「HBM」という言葉、AIやGPUの話題でよく目にするようになりましたよね。でも、こんなふうに感じていませんか?
- HBMって何? DRAMやGDDRと何が違うの?
- 「高帯域幅」って、具体的にどういう意味?
- SK HynixがNVIDIAに重要と聞くけど、なぜそんなに特別なのかピンとこない
- 投資や就職を考える前に、まずHBMの全体像を整理したい
- HBMの定義と、DDR・GDDRとの本質的な違い
- 3D積層・TSV・インターポーザーという仕組みの意味
- なぜGPUにHBMが必要なのか(メモリウォール問題)
- HBM1〜HBM3Eまでの世代進化と性能変化
- SK Hynix・Samsung・Micronの市場構造
- 投資家・学生それぞれにとっての意味
HBMとは、複数のDRAMチップを縦に積み重ねてGPUの隣に配置した、AI計算専用の高速メモリです。AIの学習・推論では、GPUが膨大なデータを瞬時に読み書きする必要があります。ここで「メモリの速度が演算に追いつかない」というボトルネックが生まれます。HBMはこの問題を、「縦に積んで幅を広げ、GPUの隣に置く」という発想で解決しました。NVIDIA H100・H200が世界最高クラスのAI性能を誇る理由のひとつは、HBMなしに語れません。
HBMとは? まず「3つの言葉」で理解する
📖 HBM = High Bandwidth Memory(高帯域幅メモリ)
HBMとは High Bandwidth Memory(ハイ・バンドウィドス・メモリ) の略で、日本語では「高帯域幅メモリ」と呼ばれます。AIや高性能コンピューティング向けのGPUに搭載される、特殊なメモリ規格です。
1秒間に転送できるデータの量(GB/s または TB/s)。「データが通る道路の幅」に相当する。帯域幅が広いほど、同じ時間に多くのデータを運べる。GPUがAI計算をするとき、メモリからデータを読み込む速度がこの帯域幅で決まる。

なぜGPUにHBMが必要なのか?「メモリウォール」という壁
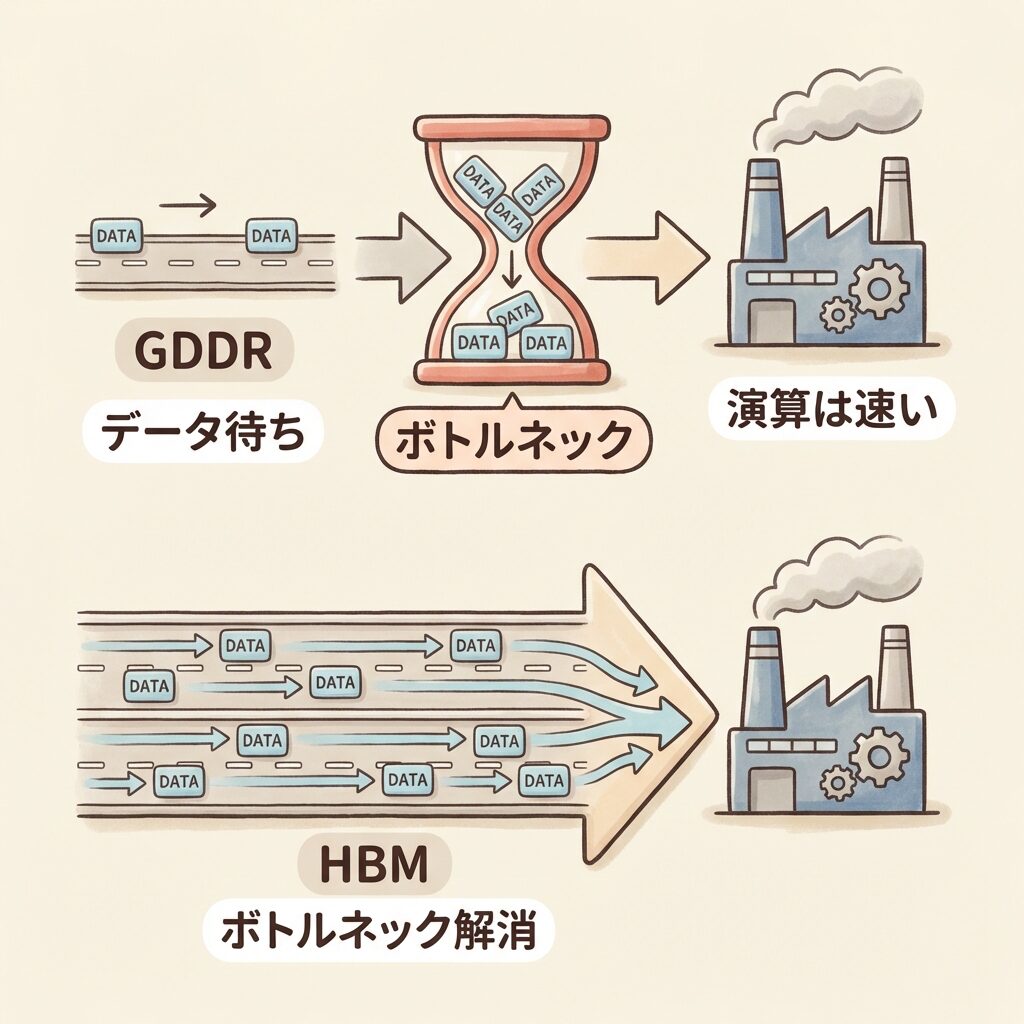
🧱 GPUの実力を封じ込める「データ待ち」問題
GPUの演算速度とメモリの転送速度の差が拡大し、「メモリが演算の足を引っ張る」状態のこと。演算装置がいくら速くても、データが届かなければその性能を活かせない。AI時代になってこの問題が特に深刻になった。
GPUは「毎分1万個のハンバーガーを作れる超高速工場」です。でも、食材を運ぶトラックが細い道路を1台で走るだけなら、工場はほとんどの時間を「食材待ち」に費やします。いくら工場が速くても、食材の搬入速度がボトルネックになるのです。HBMとは、その細道を「何十車線もある超広い高速道路」に変えるようなものです。
AIモデルが大規模化するにつれて、GPUが処理するデータ量が爆発的に増加。
従来のGDDR・DDRはバス幅が狭く、帯域幅が演算速度の向上に追いつかない状況に。
GPUが演算できる時間より「データ待ち」の時間が長くなり、GPUの実性能が引き出せない。
HBMの導入。1024bit超の超広バスでデータ供給速度を根本から引き上げ、GPUの演算性能を最大限に引き出す。
HBMの仕組み:3D積層・TSV・インターポーザーを図解
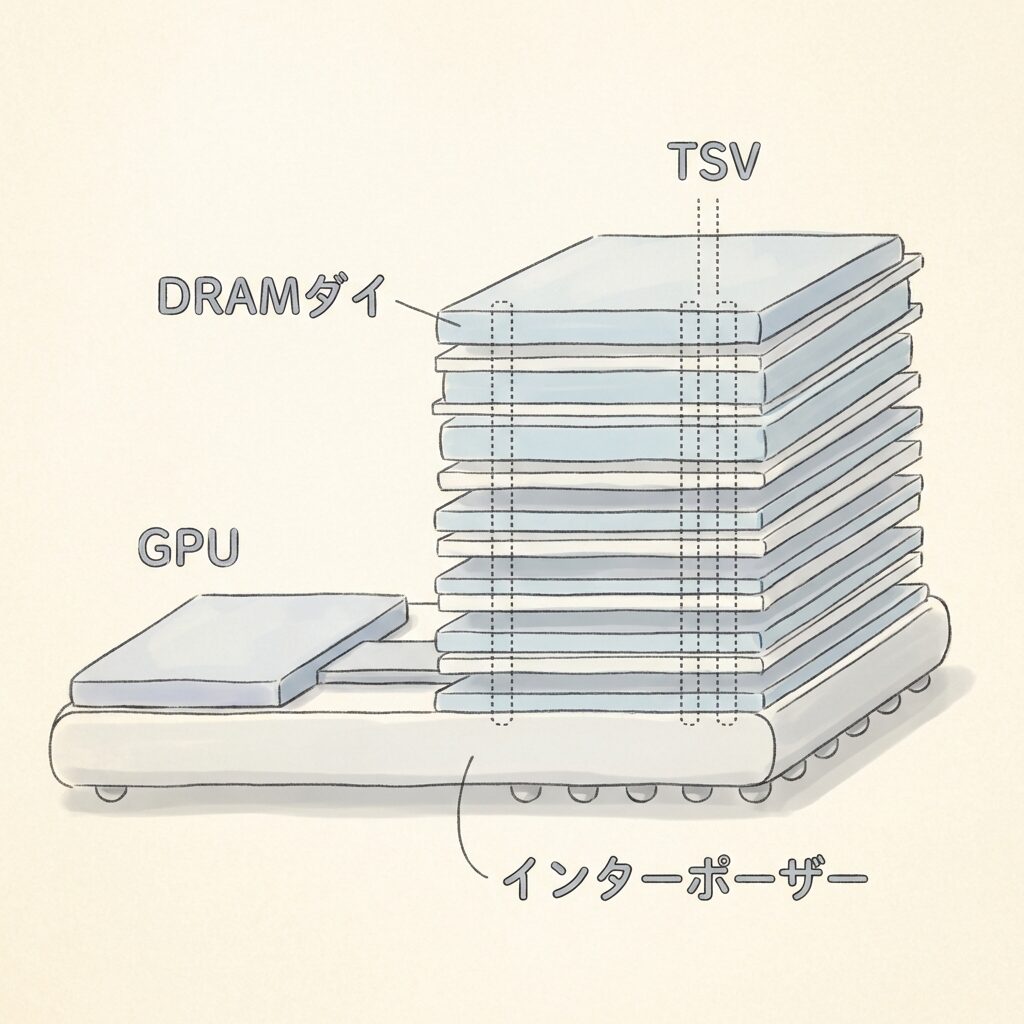
🔬 「縦に重ねて、貫通させて、GPUの隣に置く」が基本構造
HBMの仕組みは、3つのキーワードを順に押さえると自然に理解できます。
複数枚のDRAMダイ(チップ)を薄く削り、縦方向に積み重ねます。例えばHBM3Eでは8〜12枚のダイを積層。平面に並べると広い面積が必要なところを、縦積みで省スペース・高密度化します。
積み重ねたダイ同士をTSVというシリコン貫通電極で縦に接続します。1スタックに数千〜数万本のTSVが存在し、これにより1024bit以上の超広いバス幅を確保して圧倒的な帯域幅を生み出します。
シリコンチップを貫通する超微細な電極。積み重ねたチップ間を直接つなぐために使う。従来のワイヤボンディング(金線で横につなぐ方式)よりはるかに多くの信号を高速に伝えられる。
HBMのスタックをGPUダイとインターポーザー(中間接続基板)の上に並べて搭載します。GPU〜HBM間の配線距離を極限まで縮め、低遅延・低消費電力を実現。このパッケージ全体を「2.5D実装」と呼びます。
GPUとHBMを同じ基板に乗せるための「中間プラットフォーム」。シリコン製が主流で、TSMCのCoWoS(Chip on Wafer on Substrate)技術が代表例。超微細な配線を大量に引けるため、GPU〜HBM間の信号を超高速で通せる。
| 構成要素 | 役割 | ポイント |
|---|---|---|
| DRAMダイ(複数枚) | メモリ本体 | 8〜12枚を縦積み。1スタック=1 HBMユニット |
| TSV(貫通電極) | 層間接続 | 数千〜数万本で1024bit幅を確保。帯域幅の源泉 |
| ベースダイ | 制御・I/O | スタックの最下部。外部との入出力制御を担う |
| インターポーザー | GPU〜HBM接続 | シリコン基板上でGPUと超短距離接続(2.5D実装) |

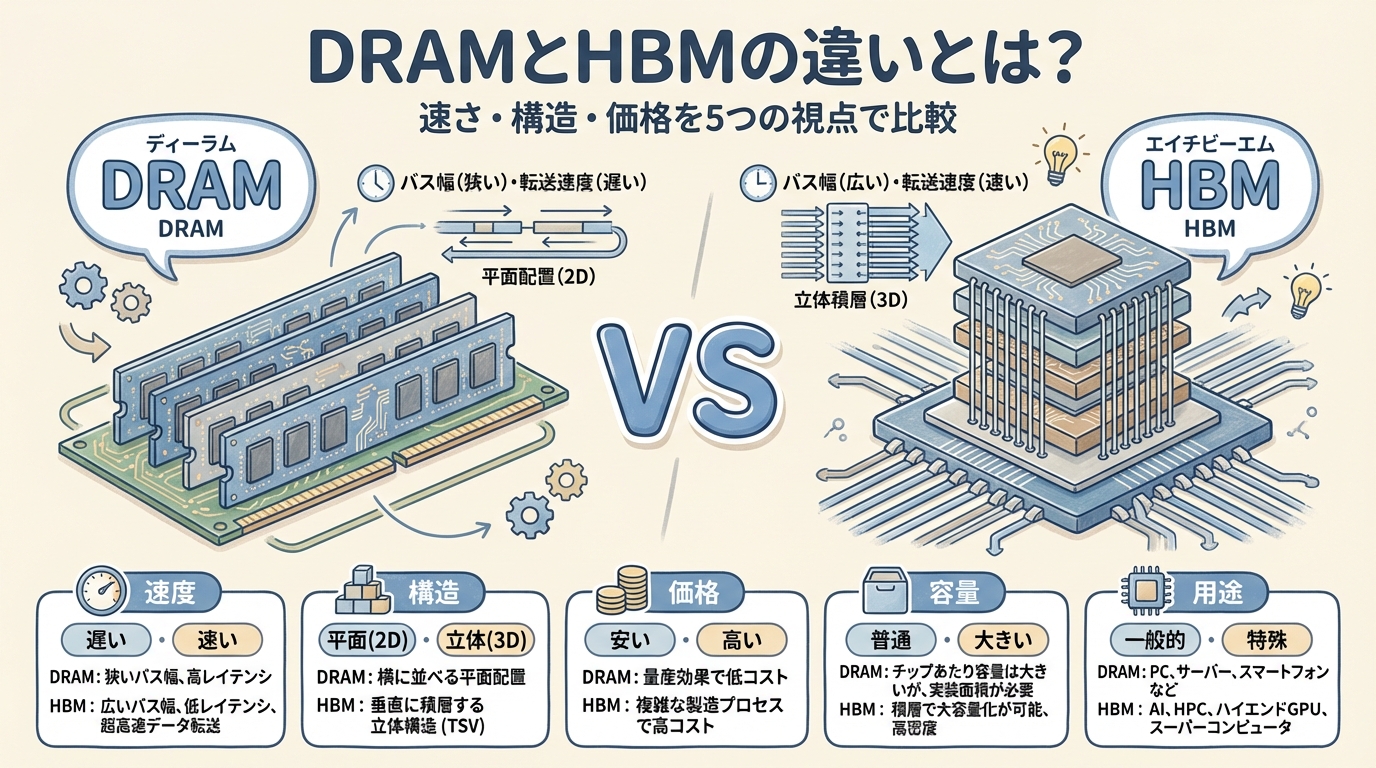
DDR・GDDR・HBMの違いを比較表で整理
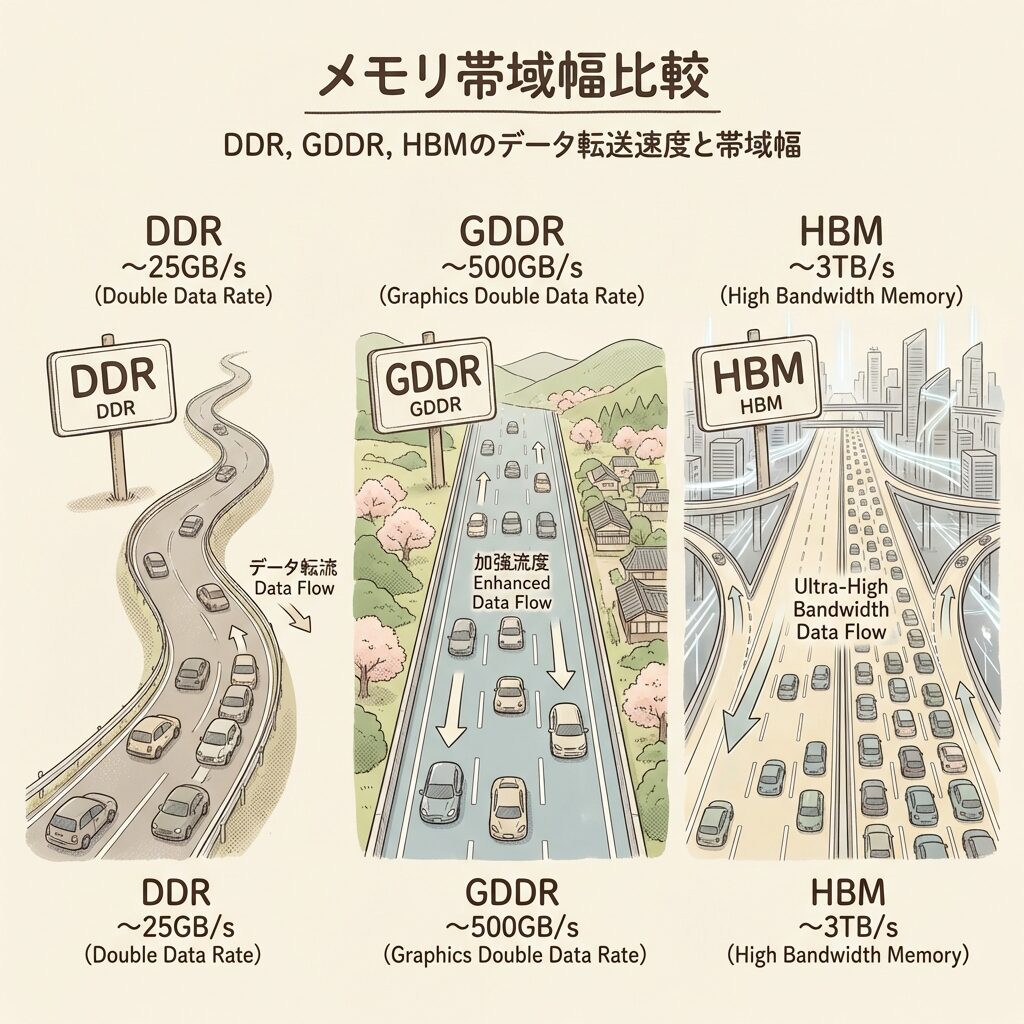
📊 3種類のメモリ:「用途・幅・速度」で見る決定的な差
メモリの世界には大きく3系統あります。それぞれの「立ち位置」を先に理解しておくと、HBMがいかに特殊な存在かが見えてきます。
DDR5
- 用途:CPUのメインメモリ
- バス幅:64 bit
- 帯域幅:〜50 GB/s
- 普及品。PC・サーバーに広く使用
GDDR6X
- 用途:ゲーム向けGPU
- バス幅:192〜384 bit
- 帯域幅:〜500 GB/s(GPU全体)
- 比較的安価。GeForce系に採用
HBM3E
- 用途:AI向けGPU専用
- バス幅:1024 bit(×スタック数)
- 帯域幅:最大4.8 TB/s(H200全体)
- 高価・製造難。H100/H200に採用
| 比較項目 | DDR5 | GDDR6X | HBM3E |
|---|---|---|---|
| 主な用途 | PC・サーバー | ゲームGPU | AIアクセラレータ |
| バス幅 | 64 bit | 192〜384 bit | 1,024 bit ×スタック数 |
| 帯域幅(1ユニット) | 〜50 GB/s | 〜100 GB/s | 〜1.2 TB/s(1スタック) |
| 実装方式 | DIMMスロット | 基板直付け | インターポーザー(2.5D実装) |
| 価格 | 低 | 中 | 非常に高(H100価格の相当部分) |
| 製造難易度 | 低〜中 | 中 | 極めて高(先端パッケージング必須) |
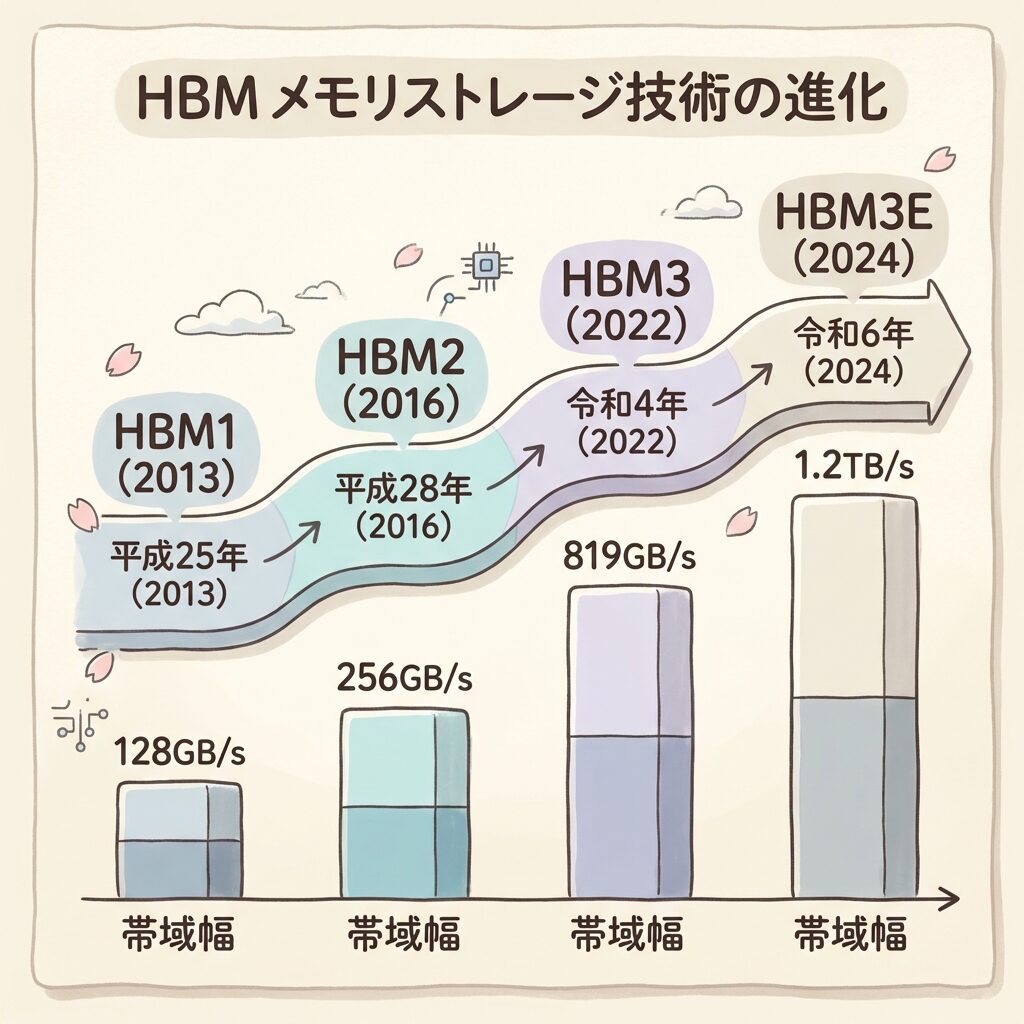
HBMの世代進化:HBM1〜HBM4まで一気に整理
📅 約10年で帯域幅は約10倍に:世代ごとの進化
1スタックあたり
1スタックあたり
1スタックあたり
1スタックあたり
SK HynixがAMDと共同開発。帯域幅128GB/s/スタック。AMD Radeon R9 Fury Xに初採用。「DRAMを縦に積む」という概念を業界に示した記念碑的製品。
帯域幅256GB/s/スタック。NVIDIAのTesla P100(AI研究用GPU)に採用され、AIデータセンター向けGPUの「標準メモリ」としての地位を確立した転換点。
HBM2eで460GB/s、HBM3で819GB/s/スタックへ大幅向上。NVIDIA A100(HBM2e)・H100(HBM3)に採用。ChatGPTブームでHBMへの社会的注目が急上昇。SK Hynixの株価がAI関連銘柄として再評価され始めた時期。
帯域幅1.2TB/s/スタック。NVIDIA H200に採用(6スタック・141GB・総帯域幅4.8TB/s)。SK Hynixが量産で先行し、H200出荷においてNVIDIAとの独占的供給関係を強化。
帯域幅2TB/s超を目標に開発中。ベースダイにロジック機能を統合する設計も検討。NVIDIA Blackwell世代(GB200)のさらなる進化型での採用が見込まれている。
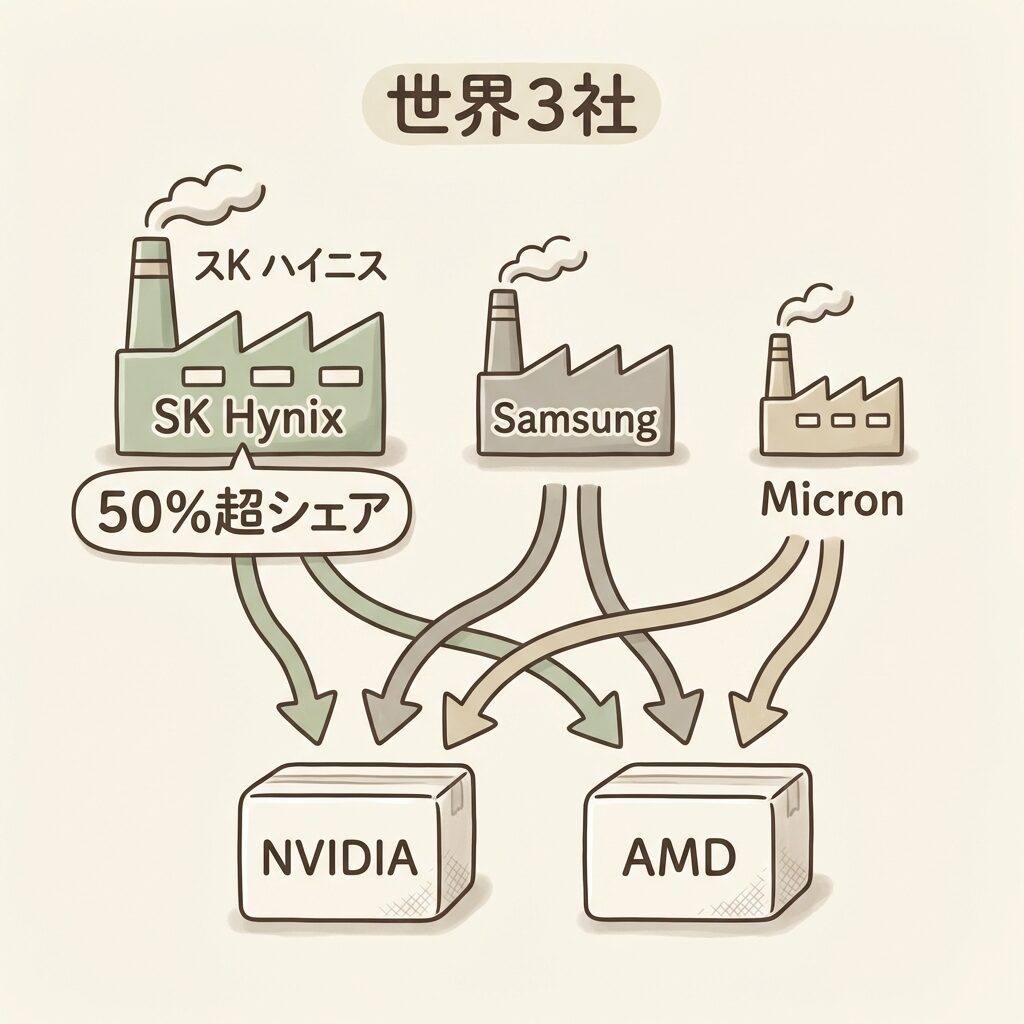
HBMを作れるのは世界3社だけ:市場構造と競争
🏭 極めて高い参入障壁が「3社寡占」を生む理由
HBMの製造は、高度なTSV技術・先端パッケージング・超精密な積層制御が必要で、現在量産できるのは世界でSK Hynix・Samsung・Micronの3社のみです。
HBMは①TSV工程を持つ先端製造ライン、②積層精度を保つ超精密実装技術、③GPUメーカーとの共同設計体制、の3点がそろわないと量産できません。この3点を同時に備えた企業が世界に3社しかない構造が、HBMの高単価と慢性的な供給制約を生んでいます。
製造した製品のうち、品質基準を満たした「使えるもの」の割合。HBMは積層・TSV工程が複雑なため歩留まりが低くなりがち。歩留まりが低いと製造コストが上がり、供給量も減少する。Samsungが先行するSK Hynixに追いつけない主因のひとつ。
投資家・学生・技術者、それぞれにとってのHBMの意味
🎯 あなたの立場から「HBMをどう使うか」
投資家:HBMはAI GPU需要と直結する「川上の希少部品」です。AI関連投資でNVIDIAを見るとき、その背景にはSK HynixのHBM供給があります。HBMメーカーの業績・歩留まり・次世代品の量産タイミングは、AI関連銘柄全体の株価に波及しやすい構造です。「NVIDIAが好調」→「HBM需要が増える」→「SK Hynixが恩恵を受ける」というサプライチェーン上流を意識した視点が有効です。
学生:TSV・先端パッケージング・2.5D/3D実装は、半導体エンジニアとして今後最も需要が高まるスキル領域です。「メモリアーキテクチャ」「チップレット設計」「先端パッケージング」を軸に学ぶと、就職・研究でのキャリアが広がります。情報系だけでなく、電気・材料・精密機械の学生にとっても参入余地が大きい分野です。
技術者:AIサーバーの性能設計を考えるとき、HBMの帯域幅と容量がボトルネックになるかどうかは見落とせない論点です。H100(80GB・3.35TB/s)とH200(141GB・4.8TB/s)の性能差を「単なる世代差」でなく、HBMの容量・帯域幅の差として整理できると、インフラ設計の精度が上がります。
📖 【完全図解】AIデータセンターとは?従来型との違いと構造を解説 →
HBMが必要とされる背景にある「なぜAIデータセンターが特殊なのか」の全体像を確認できます。この記事と合わせて読むと理解が深まります。

HBMについてよくある3つの誤解
HBMはGPUに搭載されるメモリ(記憶装置)です。演算を行うのはGPUダイ(CUDA CoreやTensor Coreを持つ演算チップ)で、HBMは「そのデータを供給・保持する部分」です。GPUとHBMは別々のチップがインターポーザー上で協働する構造です。「GPU=HBM」ではなく、「GPU+HBM=AI計算ユニット」と理解してください。
NVIDIAはGPUダイを設計しますが、HBMを製造しているのはSK Hynix・Samsung・Micronです。NVIDIAはこれらのHBMをTSMCのCoWoS技術で自社GPU基板と接続します。「設計(NVIDIA)・メモリ製造(SK Hynixほか)・パッケージング(TSMC)」という分業構造を押さえることが、AI産業の理解に直結します。
HBMは確かにメモリ帯域という重大なボトルネックを解消します。しかしAIの演算速度は、GPU内のTensor Core数・サーバー間ネットワーク帯域・電力供給・冷却能力など、複数の要素が連鎖しています。HBMは「パズルのひとつの重要ピース」であり、すべての答えではありません。


まとめ:HBMを5点で整理する
① HBMとは:複数のDRAMを縦に積層しTSVで接続した高帯域幅メモリ。AIアクセラレータGPU向けの特殊メモリ規格。
② なぜ必要か:AI計算はデータ量が膨大で、メモリ帯域が「演算速度のボトルネック」になる(メモリウォール問題)。HBMが1024bit超の超広バスでこれを解消する。
③ 仕組み:DRAMを縦積み(3D積層)→TSVで貫通接続→インターポーザーでGPUの隣に近接配置(2.5D実装)。距離を縮め、帯域を広げる。
④ 世代進化:HBM1(128GB/s)→HBM3E(1.2TB/s/スタック)と約10年で約10倍の帯域幅を実現。H100はHBM3、H200はHBM3Eを搭載し、総帯域幅はH200で4.8TB/sに達する。
⑤ 市場構造:製造できるのは世界3社(SK Hynix・Samsung・Micron)のみ。SK Hynixが先行し、NVIDIAとの供給関係が競争優位の源泉。
結局こういうことです。HBMとは「GPUというエンジンに、データを届ける血管」です。エンジンがどれだけ速くても、血管が細ければフル回転できません。HBMはその血管を根本から太くした技術です。そしてその血管を作れる企業は世界に3社しかなく、需要はAIの普及とともに拡大し続けています。AI産業の構造を「表面の製品」ではなく「裏側のコンポーネント」から理解するとき、HBMは外せないピースです。
❓ よくある質問(FAQ)
📚 次に読むべき記事
HBMが必要とされる「AIデータセンターの全体構造」を理解するピラー記事。GPU→発熱→液冷→電力→立地制約という因果の連鎖を把握できます。
HBMを搭載したGPUが、どのようなサーバーに組み込まれてAI計算を担うのか。「GPU→GPUサーバー→AIデータセンター」の接続を理解できます。
HBMを積んだ高密度GPUが発する熱を、どうやって処理するのか。冷却問題はHBMの高電力密度と直結しています。
HBM搭載GPUの「高電力密度」がラック設計にどう影響するか。インフラ視点からHBMの意味をさらに深掘りできます。
📩 記事の更新情報を受け取りたい方へ
新しい記事が公開されたら、Xアカウント @shirasusolo でお知らせします。AIインフラの構造を一緒に学んでいきましょう。
コメント