- 「チップレット」って最近よく聞くけど、結局なんなの?
- モノリシックとチップレットの違いを聞かれても説明できない
- なぜAMDやNVIDIAがチップレットに移行しているのか、構造的に理解したい
- CoWoSや先端パッケージとの関係がわからない
- 投資やキャリアを考える上で、チップレットの重要性を判断できない
- チップレットの定義を30秒で理解──「分割して再統合する」設計思想
- モノリシックとの違いを「歩留まり」の仕組みから構造的に理解
- チップレットの4つのメリットと3つの課題を図解
- AMD・NVIDIAの採用事例で「なぜ今主流なのか」を体感
- UCIe規格──チップレットの「USB規格」が産業を変える理由
- 先端パッケージ(CoWoS等)との「表裏一体」の関係
- 学生・投資家にとっての意味と次の行動
チップレットとは、1つの巨大なチップを機能ごとに小さなダイ(チップ片)に分割し、先端パッケージ技術で再統合する設計手法です。「1枚の巨大チップ」を作るモノリシック設計と比べて、歩留まり(良品率)の向上・コスト削減・異なるプロセスの混載が可能になります。AMDはEPYC/RyzenでCPUチップレット設計の先駆者となり、NVIDIAもBlackwell B200で2つのGPUダイをCoWoS-Lで統合する「チップレットGPU」に進化しました。チップレットの市場規模は2025年の約520億ドルから2030年に約1,570億ドルへ成長する見通しです(出典:MarketsandMarkets)。チップレットは「設計思想」、それを実現するCoWoSなどは「実装技術」──両者はセットで初めて意味を持ちます。
📖 【完全図解】先端パッケージとは?AIチップの「組み立て方」が変わった理由 →
この記事は上記ピラー記事の一部です。先端パッケージの全体像から学びたい方はこちらからどうぞ。
「チップレット」という言葉、AIや半導体のニュースで急に見かけるようになりましたよね。でも「結局何が新しいの?」「モノリシックとどう違うの?」と聞かれると、うまく説明できない──そんな方は少なくありません。
この記事では、チップレットとは何か・なぜ今主流になったのかを、構造とデータで初心者でもわかるように解説します。前回の記事「先端パッケージとは?」で全体地図を掴んだ方にとって、この記事は「チップレットという設計思想」に焦点を当てた深掘り編です。
チップレットとは?──まず定義を30秒で理解する
🧩 「機能ごとに分割して、パッケージで再統合する」設計手法
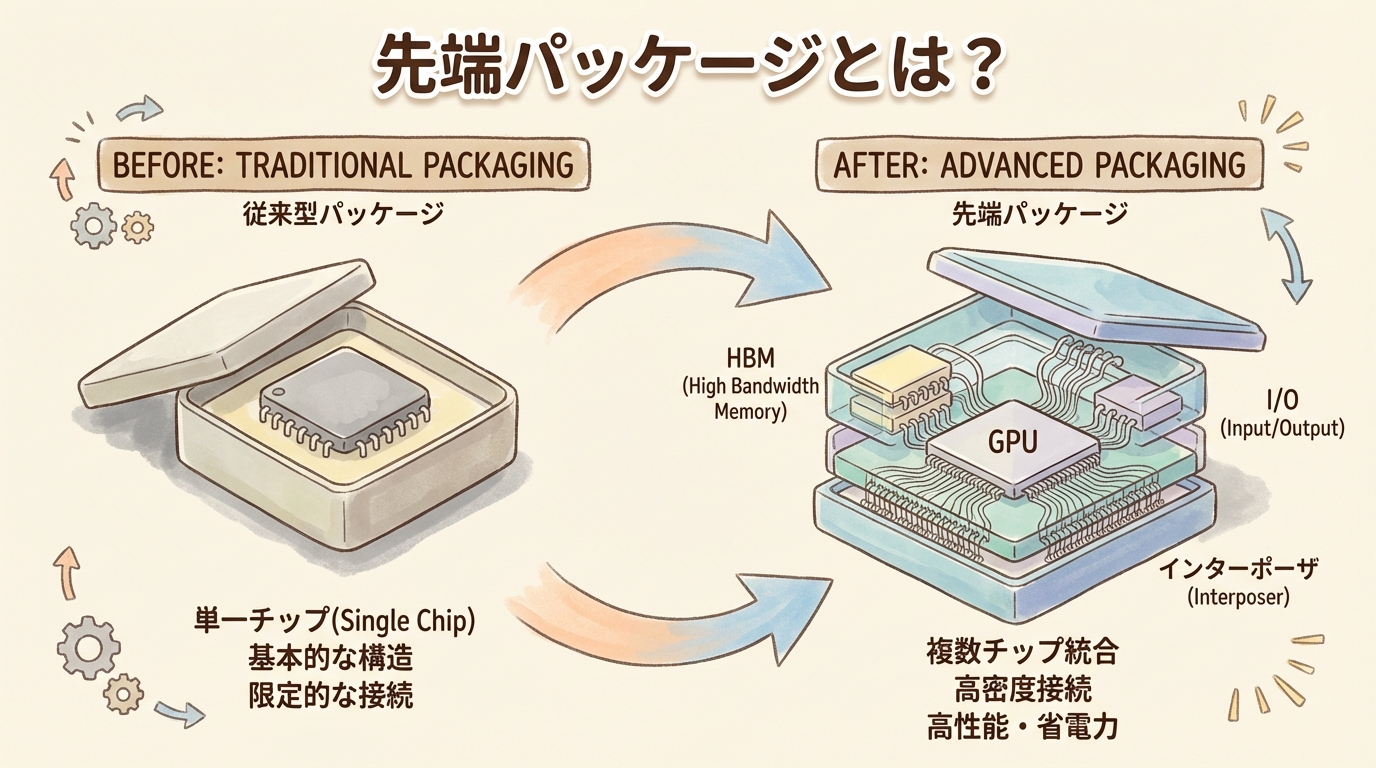
チップレット(chiplet)とは、特定の機能(演算・メモリ制御・入出力など)を担う小さな半導体ダイ(チップ片)のことです。そして「チップレット設計」とは、1つの巨大チップを作る代わりに、機能ごとに分割した小さなチップレットを先端パッケージ技術で1つのパッケージに再統合する設計アプローチを指します。
従来の「モノリシック(一枚岩)設計」では、CPU・GPU・メモリ制御・I/Oなどすべての機能を1枚の大きなシリコンダイに詰め込んでいました。チップレット設計はこの発想を逆転させ、「小さく作って、あとで組み合わせる」ことで性能・コスト・柔軟性を同時に改善します。
モノリシック設計は「1枚の巨大なピザ」。サイズが大きくなるほど焼きムラ(不良)が出やすく、1箇所でも焦げたら全部やり直し。チップレット設計は「小さなピザを何枚か焼いて、大きなプレートに並べる」方式。1枚が焦げても、その1枚だけ作り直せばOK。味の異なるピザ(異なるプロセスで作ったチップ)を組み合わせることもできます。
シリコンウェハーから切り出された、回路が形成された1片のシリコンチップのこと。「チップ」とほぼ同義。チップレットとは、特定機能に特化した小さなダイを指す。
再統合する
パッケージに統合
通信を標準化
・異種混載
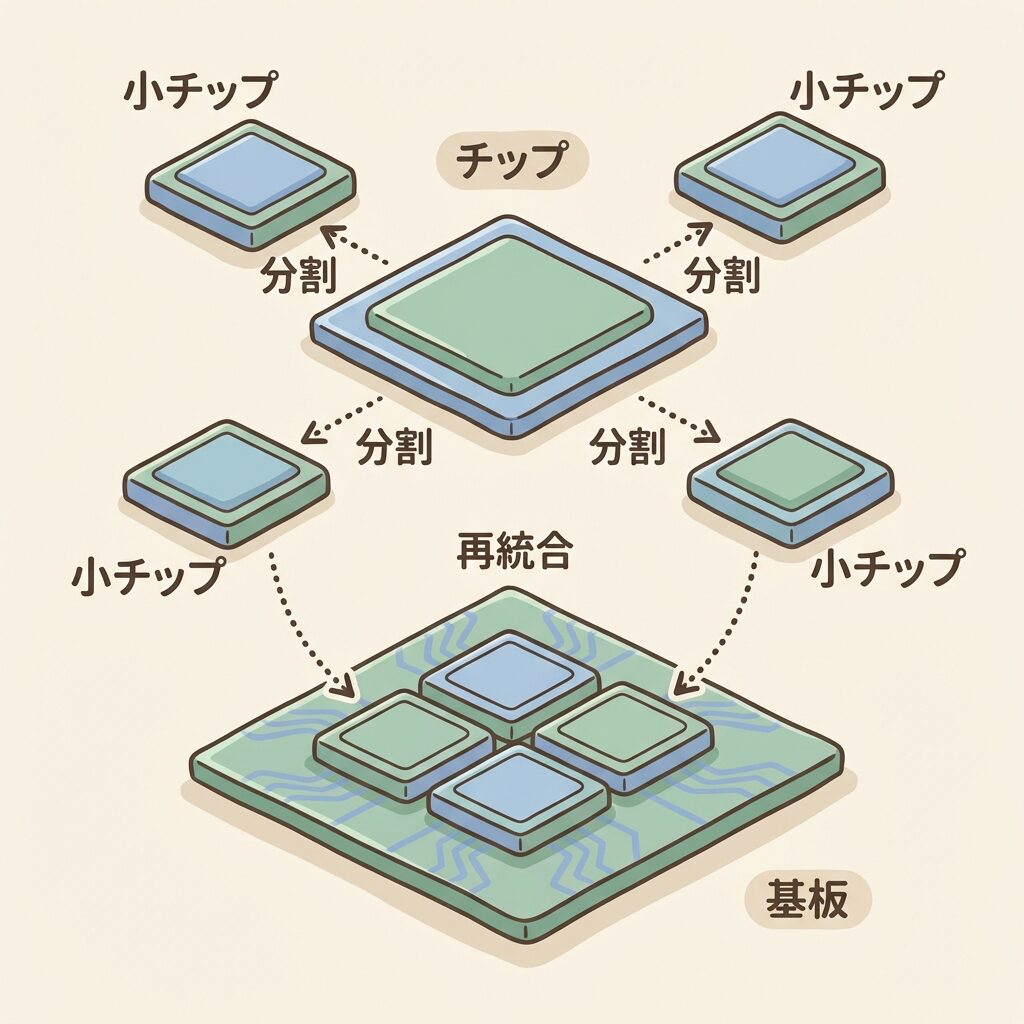
モノリシック vs チップレット──何が違うのか
🔲 「1枚の巨大チップ」と「小さなダイの組み合わせ」
チップレットを理解するには、まず従来の「モノリシック設計」との違いを明確にすることが最短ルートです。比較カードで整理しましょう。
モノリシック設計(従来型)
- 1枚の巨大ダイにすべての機能を集積
- すべて同じプロセスノードで製造(例:全部3nm)
- ダイが大きいほど歩留まりが急低下
- レチクルサイズ(約800mm²)が物理的上限
- チップ内部の通信は超高速・低遅延
チップレット設計(現在の主流)
- 機能ごとに小さなダイに分割して製造
- 各チップレットを最適なプロセスで製造可能(GPU→3nm、I/O→7nm等)
- 小さいダイは歩留まりが高い(コスト削減)
- 先端パッケージで再統合しレチクル制限を超越
- チップレット間通信にインターコネクトが必要(遅延の課題)
「一枚岩」を意味するギリシャ語が語源。半導体では、すべての回路機能を1枚の連続したシリコンダイに集積する設計を指す。NVIDIA H100 GPUダイ(約814mm²)は、モノリシック設計の代表例。
半導体の製造技術の世代を示す数値(例:7nm、5nm、3nm)。数字が小さいほどトランジスタが微細で、性能が高い反面、製造コストも高い。チップレット設計では、高性能が必要な部分だけ最先端プロセスを使い、それ以外は成熟プロセスで製造できる。
| 比較項目 | 🔲 モノリシック | 🧩 チップレット |
|---|---|---|
| ダイ構成 | 1枚の巨大ダイ | 複数の小さなダイ |
| プロセス選択 | 全機能が同一プロセス | 機能ごとに最適化可能 |
| 歩留まり | 大型ダイほど低下 | 小型ダイで高い |
| チップ間遅延 | なし(内部接続) | あり(インターコネクト経由) |
| サイズ上限 | レチクルサイズ(~800mm²) | パッケージ技術次第で拡張可 |
| 設計柔軟性 | 低い(全体を再設計) | 高い(一部だけ変更可能) |
| 代表例 | NVIDIA H100 GPUダイ Apple M4 Ultra |
AMD EPYC(CPU+IOD) NVIDIA B200(2ダイGPU) |

なぜチップレットのほうが安くなるのか──「歩留まり」の構造
📐 ダイが大きいほど「不良品」が増える数学的な理由
チップレットが注目される最大の理由は「コスト」──そしてコストの鍵を握るのが歩留まり(Yield)です。ここを構造的に理解しましょう。
製造した半導体チップのうち、正常に動作する「良品」の割合。歩留まりが高い=良品率が高い=コストが低い。半導体製造の経済性を決める最も重要な指標の1つ。
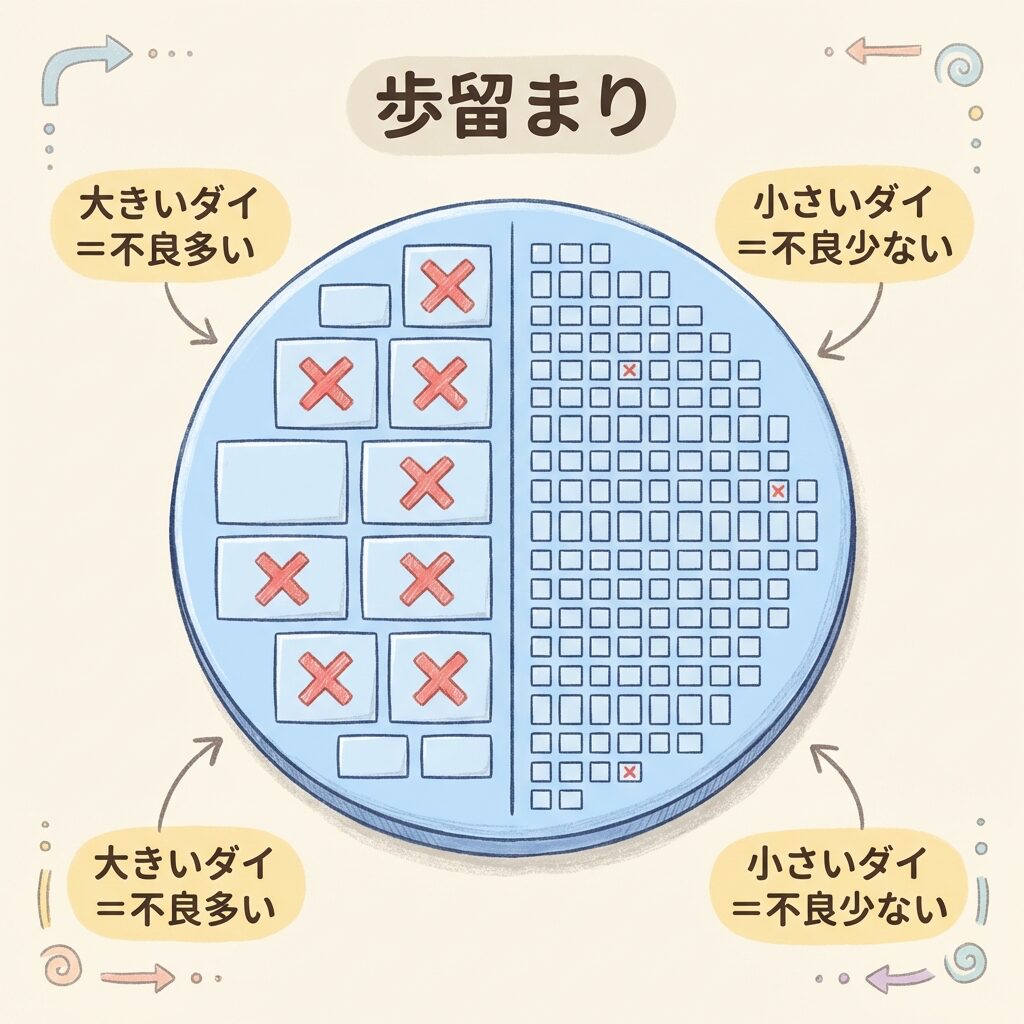
シリコンウェハー上には、製造中にどうしても微小な欠陥が発生します。この欠陥がダイの上に1つでも乗れば、そのダイは不良品です。ここでダイの面積が大きいほど、欠陥に「当たる」確率が高くなる──これが歩留まりの本質です。
雨の中を走ることを想像してください。大きな傘(大きなダイ)ほど雨粒(欠陥)に当たりやすい。小さな傘(小さなチップレット)なら、雨粒が当たる確率はずっと低い。4つの小さな傘を組み合わせれば大きな面積をカバーできますが、1つの傘に雨粒が当たっても、残り3つは無事です。
ウェハー上に大きなダイを並べる。
→ 欠陥がダイに1つでも乗れば全体が不良
→ ダイが大きいほど不良品が増え、コストが上がる
→ 最先端プロセスでは歩留まり50%以下もありうる
同じ総面積でも、小さなダイに分割して製造。
→ 個々のダイの歩留まりが高い
→ 不良ダイだけ廃棄し、良品ダイを組み合わせる
→ 全体のコストが大幅に低減
歩留まりの差をもう少し具体的な数字で見てみましょう。半導体の歩留まりは一般にポアソン分布モデル(Y = e-DA、D=欠陥密度、A=ダイ面積)で近似されます。欠陥密度が同じなら、ダイ面積が2倍になると歩留まりは2乗的に低下します(参考:東北マイクロテック)。
(最先端プロセス想定)
(同プロセス想定)
(16コアCPU比較時)
AMDは、16コアのRyzen 9 3950Xにおいてチップレットアーキテクチャによりモノリシック設計に対して2倍以上のコスト優位性があると公表しています(出典:Overclock3D / AMD)。チップレットの経済的メリットは理論だけでなく、実際の製品で実証済みです。
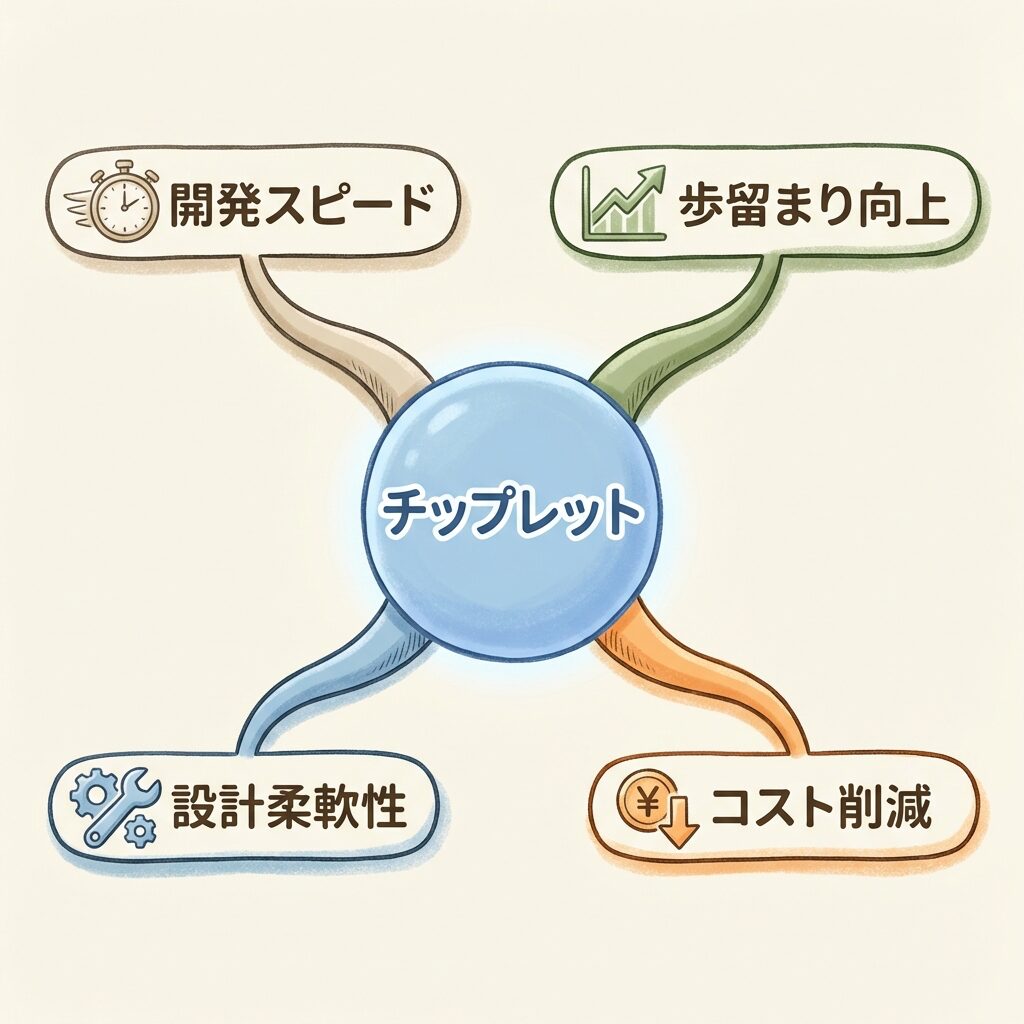
チップレットの4つのメリット──「なぜ今、主流なのか」
✅ 歩留まり・コスト・柔軟性・スピードの4軸で優位
特に②の「プロセスの混載」は、モノリシックでは不可能だった大きな利点です。たとえばAMDのEPYCプロセッサでは、CPUコアのチップレット(CCD)は最先端の5nmプロセスで製造し、I/Oダイ(IOD)はコストの安い6nmプロセスで製造しています。すべてを5nmで作る必要がないため、大幅なコスト削減が可能になります(参考:西進商事)。
異なるプロセスノード・異なる機能・異なるメーカーのチップレットを1つのパッケージに統合する技術思想。チップレット設計の本質であり、「最適な場所に最適な技術を」という考え方。
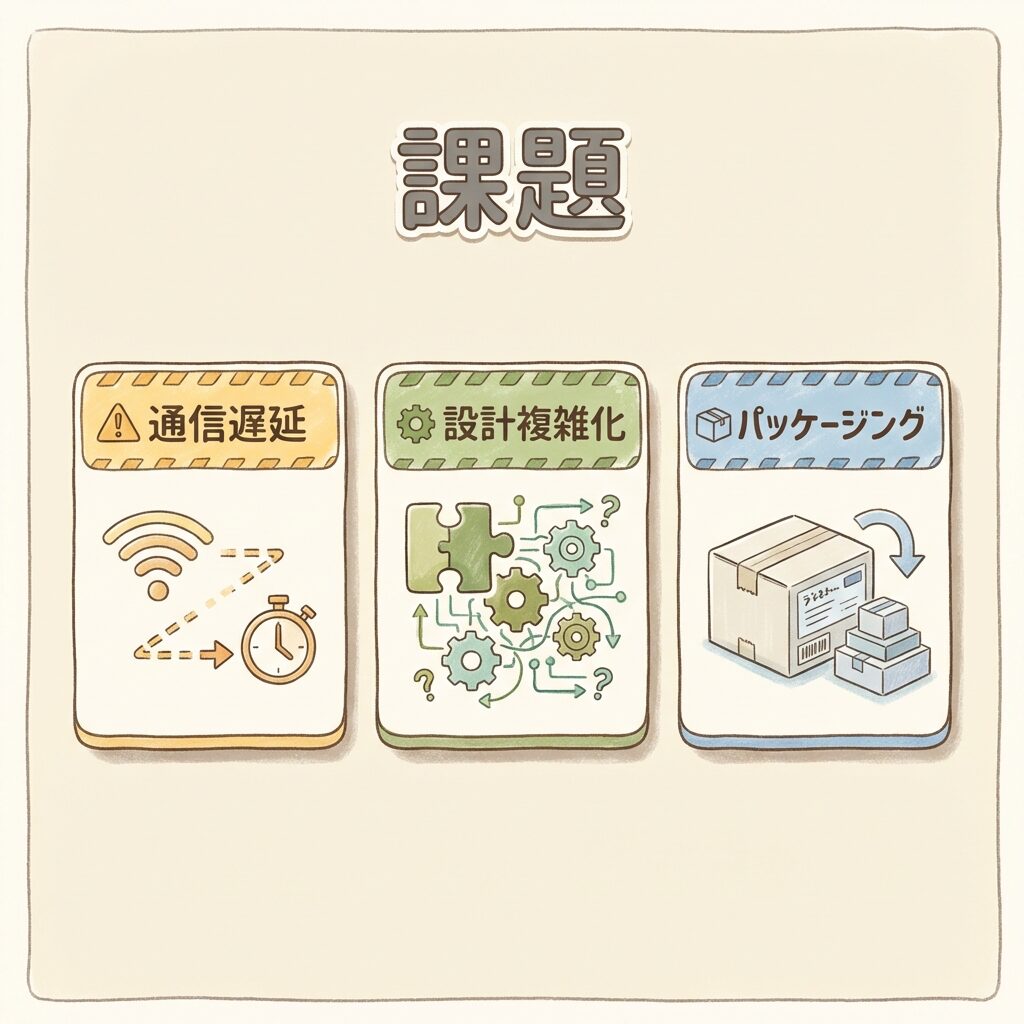
チップレットの3つの課題──万能ではない理由
⚠️ インターコネクト・設計複雑性・パッケージング
チップレットにはメリットだけでなく、乗り越えるべき課題もあります。「チップレットが万能」と思い込むのは危険です。3つの構造的課題を整理します。
チップレット間の通信遅延と消費電力
モノリシックではダイ内部の配線で超高速通信が可能ですが、チップレットでは物理的に別のダイに信号を送る必要があります。この「ダイ間通信」は、ダイ内部より遅延が大きく、消費電力も増えます。チップレット間インターコネクト技術(UCIeなど)の進化が鍵です。
設計と検証の複雑化
異なるプロセスで製造された複数ダイを統合するため、各チップレット間の信号整合性・電力分配・熱管理を全体として検証する必要があり、EDA(電子設計自動化)ツールの高度化が不可欠です。
先端パッケージングが必須
チップレットを高密度に再統合するには、CoWoSやEMIBのような先端パッケージ技術が不可欠です。この製造能力がボトルネックになっており、TSMCのCoWoS生産能力が世界のAI GPU供給量を制約する最大の要因になっています。
「チップレットにすれば必ず安くなる」と思われがちですが、先端パッケージの製造コスト(CoWoS等)はチップレット設計に追加のコストをもたらします。チップレットのコストメリットが上回るのは、ダイサイズが十分に大きく、歩留まりの改善効果がパッケージングの追加コストを超える場合です。小型チップではモノリシックのほうが安くなることもあります。
採用事例で理解する──AMD・NVIDIAはなぜチップレットに移行したのか
🏭 AMDの先駆者的チップレット戦略
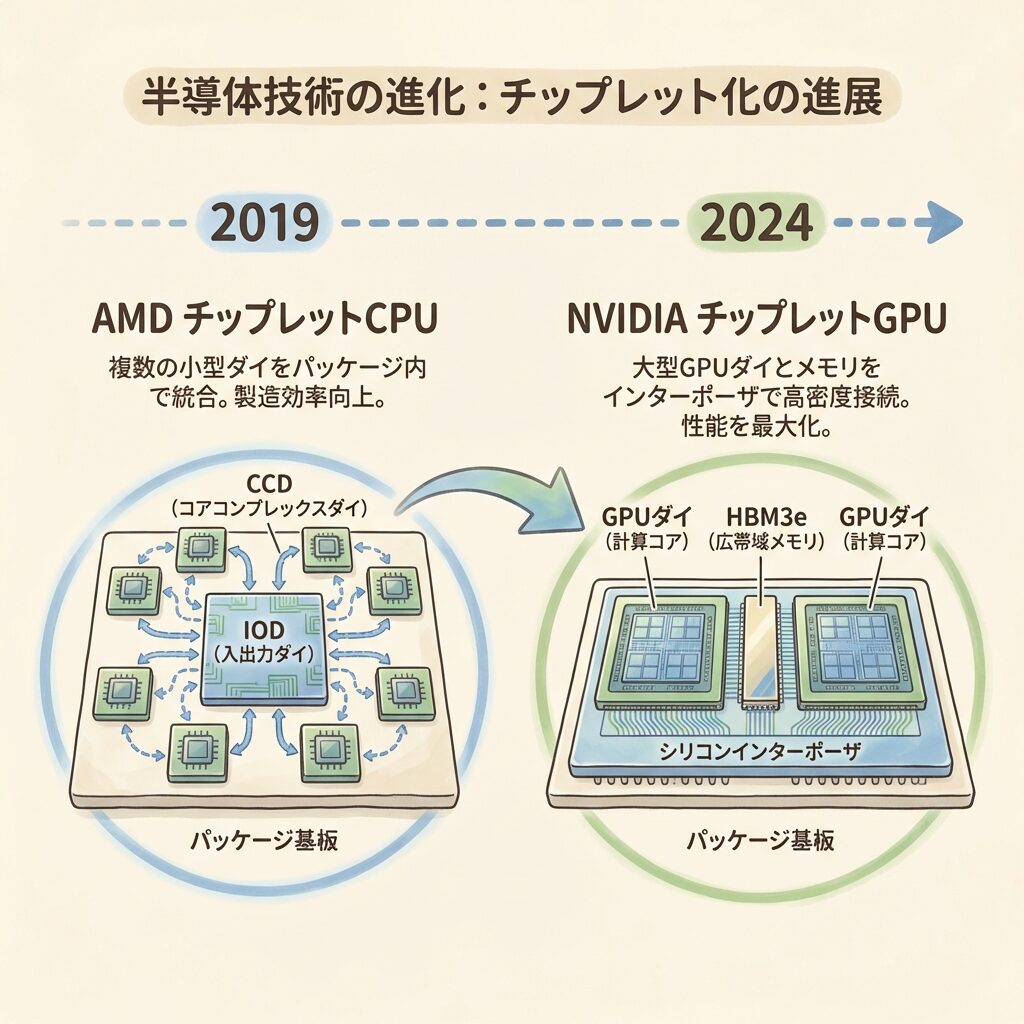
チップレット設計を世界に証明したのはAMDです。2019年のEPYC Rome(第2世代EPYC)で、CPUにチップレットアーキテクチャを本格導入しました。
8コア
8コア
8コア
8コア
メモリ制御・PCIe・Infinity Fabric │ 6nm
8コア
8コア
8コア
8コア
CCD(5nm)×最大8個 + IOD(6nm)×1個 = 最大64コアCPU
CPUコアは最先端5nm、I/Oは安い6nm → コスト最適化
AMDの戦略は明快です。CPUコアの「計算エンジン」は最先端の5nmで性能を追求し、メモリ制御やPCIeなどのI/O機能は、性能がそれほど要求されないため安い6nmで製造する。これにより、すべてを5nmで作るモノリシック設計と比べて大幅なコスト削減を実現しました(出典:AMD EPYC Architecture White Paper)。
🔷 NVIDIAのチップレットGPU──Blackwell B200
NVIDIAはH100まではモノリシック設計を貫いてきましたが、Blackwell世代(B200)でついにチップレット設計に移行しました。B200は2つのGPUダイを10TB/sの超高速インターコネクトで接続し、「1つのGPU」として動作します(出典:NVIDIA公式)。
モノリシックGPUダイ(826mm²)+ CoWoS-S + HBM2E×5スタック
モノリシックGPUダイ(814mm²)+ CoWoS-S + HBM3×5スタック。レチクルサイズぎりぎり。
2つのGPUダイ(各ダイ約800mm²級)を10TB/sインターコネクトで接続。2,080億トランジスタ。CoWoS-L + HBM3E×8スタック。モノリシックの限界を超えた最初のNVIDIA GPU。
さらにHBMスタック数の増加が予想され、CoWoS-Lの5.5〜9レチクル対応への拡張とともに進化する見通し。
NVIDIAがB200でチップレットに移行した最大の理由は、レチクルサイズの壁です。H100のダイ(814mm²)はすでにレチクル限界ぎりぎりでした。さらに性能を上げるには、1枚のダイでは物理的に収まらない──だから2つのダイに「分割」し、CoWoS-Lで再統合したのです。
UCIe──チップレットの「USB規格」が産業を変える
🔗 異なるメーカーのチップレットを「つなぐ」共通言語
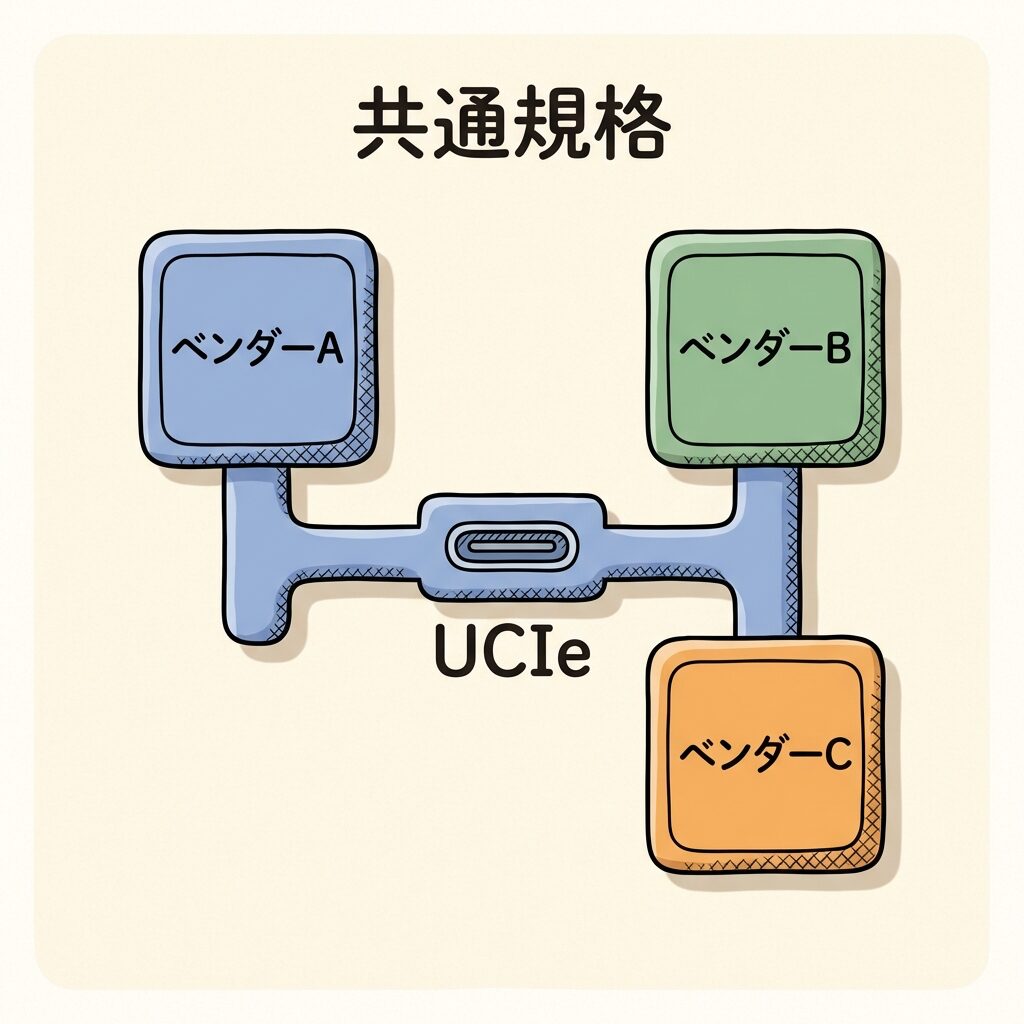
チップレット設計の普及を阻む最大の壁の1つが、「各社のチップレットをどうつなぐか」という問題です。AMDのチップレットにNVIDIAのメモリを組み合わせたい──でも、接続規格がバラバラでは実現できません。
この問題を解決するために生まれたのがUCIe(Universal Chiplet Interconnect Express)です。2022年に Intel・AMD・Arm・TSMC・Samsung・Google・Microsoft などが参加して策定された、チップレット間通信の業界標準規格です(出典:UCIeコンソーシアム公式)。
UCIeは「チップレット版のUSB規格」です。USBが登場する前、プリンターやマウスはメーカーごとに違うコネクタでした。USBが「共通の差し口」を決めたことで、どのメーカーのデバイスもつなげるようになった。UCIeは同じことを、半導体パッケージの内部で実現しようとしています。
チップレット間のダイ・ツー・ダイ通信を標準化するオープン規格。物理層(配線の仕様)・プロトコル層(通信ルール)・ソフトウェアスタックを規定。2022年にUCIe 1.0、2024年8月にUCIe 2.0がリリースされ、3D積層(縦方向接続)やテスト・管理の仕様も追加された。
UCIeの普及は、半導体産業に大きな変化をもたらす可能性があります。現在は各社が自社のチップレットを自社のパッケージ技術で統合するのが主流ですが、UCIeが普及すれば「A社のGPUチップレット+B社のI/Oチップレット+C社のメモリ制御チップレット」を自由に組み合わせる時代が来るかもしれません。まだ完全には実現していませんが、標準化が進むことでチップレット市場の拡大が加速すると見られています。
チップレットと先端パッケージは「表裏一体」
📦 「設計思想」を「実装技術」が支える構造
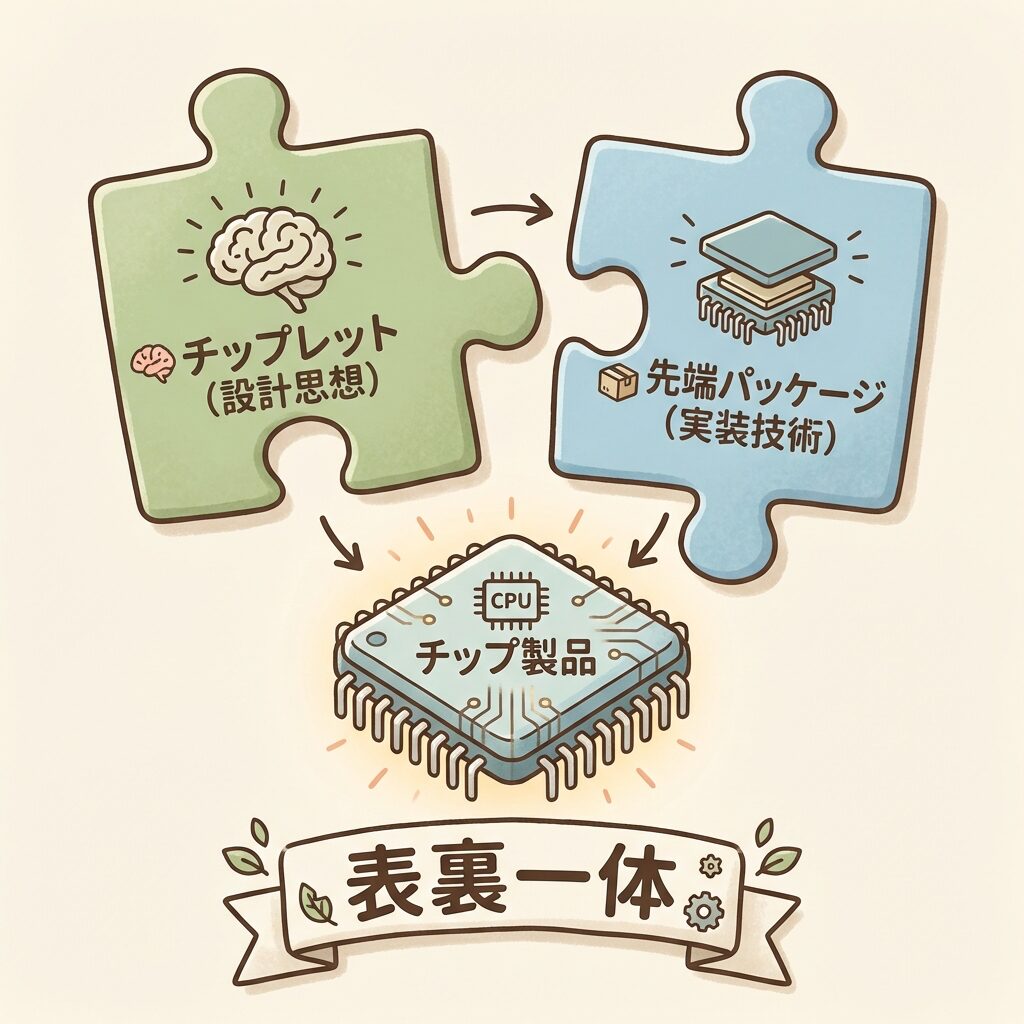
ここまで読んで「チップレットとCoWoSの違いがわからない」と感じた方もいるかもしれません。両者の関係を整理しましょう。
「機能を分割して作る」
「高密度に再統合する」
AMD EPYC 等
チップレットは「こう設計しよう」という発想・アーキテクチャであり、CoWoS・EMIB・SoICは「その設計を現実の製品にする」ためのパッケージ実装技術です。チップレットだけあっても、それを統合するパッケージ技術がなければ製品にならない。逆に、パッケージ技術だけあっても、分割されたチップレットがなければ活かす対象がない。両者はセットで初めて意味を持ちます。
| 先端パッケージ技術 | ベンダー | チップレット統合での役割 |
|---|---|---|
| CoWoS-S / CoWoS-L | TSMC | GPU+HBMを2.5Dで横並び統合 |
| EMIB | Intel | 小型シリコンブリッジでダイ間を接続 |
| Foveros | Intel | チップレットを3D積層で垂直統合 |
| SoIC | TSMC | ハイブリッドボンディングで超高密度3D統合 |
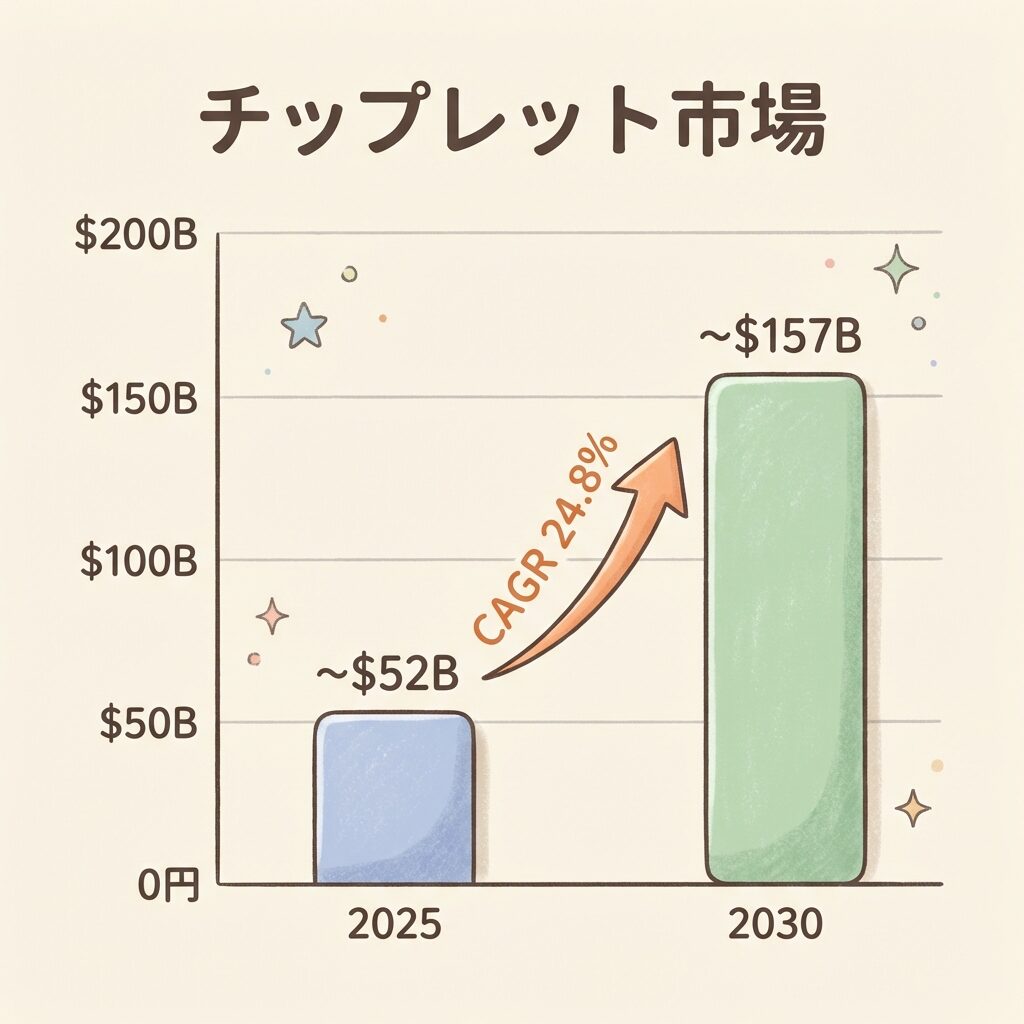
チップレット市場:2030年に約1,570億ドル規模へ
📈 CAGR 24.8% ── AI需要がけん引する急成長
チップレット市場は、AI・HPC・データセンター需要を背景に急速に拡大しています。MarketsandMarketsの予測によると、チップレット市場は2025年の約519億ドルから2030年に約1,572億ドルへ、CAGR(年平均成長率)24.8%で成長する見通しです(出典:MarketsandMarkets / PR Newswire)。
この成長をけん引しているのは、NVIDIA GPU・AMD EPYC・IntelのXeonプロセッサなど、AI・HPCワークロードで使われるチップレット設計の製品群です。チップレットの相互接続規格(UCIe)の標準化、AI GPUのHBMスタック数増加に伴うパッケージの大型化、そしてデータセンター投資の拡大が複合的に市場を押し上げています。
投資家:チップレット市場の成長は、NVIDIA・AMDだけでなく、パッケージ基板(イビデン・新光電気)、実装装置(ディスコ・東京エレクトロン)、素材(レゾナック・味の素ファインテクノ)にも構造的な追い風。
学生:CAGR 24.8%の成長市場は、就職・研究テーマ選びの有力な指標。EDA・パッケージ設計・材料科学のスキルが今後ますます求められる。
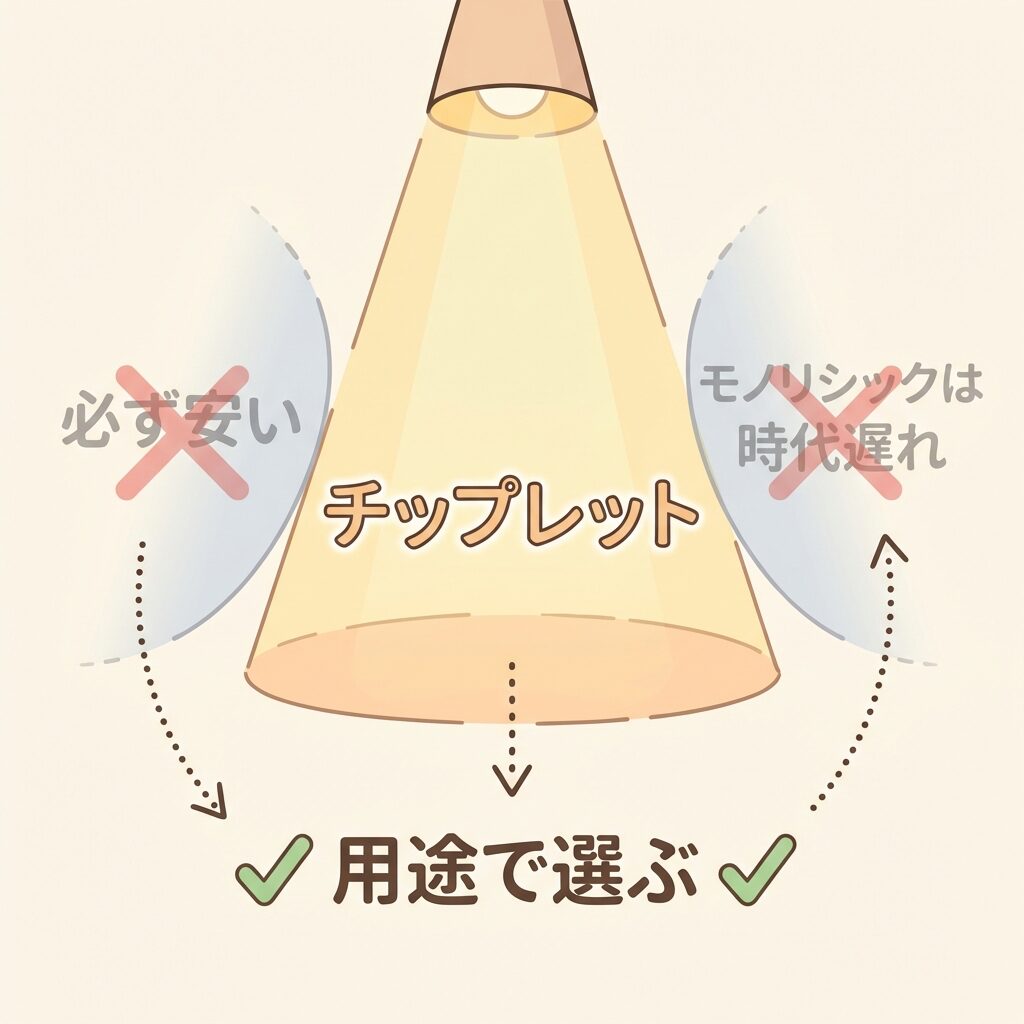
よくある誤解を整理する
| ❌ よくある誤解 | ✅ 実際はこう |
|---|---|
| 「チップレットにすれば必ず安くなる」 | 先端パッケージの追加コストがかかるため、ダイサイズが十分に大きく歩留まり改善が追加コストを上回る場合にのみコストメリットが出る。小型チップではモノリシックのほうが安いこともある。 |
| 「チップレット=先端パッケージ」 | チップレットは設計思想であり、先端パッケージは実装技術。両者は表裏一体だが同じものではない。チップレットを実現する「手段」が先端パッケージ。 |
| 「モノリシックは時代遅れ」 | 小型・高速・低遅延が求められるチップでは、モノリシック設計が最適な場合もある。Apple M4や一部のスマホSoCは依然としてモノリシック。チップレットとモノリシックは「優劣」ではなく「用途の違い」。 |
| 「UCIeで異メーカーのチップレットを自由に組み合わせられる」 | UCIeは標準規格を整備中だが、現時点では各社が自社内でチップレットを統合するのが主流。異メーカー間の「レゴのような自由な組み合わせ」はまだ発展途上。 |
| 「チップレットは最近の技術」 | マルチチップモジュール(MCM)の概念自体は数十年前から存在。AMDが2019年にEPYC Romeで商用化し注目されたが、発想自体は新しくない。変わったのは先端パッケージ技術が追いついたこと。 |
まとめ:チップレットの全体像
① 定義:チップレットとは、機能ごとに分割した小さなダイを先端パッケージ技術で再統合する設計手法。「分割して組み合わせる」がキーワード。
② モノリシックとの違い:モノリシック=1枚の大きなダイ(歩留まり低下・コスト増)。チップレット=小さなダイの組み合わせ(歩留まり向上・プロセス混載可能)。
③ 4つのメリット:歩留まり向上・コスト削減・設計柔軟性・開発スピード。AMDは16コアCPUで2倍以上のコスト優位性を公表。
④ 3つの課題:チップレット間通信遅延・設計検証の複雑化・先端パッケージの製造能力がボトルネック。
⑤ 採用事例:AMD EPYC(CCD+IODの分離設計)、NVIDIA B200(2ダイGPU、CoWoS-L)。レチクルサイズの壁がチップレット移行を推進。
⑥ UCIe規格:チップレット間通信の業界標準。2024年にUCIe 2.0がリリース。異メーカー間の相互運用を目指す。
⑦ 市場規模:2030年に約1,570億ドル(CAGR 24.8%)。AI・HPC需要が構造的にけん引。
結局こういうことです。半導体は「小さくする」だけでは限界に達しました。その突破口が、「小さなダイを複数作って、高度なパッケージ技術で組み合わせる」──チップレットという設計思想です。AMDがCPUで証明し、NVIDIAがGPUで採用し、UCIeという標準規格が整い始めた。チップレットは「一時的なトレンド」ではなく、半導体設計の構造的なパラダイムシフトです。
❓ よくある質問(FAQ)
📚 次に読むべき記事
チップレットを含む先端パッケージの全体地図。2D→2.5D→3Dの進化の階段を俯瞰できます。
チップレットを「再統合する」パッケージ技術CoWoSの仕組みを図解で理解。
NVIDIA B200がCoWoS-Lを選んだ理由を、インターポーザーの構造から解説。
📩 記事の更新情報を受け取りたい方へ
新しい記事が公開されたら、Xアカウント @shirasusolo でお知らせします。
AIインフラの構造を一緒に学んでいきましょう。

コメント