「CoWoS(コワース)」という言葉、AIや半導体のニュースで急に目にするようになりましたよね。でも、こんなふうに感じていませんか?
- CoWoSって何の略? 読み方すらわからない
- 「先端パッケージ技術」と聞いても、何がどう先端なのかピンとこない
- GPUとHBMを「つなぐ」技術らしいけど、なぜそれが重要なの?
- CoWoS-S、CoWoS-L、CoWoS-Rの3種類があるらしいが、違いがわからない
- NVIDIAやTSMCの話でよく出てくるけど、投資やキャリアにどう関係するの?
- CoWoSの意味・読み方・定義を30秒で理解
- 「なぜ普通のパッケージではダメなのか」をたとえ話で納得
- CoWoSの仕組み(インターポーザー・TSV・2.5D実装)を図解
- CoWoS-S / CoWoS-L / CoWoS-Rの3種類の違いと使い分け
- NVIDIA A100 → H100 → B200でCoWoSがどう進化したか
- TSMCの生産能力がAI産業のボトルネックになっている構造
- 投資家・学生にとっての意味と行動指針
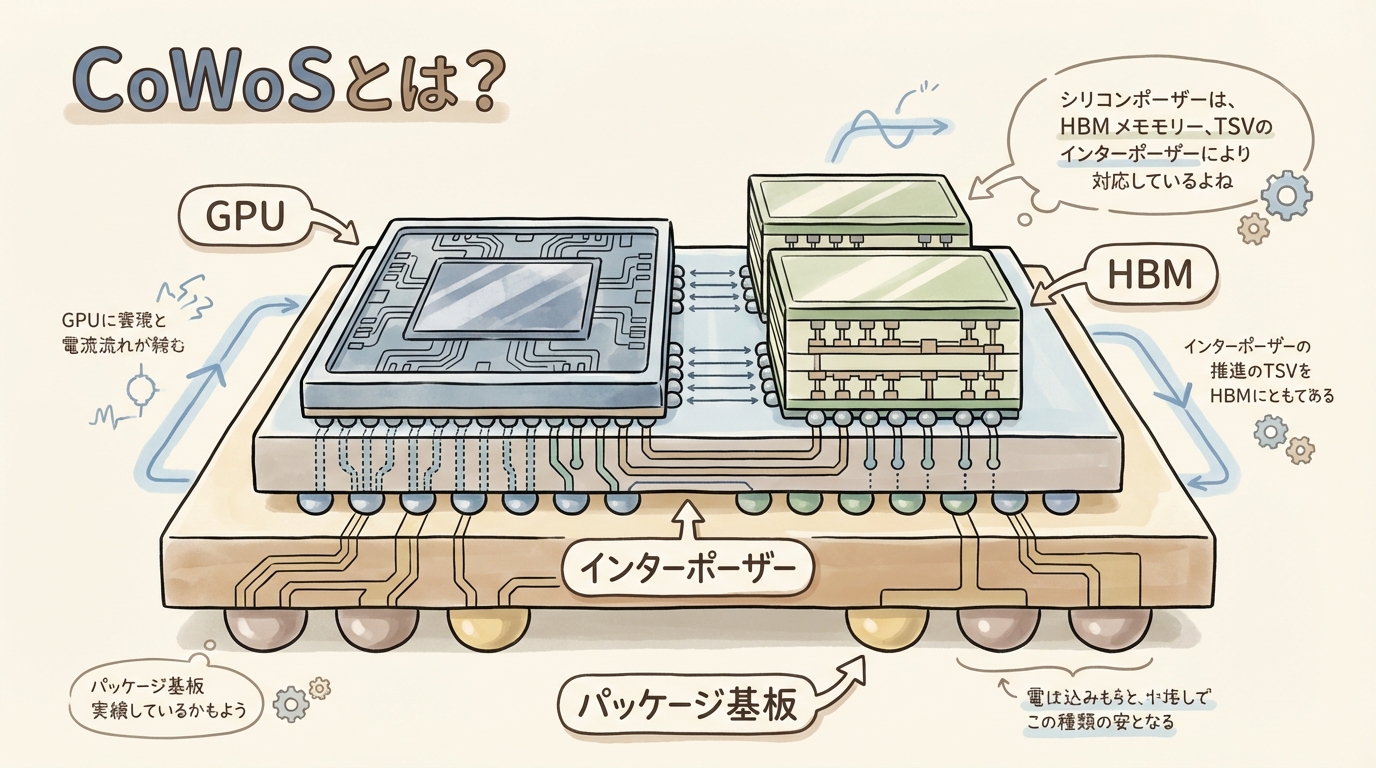
CoWoS(Chip on Wafer on Substrate)とは、GPUとHBM(高帯域幅メモリ)を1つのパッケージに統合するための、TSMCが開発した先端パッケージ技術です。GPUダイとHBMスタックを「シリコンインターポーザー」と呼ばれる中間基板の上に横並びに配置し、超高密度の配線で接続します。この技術がなければ、NVIDIA H100やB200のような最先端AI GPUはそもそも製品として成立しません。現在、NVIDIAはTSMCのCoWoS生産能力の70%以上を確保しており(出典:Introl)、CoWoSの製造キャパシティはAI半導体の供給を左右する最大のボトルネックとなっています。この記事では「CoWoSとは何か」を仕組みから理解し、AI産業の構造の中でなぜこの技術が決定的に重要なのかを解説します。
前回の記事(HBMとは?)で、GPUの性能を引き出す「超高速メモリ」HBMを解説しました。しかし、GPUとHBMは別々のチップです。この2つを「どうやって1つの製品にまとめるか」──その答えが、今回のテーマ「CoWoS」です。
- CoWoSとは?──まず30秒で全体像をつかむ
- なぜCoWoSが必要なのか?──「普通のパッケージ」では限界がある
- CoWoSの仕組み──3ステップで理解する製造プロセス
- CoWoSの3種類──S・L・Rの違いを一目で理解する
- NVIDIA GPUの進化とCoWoSの関係──A100からB200まで
- なぜCoWoSがAI産業の「ボトルネック」なのか
- CoWoSと「チップレット」の関係──なぜ今、パッケージが主役なのか
- CoWoSの競合技術──IntelのEMIBとFoveros
- よくある誤解を整理する
- あなたにとっての意味──投資家・学生・技術者の視点
- まとめ:CoWoSの全体像
- ❓ よくある質問(FAQ)
CoWoSとは?──まず30秒で全体像をつかむ
📖 CoWoS = Chip on Wafer on Substrate(チップ・オン・ウェハー・オン・サブストレート)
CoWoS(読み方:コワース)とは、複数の半導体チップ(GPUダイやHBMスタック)を、シリコンインターポーザーと呼ばれる中間基板の上に横並びに配置し、それを1つのパッケージ基板に搭載する先端パッケージ技術です。TSMCが2011年に開発し、2012年に量産を開始しました。
名前の意味を分解すると、こうなります。
個々のチップ
(中間基板)
(最終的な土台)
つまり「チップ → インターポーザー → 基板」という3層のサンドイッチ構造で、複数のチップを1つのパッケージにまとめる技術です。この「2.5D実装」と呼ばれる手法は、チップを横に並べて接続する点が特徴です(チップを縦に積み重ねるのは「3D実装」)。
GPUとHBMなど複数のチップを同一平面上に載せるための「中間基板」。シリコン製が主流で、超微細な配線とTSV(貫通電極)を備える。チップ同士を数mm以内の超短距離で接続することで、高速・低消費電力のデータ転送を実現する。
CoWoSは「超精密な模型の台座」のようなものです。GPUという「エンジン」と、HBMという「燃料タンク」を、台座(インターポーザー)の上にぴったり並べて、超細い配管(配線)でつなぐ。台座がなければ、エンジンと燃料タンクは遠く離れてしまい、燃料の供給が追いつかない──つまりGPUの性能が引き出せないのです。
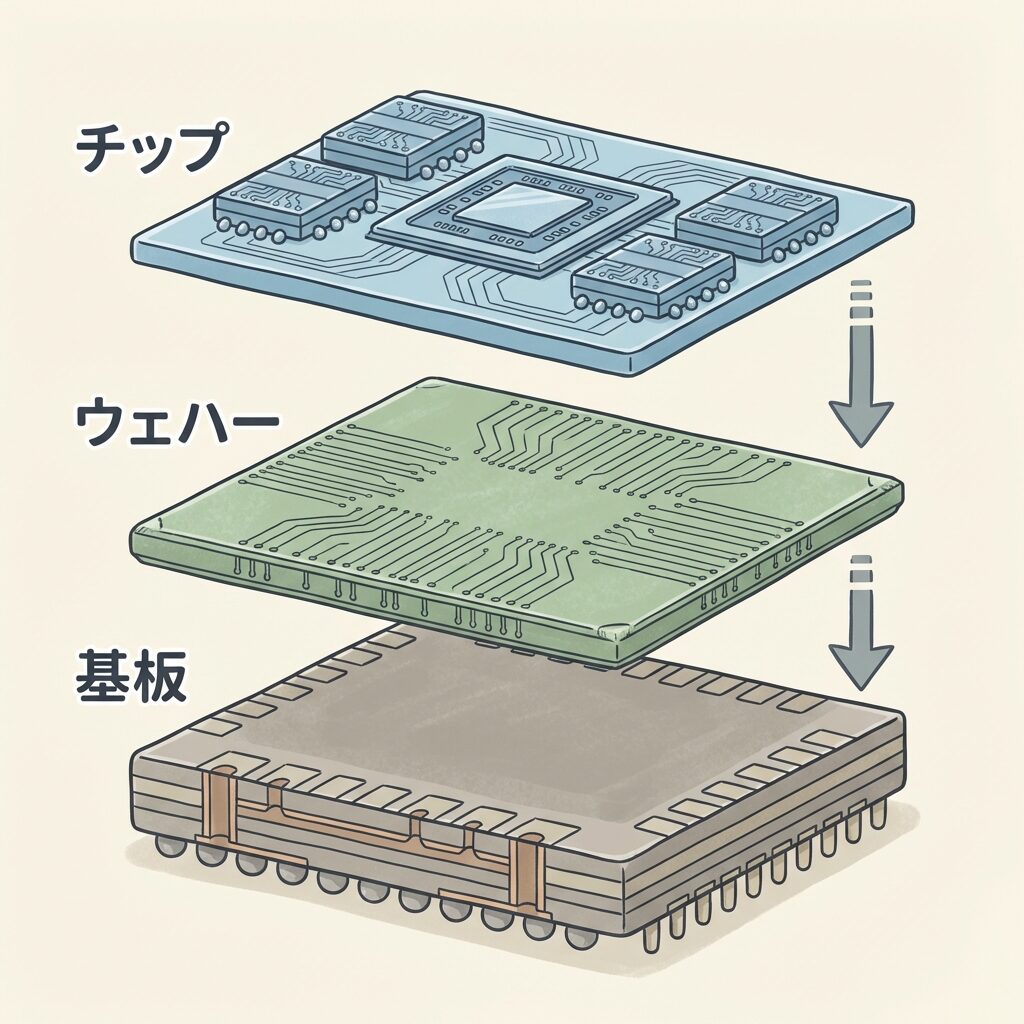
なぜCoWoSが必要なのか?──「普通のパッケージ」では限界がある
🧱 従来のパッケージの問題点:「遠すぎる」と「狭すぎる」
従来の半導体パッケージでは、GPUとメモリ(HBM)は別々のパッケージに入れて、マザーボード上の配線でつなぐのが一般的でした。しかしAI時代になって、この方式には2つの致命的な問題が浮上しました。
問題① 距離が「遠すぎる」
GPUとメモリがマザーボード上で数cm離れていると、信号の伝送距離が長くなり、通信速度が落ち、消費電力も増える。AI計算で必要な「超高速データ供給」に追いつかない。
問題② 配線が「狭すぎる」
マザーボード上の配線は密度に限界がある。HBMが必要とする1,024bit以上の超広バス幅は、マザーボードの配線ルールでは物理的に実現不可能。
✅ CoWoSの解決策:「近づけて」「太くする」
CoWoSはこの2つの問題を、シンプルかつ根本的に解決しました。
数cm
数mm
消費電力大幅削減
シリコンインターポーザーの上にGPUとHBMを数mm以内の距離で並べることで、信号の伝送距離を劇的に縮め、超高密度の配線(1,024bit以上のバス幅)を可能にしたのです。距離が縮まったことで消費電力も下がります。
CoWoSが解決したのは「チップ同士の物理的な距離と配線密度の限界」です。AIの世界でGPU性能が上がっても、GPUとメモリの間のデータ転送が遅ければ意味がない(メモリウォール問題)。CoWoSは、このボトルネックを「物理的に近づける」という発想で根本から解消しました。
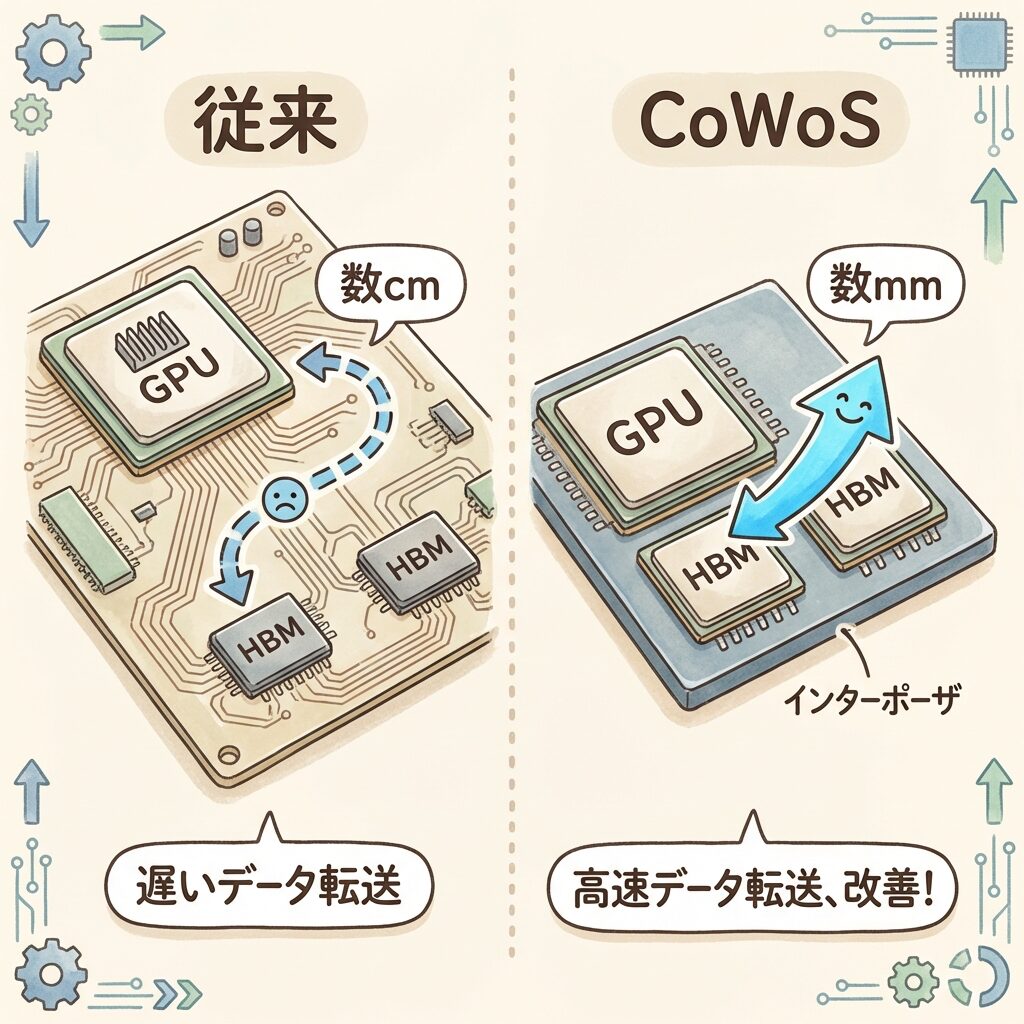
CoWoSの仕組み──3ステップで理解する製造プロセス
🔬 「ウェハーの上でチップを組み立て、基板に載せる」
CoWoSの製造プロセスは、名前の通り3つのステップで構成されます。
シリコンウェハーで作られたインターポーザーの上に、GPUダイやHBMスタックなどの個々のチップを精密に配置します。このとき、チップは「フリップチップ」と呼ばれる方法で裏返しにして接続されます。チップの電極とインターポーザーの微細な配線が直接接触する形です。
チップの電極面を下向きにして基板に直接接続する実装方式。従来のワイヤボンディング(金線で接続)よりも接続密度が高く、信号伝送が高速。
チップが載ったインターポーザー上で、接続テストと追加加工を行います。インターポーザー内部にはTSV(Through-Silicon Via:貫通シリコンビア)が数千〜数万本通っており、インターポーザーの表面(チップ側)と裏面(基板側)を垂直に貫通して接続しています。
シリコンを貫通する超微細な電極。インターポーザーの表面と裏面を垂直に結ぶ「エレベーター」の役割。これにより、チップ側の信号をパッケージ基板側へ高速に伝送できる。
チップが搭載されたインターポーザーを、パッケージ基板(有機基板)に接合します。パッケージ基板は、マザーボードとの接続を担う最終的な「土台」です。これでCoWoSパッケージが完成──GPUとHBMが1つのパッケージに統合された状態になります。
CoWoSの製造は「精密なジオラマ制作」に似ています。STEP 1で、精密な台座(インターポーザー)の上にミニチュアの建物(GPU・HBM)を正確に配置する。STEP 2で、建物同士が台座内の地下通路(TSV)でちゃんとつながっているか確認する。STEP 3で、台座ごとケースの中(パッケージ基板)に固定する。完成品は「見た目は1つのチップだが、中に複数の建物がある」状態です。
| 構成要素 | 役割 | ポイント |
|---|---|---|
| GPUダイ | AI計算の実行 | 1万個以上のコアで超並列処理を担う「頭脳」 |
| HBMスタック | 超高速データ供給 | 3D積層DRAMでGPUに1TB/s超の帯域幅を提供 |
| インターポーザー | チップ間接続 | 超微細配線+TSVでGPUとHBMを数mm以内で接続 |
| パッケージ基板 | 外部接続 | マザーボードとの接続を担う最終的な土台 |


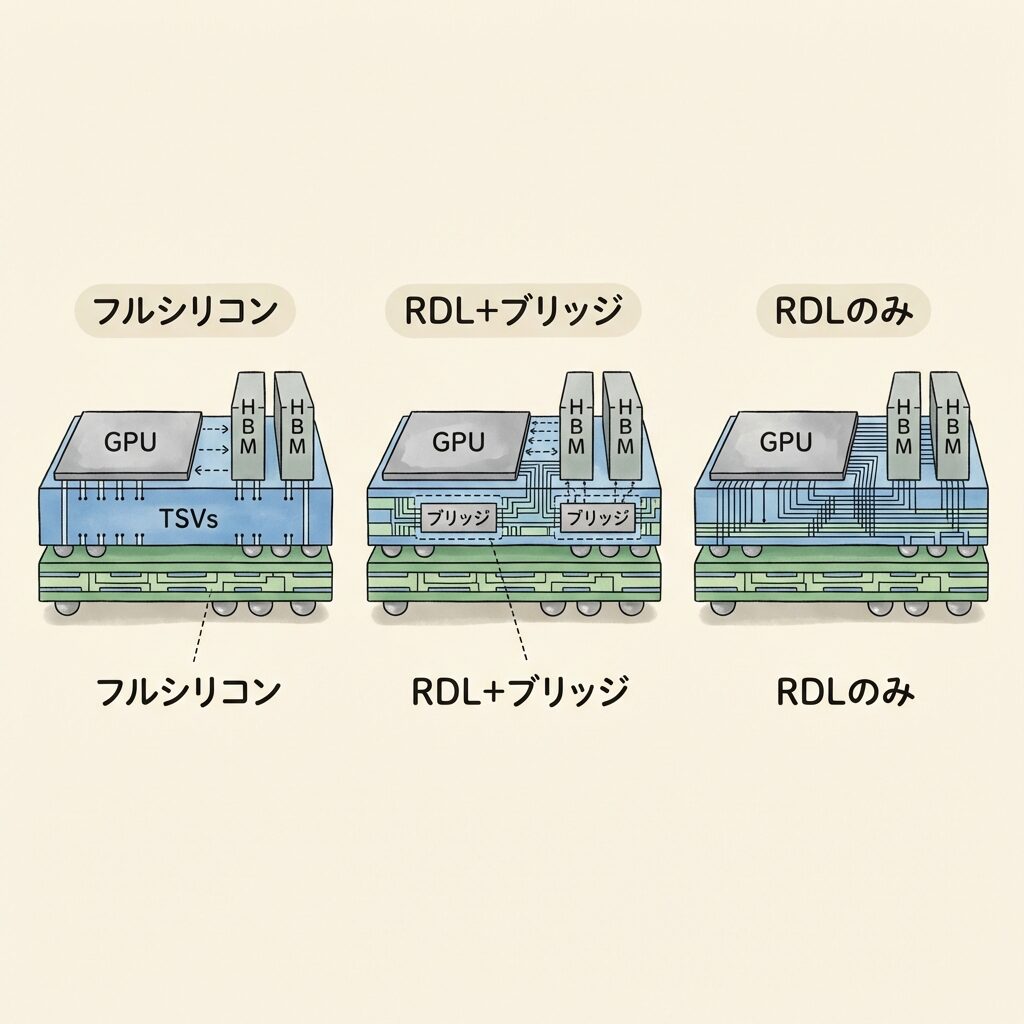
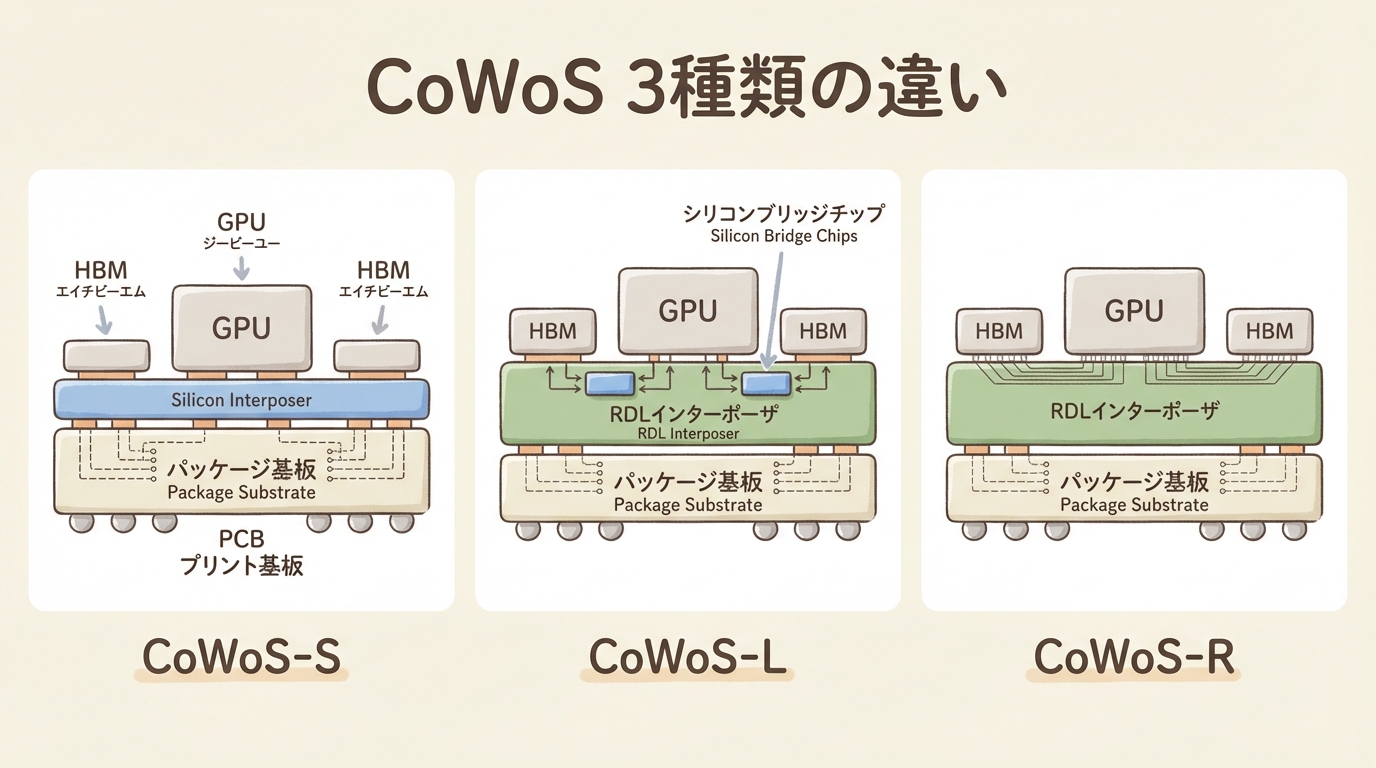
CoWoSの3種類──S・L・Rの違いを一目で理解する
🗂️ 3種類の違いは「インターポーザーの材料と構造」
CoWoSにはCoWoS-S、CoWoS-L、CoWoS-Rの3つのバリエーションがあります。名前が似ていて混乱しがちですが、違いはシンプルです。「中間基板(インターポーザー)に何を使うか」だけが異なります。
最高の配線密度
H100に採用
大型化に対応・高歩留まり
B200に採用(現在の主流)
低コスト・大面積対応
配線密度は最も低い
| 比較項目 | CoWoS-S | CoWoS-L | CoWoS-R |
|---|---|---|---|
| インターポーザー | フルシリコン | RDL+局所シリコンブリッジ(LSI) | RDL(有機再配線層)のみ |
| 配線密度 | 最高 | 高い(ブリッジ部分は高密度) | 低い |
| パッケージサイズ | 〜2.5レチクル(制約あり) | 大型化可能(制約が緩い) | 大型化可能 |
| コスト | 高い | 中程度 | 低い |
| 歩留まり | 大型化すると低下 | 比較的高い | 高い |
| 代表的な採用GPU | A100 / H100 | B200(Blackwell) | 一部のHPC製品 |
出典:CoWoSの3種類の分類は EE Times Japan、Introl、NVIDIAの採用情報は Tom’s Hardware を参考に構成
Redistribution Layer(リディストリビューション・レイヤー)の略。チップの電極を外部接続用に「配線し直す」ための層。シリコンインターポーザーの代わりに有機材料で作るため、コストが低く大面積化に有利。ただし配線密度はシリコンに劣る。
CoWoS-Sは配線密度が最高ですが、フルシリコンインターポーザーは大型化すると歩留まり(良品率)が下がります。GPUが巨大化した最新世代(Blackwell B200は2つのGPUダイを搭載)では、CoWoS-Sのサイズ制約では収まりきらなくなりました。CoWoS-Lは「必要な部分だけシリコン(ブリッジ)を使い、それ以外はRDLにする」というハイブリッド方式で、大型化・歩留まり・コストのバランスを取っています(出典:Tom’s Hardware)。
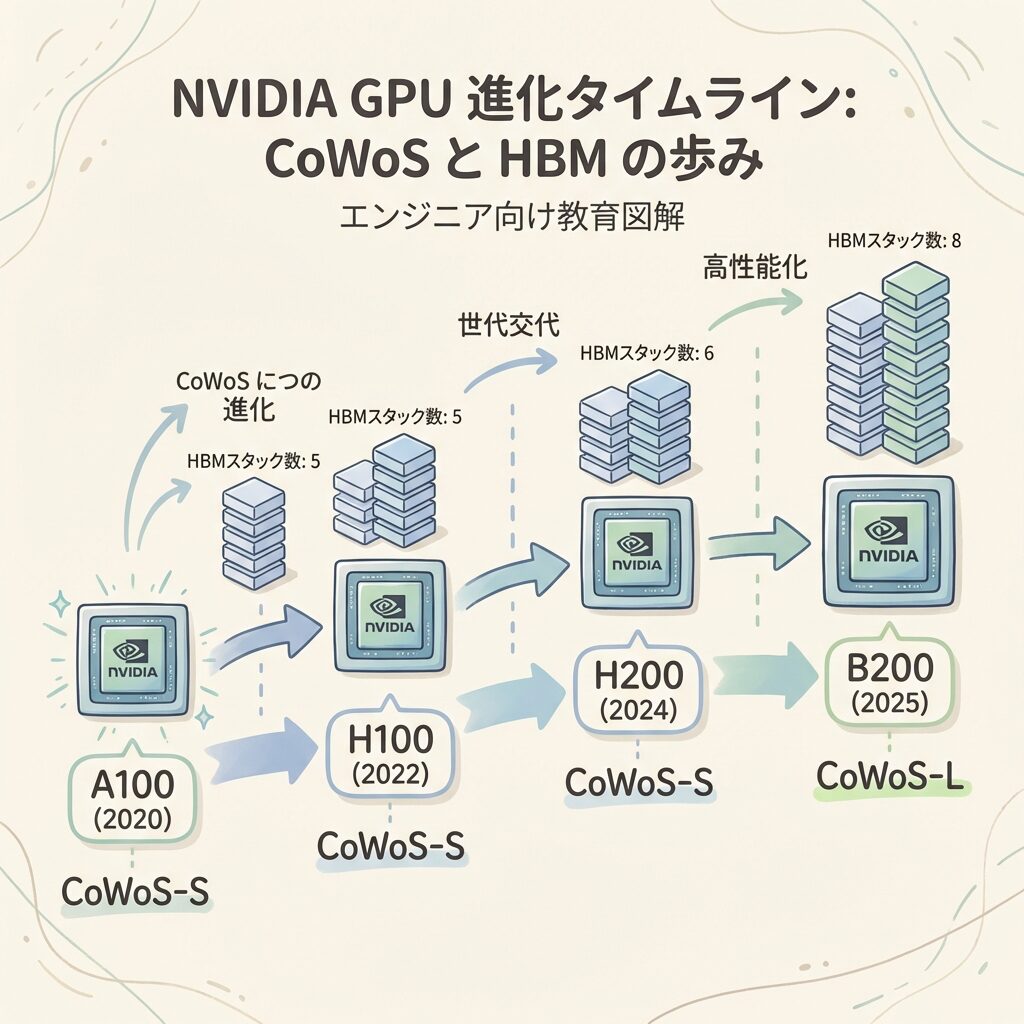
NVIDIA GPUの進化とCoWoSの関係──A100からB200まで
📅 GPU世代が進むたびに、CoWoSも進化してきた
NVIDIAのデータセンター向けGPUは、すべてCoWoS技術で製造されています。GPU世代の進化は、CoWoSの進化と表裏一体です。
CoWoS-S採用。HBM2e × 5スタック搭載。パッケージサイズ約2レチクル。これがAIデータセンター向けGPUに「CoWoSが必須」であることを業界に決定づけた世代。
CoWoS-S採用。HBM3 × 5スタック(80GB・3.35TB/s)。ChatGPTブームでH100の需要が爆増し、CoWoSの生産能力が世界的なボトルネックに。TSMCがCoWoS増産を急いだ転換点。
CoWoS-S採用。HBM3E × 6スタック(141GB・4.8TB/s)。HBM容量と帯域幅が大幅に向上し、推論性能が飛躍的に改善。
CoWoS-Lに移行。2つのGPUダイ+HBM3E × 8スタックを1パッケージに搭載。CoWoS-Sではサイズが収まらないため、CoWoS-Lへの移行が決定(出典:Tom’s Hardware)。NVIDIAはTSMCのCoWoS-L生産能力の70%以上を確保。
なぜCoWoSがAI産業の「ボトルネック」なのか
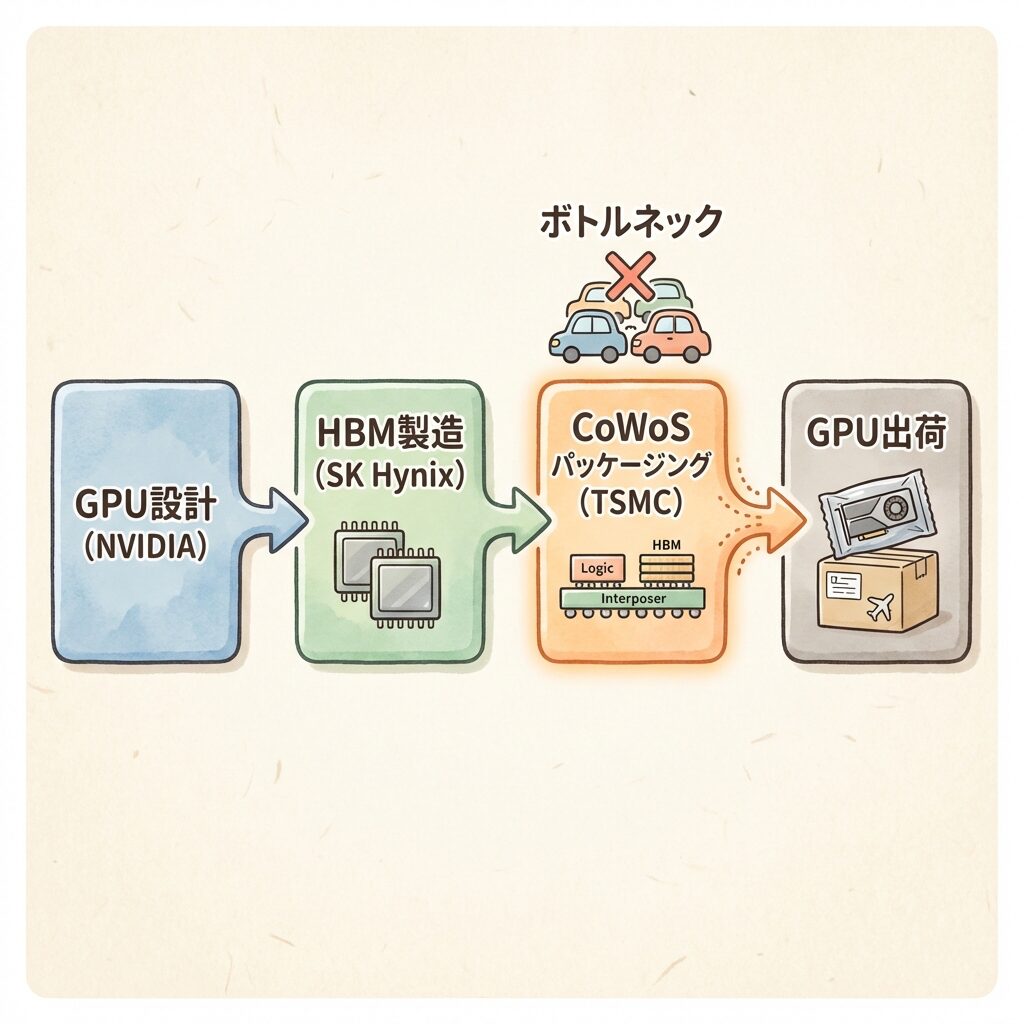
🏭 GPU設計は完成している。しかし「包むもの」が足りない
NVIDIAはGPUの「設計」を持っていますが、GPUを「製品」にするにはCoWoSパッケージングが必要です。そしてCoWoSを量産できるのは、事実上TSMCだけです。この構造が、AI半導体の供給に深刻なボトルネックを生んでいます。
ChatGPT以降、世界中のハイパースケーラーがNVIDIA GPUを大量発注。
NVIDIAはH100やB200の設計を持っている。「作りたい」ものはある。
TSMCのCoWoS工場はフル稼働でも需要に追いつかない。生産能力の拡張には年単位の時間が必要。
NVIDIAがどれだけGPUを「設計」しても、CoWoSで「包め」なければ出荷できない。パッケージング能力がAI産業の成長速度を決めている。
📈 TSMCの増産計画──2026年末に月産12〜13万枚へ
この状況を受けて、TSMCはCoWoSの生産能力を急拡大しています。TrendForceの報道によると、TSMCは2026年末までにCoWoSの月産能力を現在の7.5〜8万枚から12〜13万枚に引き上げる計画です(出典:TrendForce)。
それでもCoWoS-SとCoWoS-Lは「完全に予約済み」の状態が続いています。世界のCoWoS需要は2024年の37万枚から2025年に67万枚、2026年には100万枚に達する見通しです(出典:36Kr)。バーンスタインはCoWoSがTSMC売上の約15%を占めると予測しています(出典:Investing.com)。
「AI半導体の供給制約 = チップの微細化技術が足りない」と思われがちですが、現在の最大のボトルネックはチップの「包み方」(パッケージング)です。NVIDIAはGPUの回路設計を持っている。HBMはSK Hynixが量産している。しかし、それらを1つにまとめるCoWoSの生産能力が追いつかないことが、出荷数を制約しているのです。
CoWoSと「チップレット」の関係──なぜ今、パッケージが主役なのか
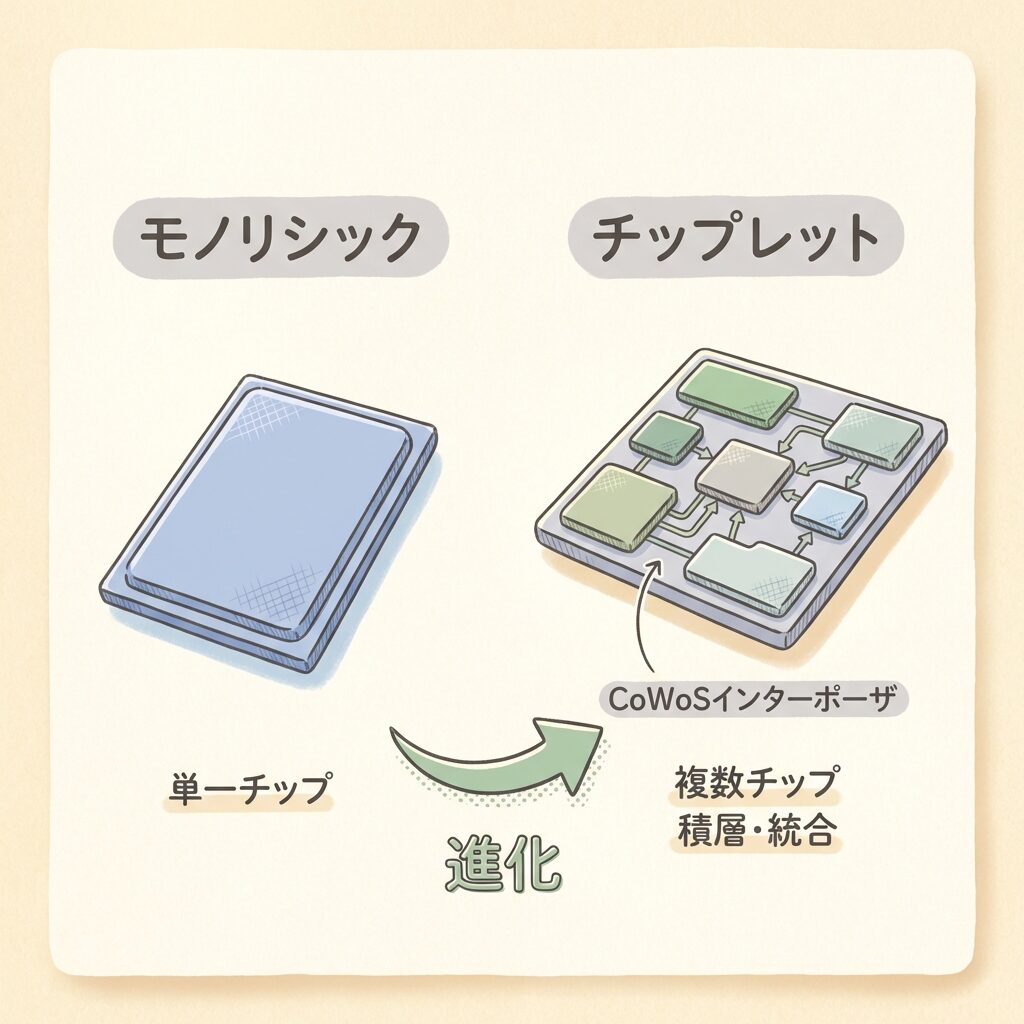
🧩 「1枚の巨大チップ」から「複数チップの組み合わせ」へ
半導体の世界では長年、「1枚のシリコンウェハーから1つの巨大なチップを切り出す」(モノリシック設計)が主流でした。しかし、チップが巨大化するほど製造の歩留まりが下がり、コストが跳ね上がるという問題がありました。
そこで登場したのが「チップレット」という考え方です。機能ごとに小さなチップ(ダイ)に分けて製造し、それらを1つのパッケージに組み合わせる──いわば「レゴブロックの組み立て」方式です。
1つの大きなチップを丸ごと作る代わりに、機能ごとに分割した小さなチップ(ダイ)を複数組み合わせて1つのパッケージにする設計手法。GPUダイ、メモリダイ、I/Oダイなどを別々に製造し、CoWoSのようなパッケージ技術で統合する。「ヘテロジニアス集積」とも呼ばれる。
1枚の巨大なシリコンにすべての機能を詰め込む。チップが大きいほど不良品になる確率が上がり、コストが指数関数的に増大する。
機能ごとに小さなダイに分け、それらをCoWoSのようなパッケージ技術で統合。小さいダイは歩留まりが高く、異なるプロセスの組み合わせも可能。
CoWoSは、まさにこの「チップレット時代」を支えるための技術です。GPUダイ(演算)とHBMスタック(メモリ)という異なる種類のチップを、1つのパッケージに高性能に統合する──これがCoWoSの本質的な役割です。NVIDIAのBlackwell B200は、2つのGPUダイ+8つのHBMスタックをCoWoS-Lで統合しており、チップレット設計の最先端を体現しています。
半導体の進化の「主軸」は、微細化(ムーアの法則)からパッケージング(チップレット統合)へとシフトしつつあります。CoWoSはその最前線にある技術です。「半導体の進化 = チップを小さくすること」だけではなくなった──これが現在の業界の構造変化です。

CoWoSの競合技術──IntelのEMIBとFoveros
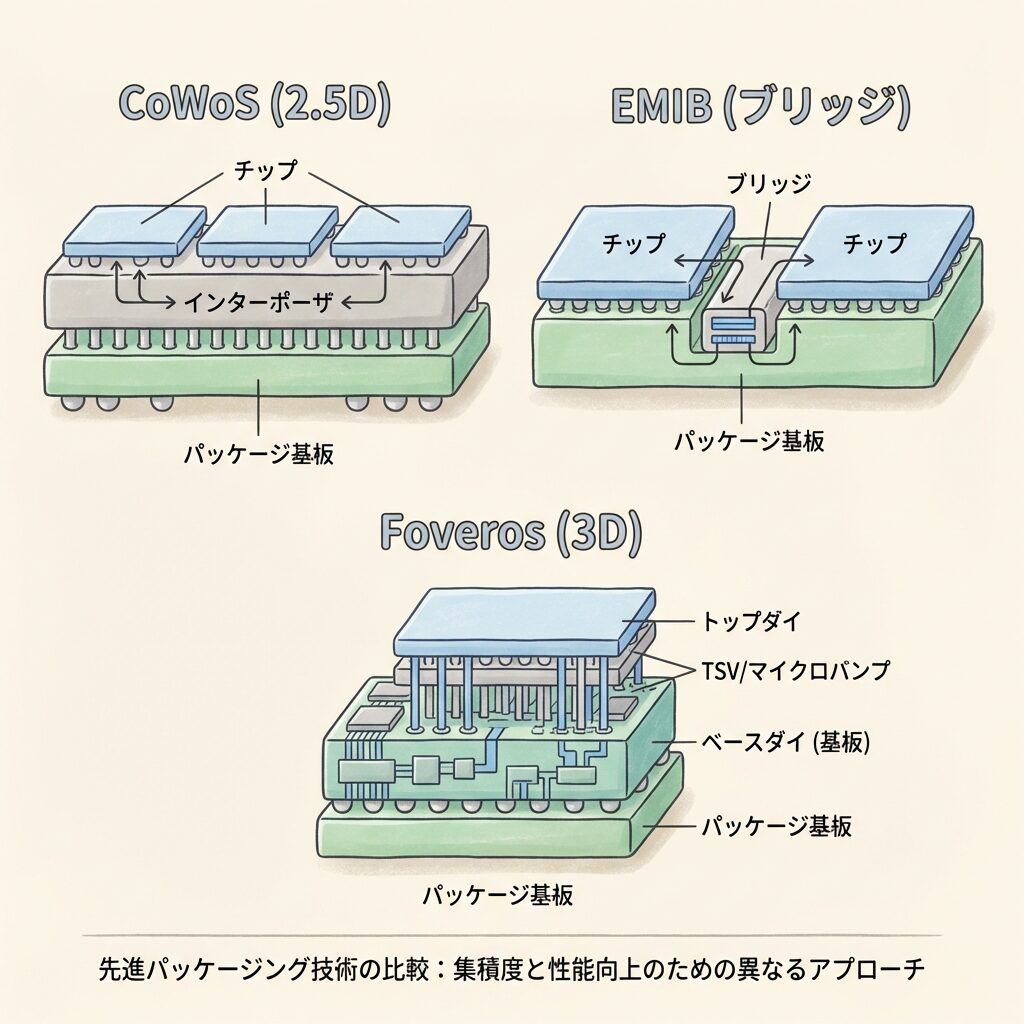
先端パッケージ技術はTSMC独占ではなく、Intelも独自技術を持っています。ただし、AI GPUの主戦場ではCoWoSが圧倒的な実績を持っています。
| 技術名 | 開発元 | 方式 | 特徴 |
|---|---|---|---|
| CoWoS | TSMC | インターポーザー上にチップを横並び(2.5D) | AI GPUの事実上の標準。製造成熟度が最も高い |
| EMIB | Intel | 基板に埋め込んだ小さなシリコンブリッジでチップを接続 | 大型インターポーザー不要でコスト低減。ペア接続向き |
| Foveros | Intel | チップを垂直に積み重ねる(3D) | 省面積だが、発熱管理が課題。異なるプロセスの混載に有利 |
出典:Introlの技術比較を参考に構成(出典)
よくある誤解を整理する
| ❌ よくある誤解 | ✅ 実際はこう |
|---|---|
| 「CoWoSはNVIDIAの技術」 | CoWoSはTSMCが開発・製造する技術。NVIDIAは「CoWoSを使ってGPUを包んでもらう」立場。設計(NVIDIA)・メモリ(SK Hynix)・パッケージング(TSMC)の3社分業。 |
| 「CoWoSはチップの微細化技術」 | 微細化は「チップ内部の回路を小さくする」技術。CoWoSは「完成した複数のチップを1つにまとめる」パッケージ技術。まったく別の工程。 |
| 「パッケージ技術は地味な裏方」 | AI時代には、パッケージング技術がGPU出荷数を直接制約する最大のボトルネック。「裏方」どころか、AI産業の成長速度を決める主役。 |
| 「CoWoSはどの半導体メーカーでも使える」 | CoWoSはTSMCの独自技術(商標)。他社は同等技術を持っているが、CoWoSの製造成熟度とAI GPUでの実績は現時点でTSMCが圧倒的。 |
| 「CoWoSの3種類はすべて同じくらい重要」 | 現在の主流はCoWoS-L(Blackwell B200が採用)。CoWoS-Sは前世代、CoWoS-Rは一部用途。NVIDIAの最新GPUを追うなら、CoWoS-Lの動向が最重要。 |
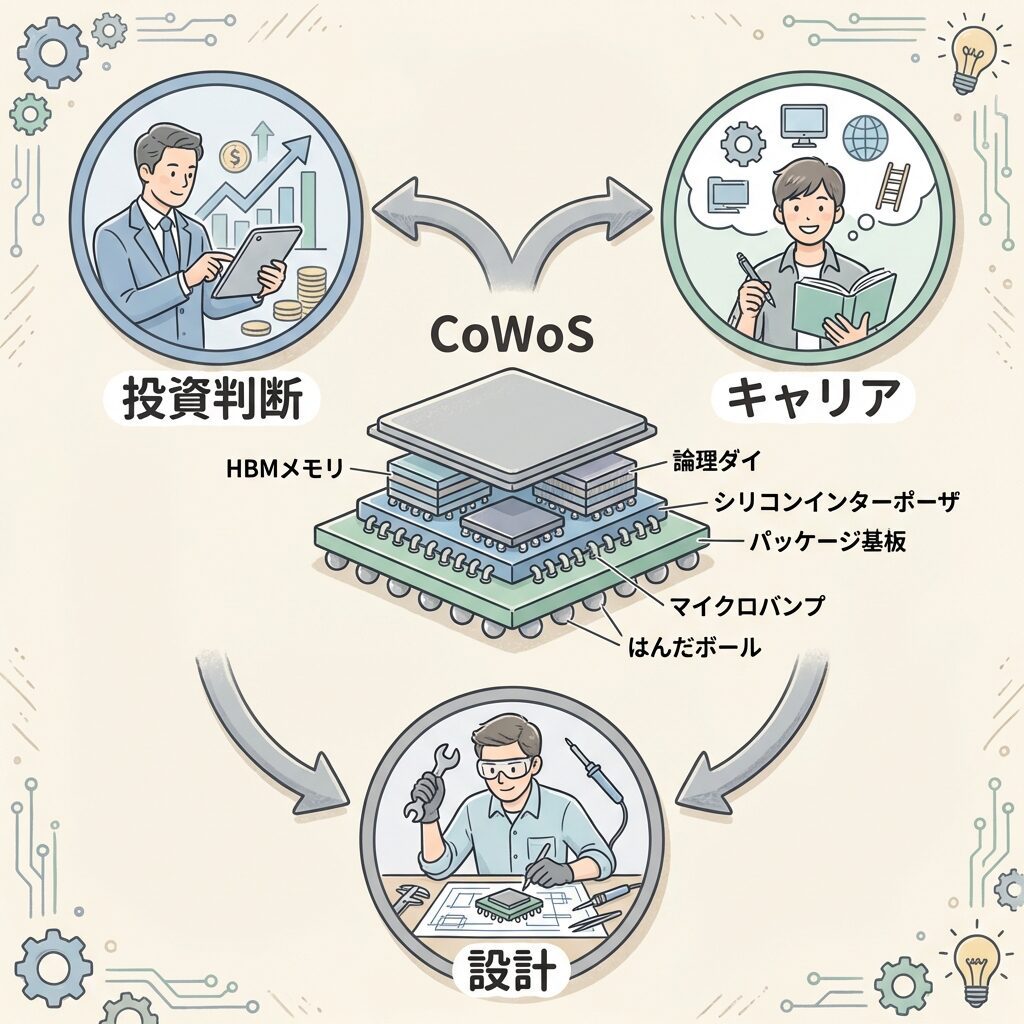
あなたにとっての意味──投資家・学生・技術者の視点
AI関連投資で「NVIDIA」だけを見ていませんか? NVIDIAの業績は、TSMC(CoWoSの製造能力)とSK Hynix(HBMの供給量)に直接依存しています。CoWoSの生産能力がNVIDIAのGPU出荷数を決めるということは、TSMCのCoWoS増産計画やCapEx(設備投資)がNVIDIA株価の先行指標になり得るということです。さらに、CoWoSに使うシリコンインターポーザーの研磨装置(ディスコ等)、検査装置(アドバンテスト等)、パッケージング用基板メーカーも、サプライチェーンの上流として注目に値します。
半導体産業の「次の主戦場」は微細化ではなくパッケージングに移りつつあります。CoWoS・TSV・2.5D/3D実装・チップレット設計は、半導体エンジニアが今後必ず直面する技術領域です。これは情報系だけでなく、電気工学(信号伝送設計)・材料工学(インターポーザー素材)・精密機械(実装装置)の学生にとっても大きなキャリアチャンスです。「半導体 = 回路設計だけ」という時代は終わりました。
CoWoSパッケージングの技術は、AIデータセンターの設計・運用にも影響を及ぼします。パッケージサイズの拡大はソケット設計や冷却設計に直結し、消費電力の増加は電力設備の要件を変えます。「チップの中身」だけでなく「チップの包み方」が、システム設計の前提条件を変えている──これを理解しておくことで、インフラ設計の精度が上がります。
まとめ:CoWoSの全体像
① CoWoSとは:Chip on Wafer on Substrate。GPUとHBMをシリコンインターポーザー上に横並びに配置し、1つのパッケージに統合するTSMCの先端パッケージ技術。
② なぜ必要か:GPUとHBMの距離を数cmから数mmに縮め、1,024bit超の超広バス幅を確保する。これにより帯域幅が数十倍向上し、メモリウォール問題を解消する。
③ 仕組み:チップをインターポーザーに載せ(Chip on Wafer)、それを基板に搭載(on Substrate)する3層構造。TSVで垂直接続。
④ 3種類:CoWoS-S(フルシリコン・H100)、CoWoS-L(RDL+ブリッジ・B200・現在の主流)、CoWoS-R(RDLのみ・低コスト)。
⑤ GPU進化との関係:A100→H100→H200はCoWoS-S、B200からCoWoS-Lへ移行。HBMスタック数の増加がパッケージ大型化を要求。
⑥ ボトルネック:NVIDIAはTSMCのCoWoS-L生産能力の70%超を確保。CoWoS生産能力がAI GPU出荷数を直接制約する最大のボトルネック。
⑦ チップレット時代:半導体の進化の主軸が「微細化」から「パッケージング(チップレット統合)」にシフト。CoWoSはその最前線。
結局こういうことです。CoWoSは「GPUとHBMをつなぐ接着剤」のような技術です。GPUがどれだけ高性能でも、HBMがどれだけ高速でも、それらを1つの製品に統合するCoWoSがなければ、AI GPUは存在しません。そしてこのCoWoSの製造能力が、世界のAI半導体供給の「蛇口」を握っている。だからCoWoSを理解することは、AI産業の構造を理解することなのです。
❓ よくある質問(FAQ)
📖 【完全図解】AIデータセンターとは?従来型との違いと構造を解説 →
CoWoSでパッケージングされたGPUが大量に並ぶ「AIデータセンター」の全体構造を俯瞰できます。
📚 次に読むべき記事
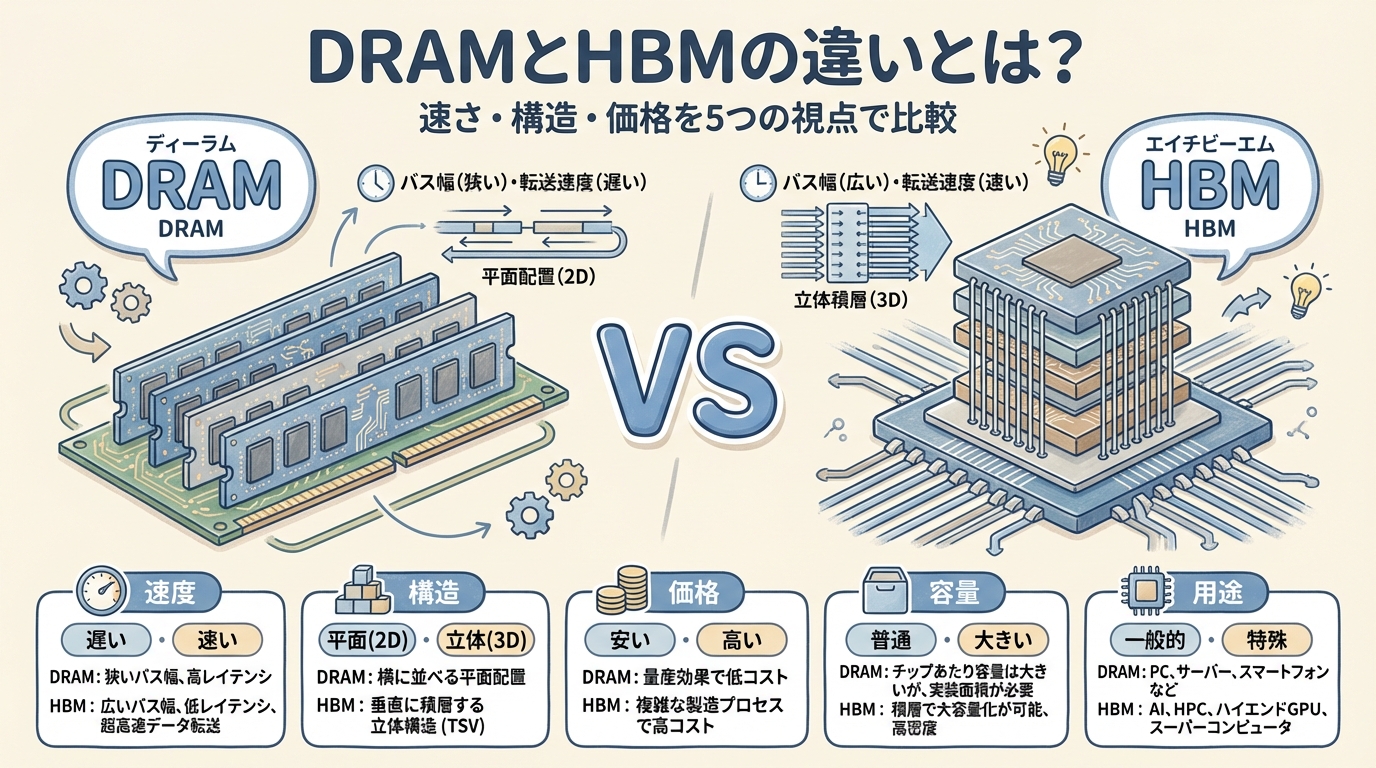
CoWoSで接続される「HBM」とは何か。3D積層・TSV・メモリウォール問題を図解。この記事の「前提知識」です。
HBMがDRAMとどう違うのかを5視点で比較。CoWoSがなぜ「普通のメモリ接続」では不十分なのかが理解できます。
CoWoSでパッケージングされたGPUが搭載されるサーバーの構成と消費電力を理解できます。
CoWoSパッケージの大型化・高消費電力化がデータセンター設計にどう影響するかを解説。
📩 記事の更新情報を受け取りたい方へ
新しい記事が公開されたら、Xアカウント @shirasusolo でお知らせします。AIインフラの構造を一緒に学んでいきましょう。
コメント