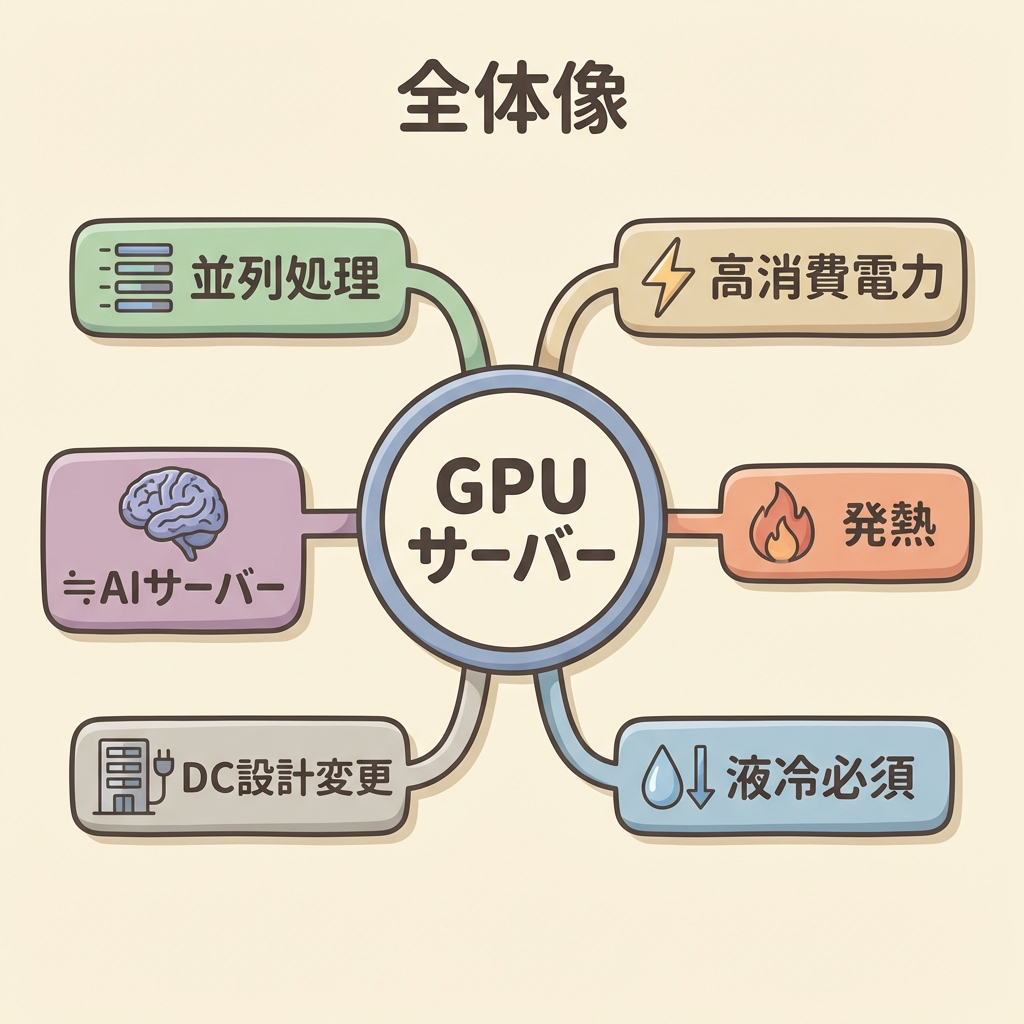
まとめ:GPUサーバーの全体像
① GPUサーバーとは:GPUを複数搭載し、大量の並列計算を高速に実行できるサーバー。CPUが管理役、GPUが計算の主力。
② CPUとGPUの違い:CPUは「複雑な仕事を順番にこなすベテラン1人」、GPUは「同じ作業を数千人が一斉にこなすチーム」。得意分野が根本的に異なる。
③ AIサーバーとの関係:GPUサーバー=ハードウェア視点の名前、AIサーバー=用途視点の名前。技術的にはほぼ同義。
④ 消費電力:GPUサーバー1台で3,000〜10,000W。最新GPU(B200)は1枚で1,000W。世代ごとに消費電力は増加の一途。
⑤ 発熱問題:消費電力の大部分が熱に変わる。空冷(ラック20kWが限界)では対処不能。液冷が不可欠。
⑥ データセンターへの影響:GPUサーバーの導入は、冷却方式・電力設備・床荷重・立地制約まで、施設全体の設計を根本から変える。
結局こういうことです。GPUサーバーは「普通のサーバーの強化版」ではありません。サーバーの中身が変わることで、ラック設計が変わり、冷却方式が変わり、電力設備が変わり、データセンターの建物そのものが変わる。GPUサーバーの理解は、AIインフラの全体像を理解するための「最初の1ピース」です。
❓ よくある質問(FAQ)

📖 【完全図解】AIデータセンターとは?従来型との違いと構造を解説 →
この記事は上記ロードマップの一部です。AIデータセンターの全体像から学びたい方はこちらからどうぞ。
📚 次に読むべき記事
GPUサーバーが大量に集まる場所が「AIデータセンター」。全体像と因果の連鎖を理解するピラー記事です。
GPUサーバーの発熱に対処する冷却技術の違いを深掘りする記事です。
GPUサーバーの性能は「GPU単体」だけでは決まりません。メモリの仕組みを理解しましょう。
🗺️ 学習ロードマップ上の位置づけ
GPUサーバーとは?(この記事)
空冷 vs 液冷(冷却技術の比較)── 公開準備中
HBMとは?(メモリ技術)── 公開準備中

コメント