「AIデータセンター」とひとくちに言うけれど、中に何が入っているか説明できますか?──そう聞かれると、意外と答えに詰まりませんか?
- GPUが大事なのはわかるけど、GPU以外に何が必要なの?
- ストレージやネットワークの役割って、AIだとどう変わるの?
- 電源設備や冷却設備って具体的に何があるの?
- 全体像を「1枚の地図」として見たことがない
- なぜ「1つ欠けてもAIは動かない」と言われるの?
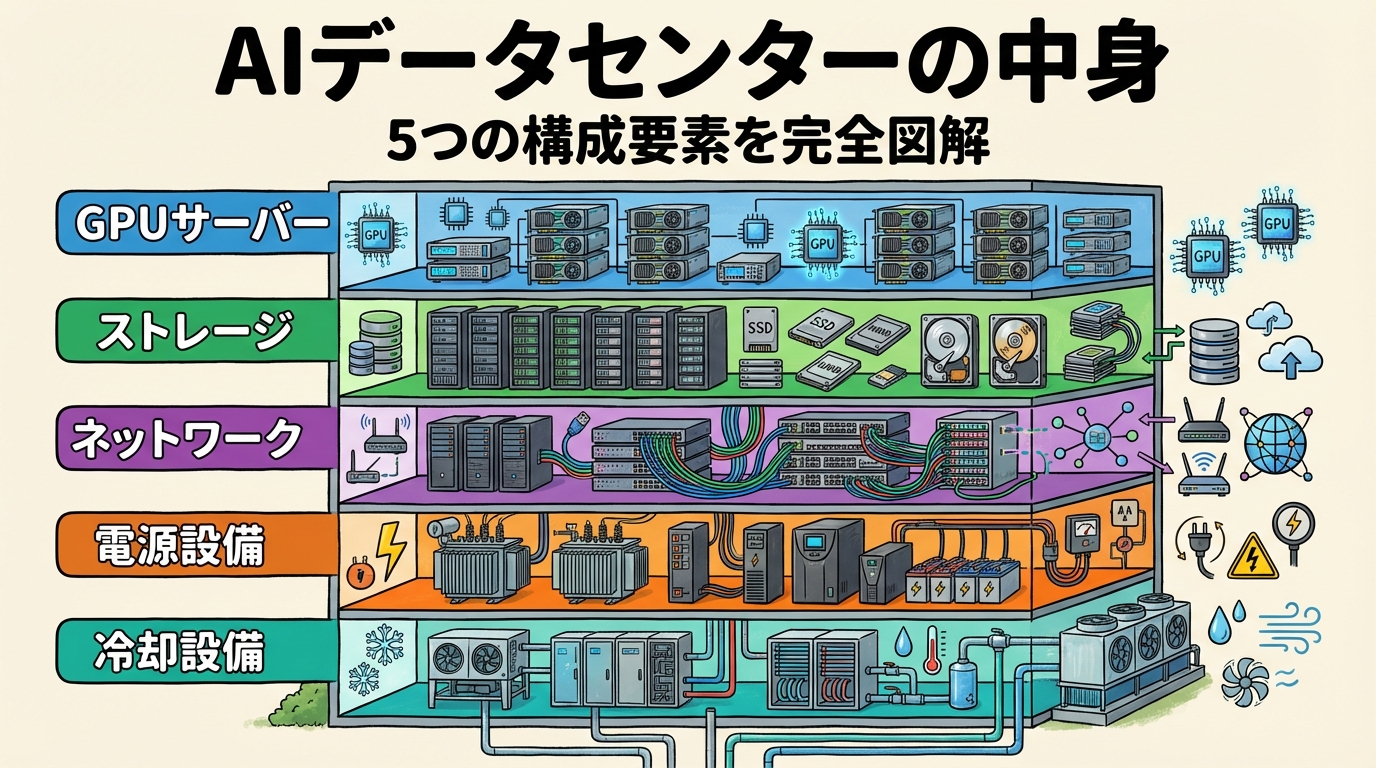
- AIデータセンターを構成する5つの要素の全体像
- 各要素の役割と、AIで何が変わったのか
- 「データの流れ」と「電力の流れ」を並べた構造図
- 「見える設備」と「見えにくい設備」の整理
- なぜ1つ欠けても成立しないのか──因果の構造
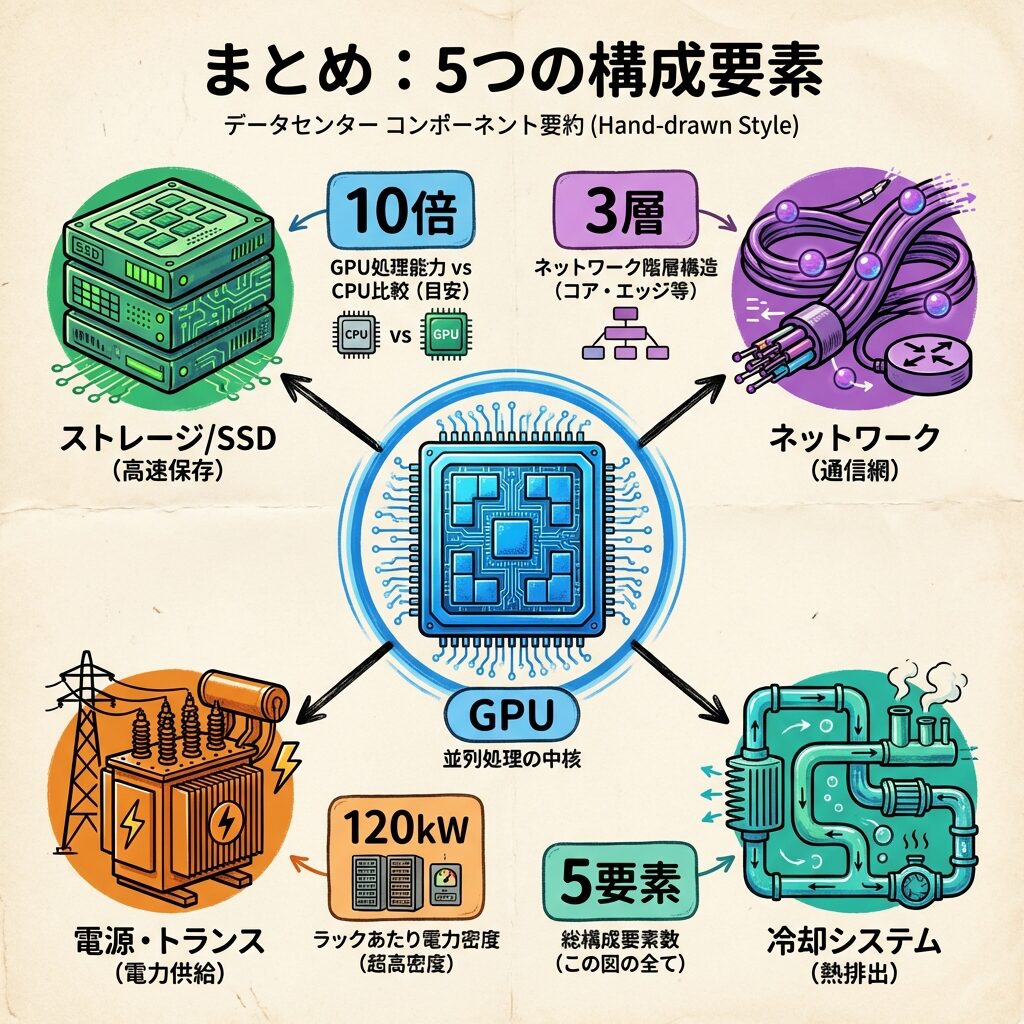
AIデータセンターは、①GPUサーバー(計算)、②高速ストレージ(記憶)、③超広帯域ネットワーク(通信)、④大容量電源設備(電力供給)、⑤高性能冷却設備(排熱処理)の5つの層で構成されています。従来のデータセンターにも同じ5要素はありましたが、AIデータセンターではそのすべてが桁違いのスペックを要求されます。GPUだけあっても、データを送れなければ学習できない。電力を供給できなければ動かない。冷やせなければ壊れる。5つのうち1つでも欠ければ、AIは止まります。この記事は、その全体像を「1枚の地図」として手に入れるための記事です。
これまでのロードマップ記事では、GPUサーバー、GPUラック、PUE、電力問題、空冷・液冷と個別テーマを掘り下げてきました。この記事はそれらを「1枚の地図」に統合する回です。ここを読めば、バラバラだった知識がつながります。
AIデータセンターの全体アーキテクチャ ── 5つの構成要素
🏗️ まず全体の「地図」を見る
いきなり個別パーツの話に入る前に、全体の構造を俯瞰しましょう。AIデータセンターは、以下の5つの構成要素が組み合わさって初めて機能します。
5つの層すべてが揃って初めて「AIデータセンター」として機能する。1つでも欠ければAIは止まる。
AIデータセンターは「超巨大な料理工場」です。①GPUサーバーは「調理チーム」、②ストレージは「食材倉庫」、③ネットワークは「食材を運ぶベルトコンベア」、④電源は「ガスと電気」、⑤冷却は「換気・冷蔵設備」。どれか1つでも止まれば、工場は動きません。
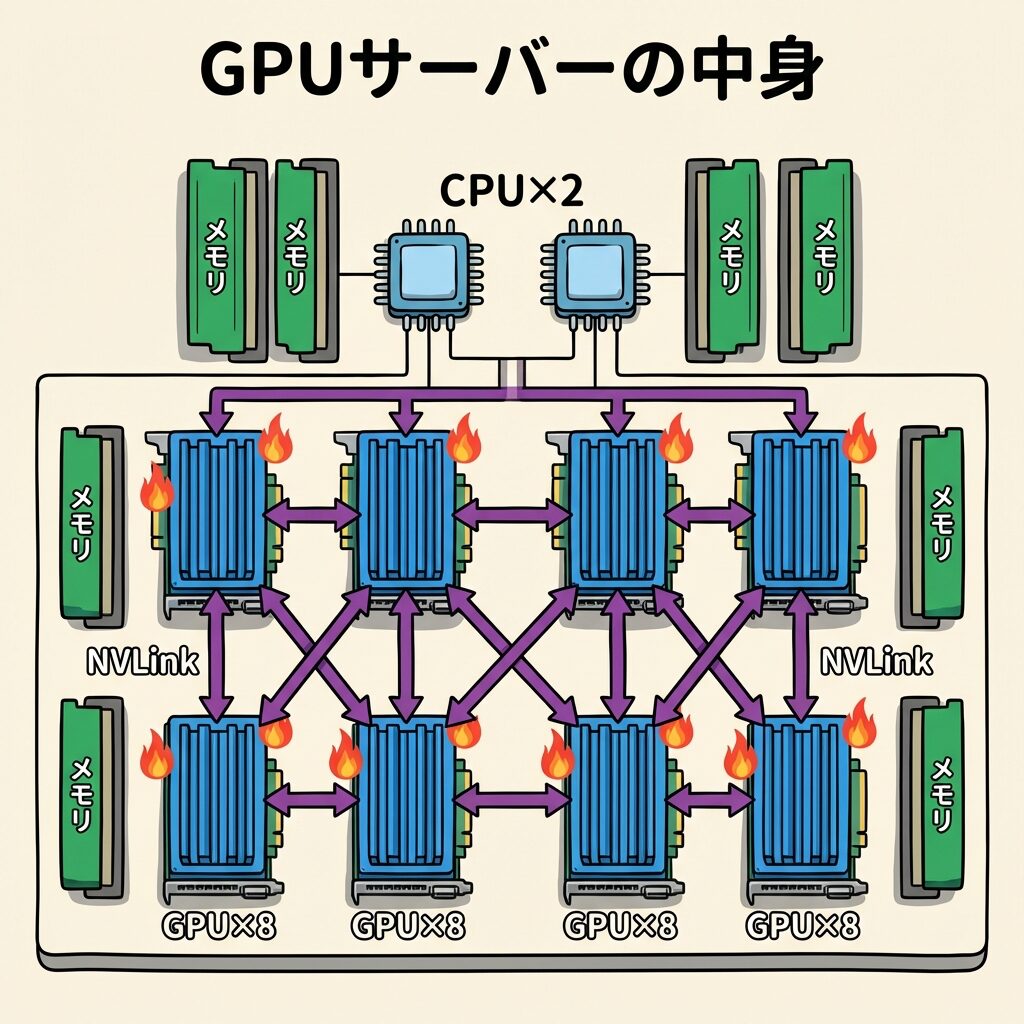
① GPUサーバー(計算層)── AIの「頭脳」
🧠 数千台のGPUが一斉に計算する「超並列処理マシン」
AIデータセンターの主役は、言うまでもなくGPUサーバーです。AIの学習(トレーニング)と推論(インファレンス)を実行する「頭脳」であり、数千〜数万台のGPUが同時に動作します。
従来のデータセンターではCPU(汎用プロセッサ)が主役でしたが、AIの計算は「同じような計算を何兆回も繰り返す」という超並列処理です。この処理はCPUよりもGPUが圧倒的に得意──コアの数がCPUの数十個に対してGPUは1万個以上だからです。
AIで何が変わったか
従来型のCPUサーバーは消費電力が300〜800W程度でした。GPUサーバーはその10倍以上──1台で約10kW。この消費電力の爆増が、後述する電源・冷却すべての設計を根本から変えた起点です。
② ストレージ(記憶層)── AIの「食材倉庫」
💾 膨大な学習データを超高速で読み書きする
AIの学習には、テキスト・画像・動画などの膨大なデータが必要です。GPT-4レベルの大規模言語モデルの学習には数十TBのデータが使われます。このデータを保存し、GPUに高速で供給するのがストレージの役割です。
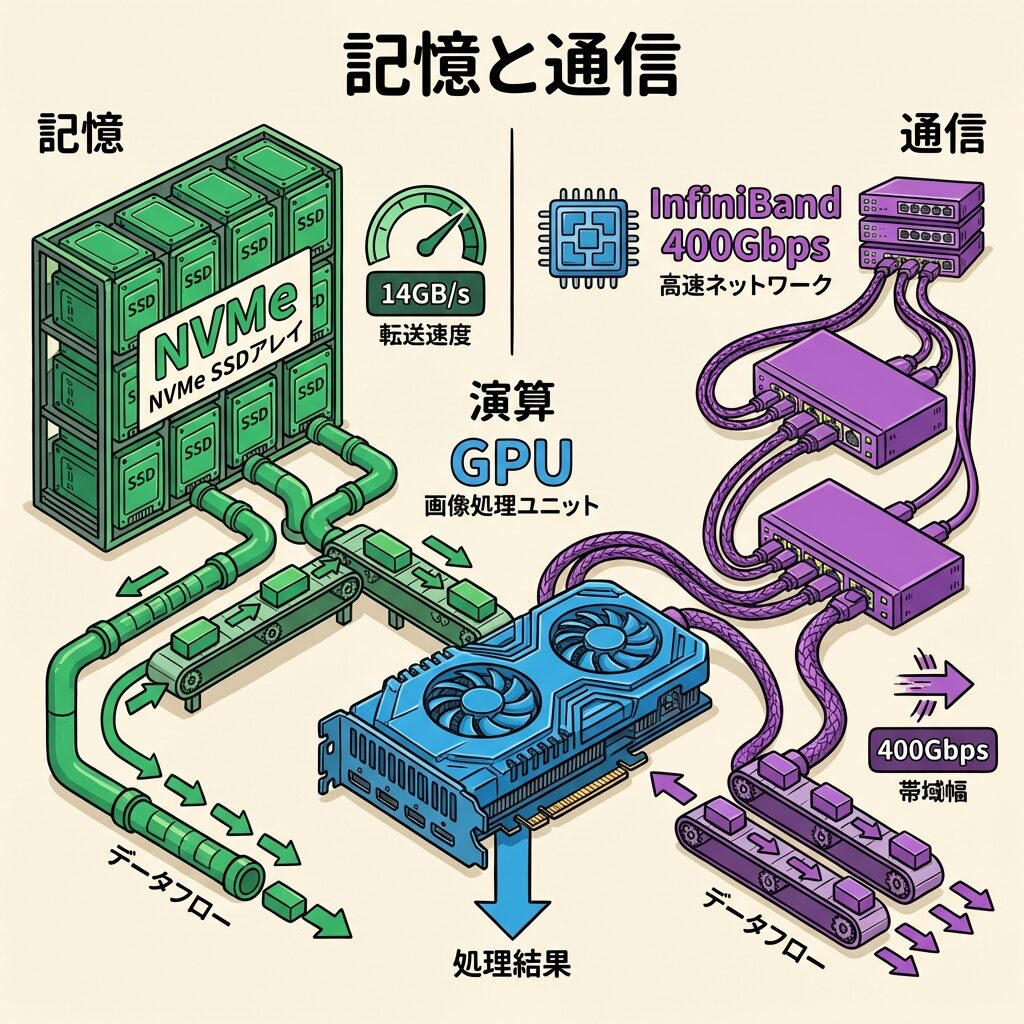
AIデータセンターでは、従来のHDD(ハードディスク)ではデータの読み出し速度が追いつきません。NVMe SSD(超高速フラッシュストレージ)が標準となっており、1台のストレージデバイスで最大14GB/sの転送速度を実現します。さらにGPUDirect Storageという技術により、ストレージからGPUへCPUを介さず直接データを転送することで、ボトルネックを解消しています。
NVMe(Non-Volatile Memory Express)は、SSDの性能を最大限引き出すための高速通信規格です。従来のSATA接続SSDと比べて読み書き速度が5〜10倍高速で、AI学習に必要な大量データの転送に不可欠です。
③ ネットワーク(通信層)── AIの「神経網」
🌐 数千台のGPUを超低遅延でつなぐ
AIの学習では、数千台のGPUが同時に計算し、その結果を瞬時に共有しながら進みます。この「GPU同士の通信」が遅いと、いくらGPUが高速でも全体の処理が詰まってしまいます。ネットワークは「GPU同士をつなぐ神経網」であり、ボトルネックになりやすい要素です。
AIデータセンターのネットワークは、大きく3つの階層で構成されています。
NVLink:サーバー内のGPU同士を超高速で接続。帯域は最大1.8TB/s。1台のサーバー内で完結する最も高速な接続。
InfiniBand / 高速Ethernet:サーバー間を400〜800Gbpsの超広帯域で接続。AI学習のスケールアウトに不可欠。
Ethernet / 光DCI:データセンター外部との通信。ユーザーからの推論リクエストや、他DCとの接続。
NVIDIAが提供する超高速・超低遅延のサーバー間接続規格。AI学習に最適化されており、400〜800Gbpsの帯域を持ちます。従来のEthernet(TCP/IP)よりも通信遅延が大幅に少なく、GPU同士の大量データ交換に適しています。
GPUが「調理チーム」、ストレージが「食材倉庫」だとすると、ネットワークは「食材を倉庫から各調理台まで運ぶベルトコンベア」です。どれだけ優秀なシェフがいても、食材が届かなければ料理は作れません。ベルトコンベアが遅ければ、チームは手持ち無沙汰になる──ネットワークがボトルネックになるとはそういうことです。
④ 電源設備(電力層)── AIの「心臓」
⚡ 数百MW級の電力を「1秒も止めず」安定供給する
AIデータセンターは24時間365日稼働し、膨大な電力を消費します。大規模施設では数百MW(メガワット)──大型火力発電所1基に匹敵する電力が必要です。この電力を安定して供給するのが電源設備の役割です。
Uninterruptible Power Supply(無停電電源装置)。停電が発生した瞬間にバッテリーから電力を供給し、非常用発電機が起動するまでの数十秒〜数分を「つなぐ」装置です。
Power Distribution Unit(電力分配ユニット)。UPSから受けた電力を、サーバーラック1本1本に適切に分配する「配電盤」のような役割を持つ設備です。
⑤ 冷却設備(排熱層)── AIの「体温調節」
❄️ GPUの猛烈な発熱を制御する「生命維持装置」
GPUサーバーの消費電力のほとんどは「熱」に変わります。ラック1本で120kW──電気ストーブ120台分の熱が発生し続けるのです。この熱を処理しなければ、GPUは動作温度を超えて故障します。冷却設備は、AIデータセンターの「生命維持装置」です。
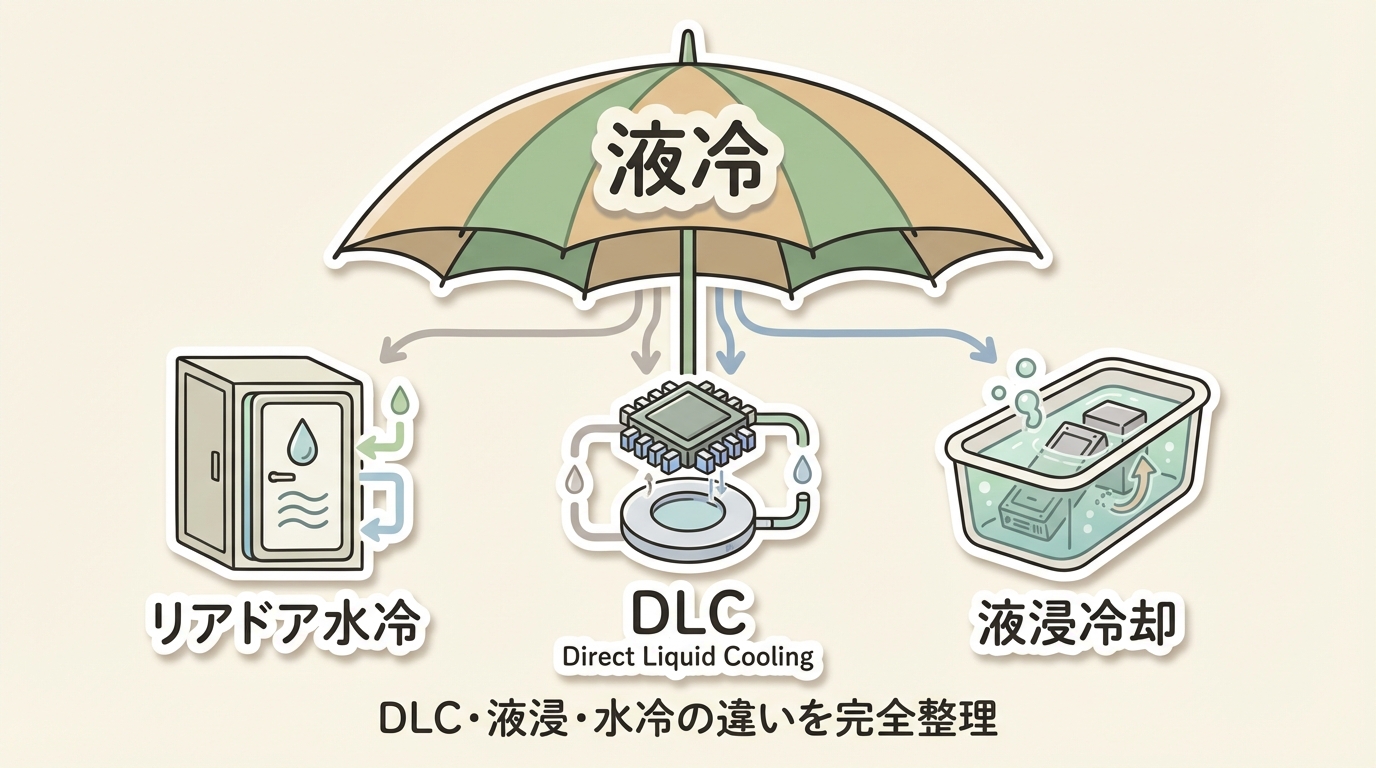
冷却方式には空冷と液冷があり、AIデータセンターではDLC(直接液冷)と空冷のハイブリッドが現在の主流です。液冷7:空冷3の比率が一般的な目安です。
空冷と液冷の違いとは? →
液冷とは?DLC・液浸冷却の違い →
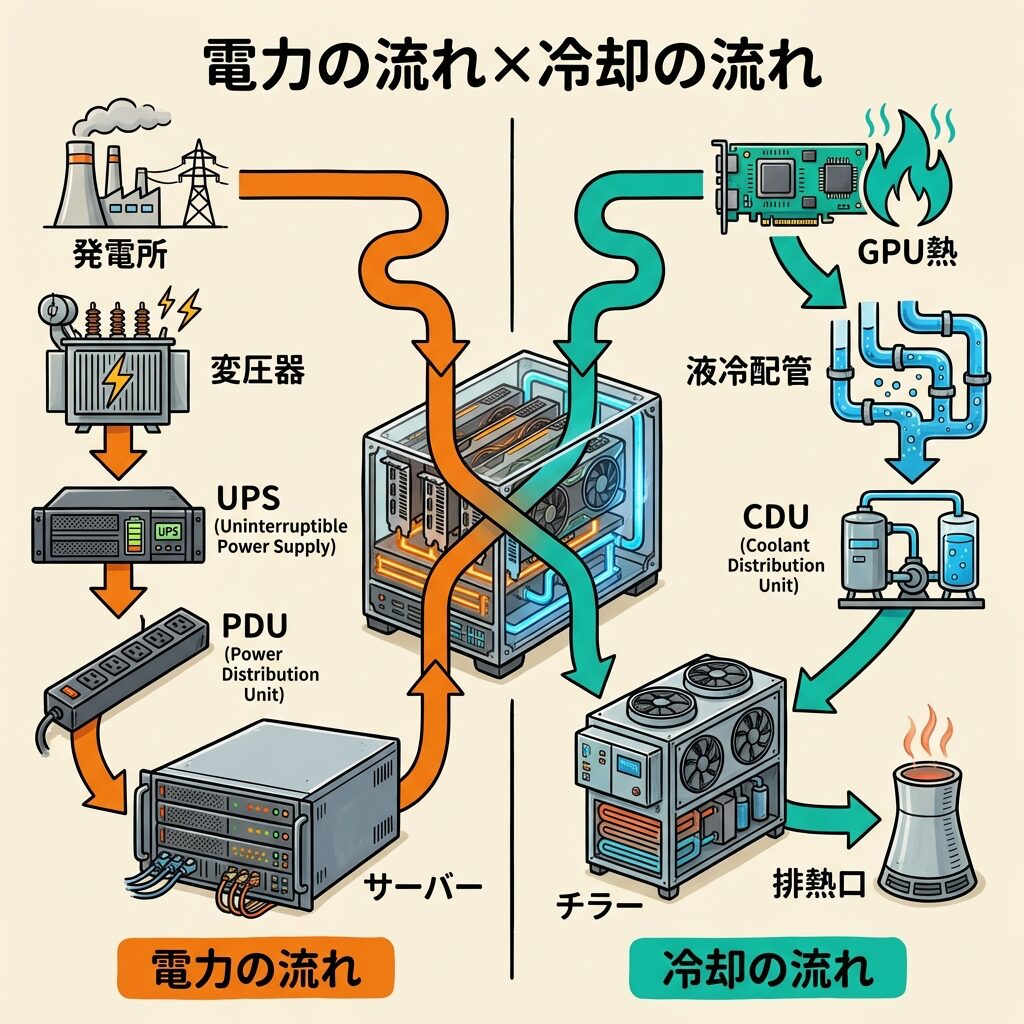

2つの流れで理解する ── データの流れ vs 電力の流れ
AIデータセンターの中を流れているものは、大きく2つあります。「データ」と「電力」です。この2つの流れを並べて見ると、5つの構成要素がどう関係しているかが一目でわかります。
学習データ・モデルを保存
データをGPUに転送
学習・推論を実行
ユーザーに応答を返す
高圧電力を受電
安定化+バックアップ
電力を消費 → 発熱
発熱を処理・排出
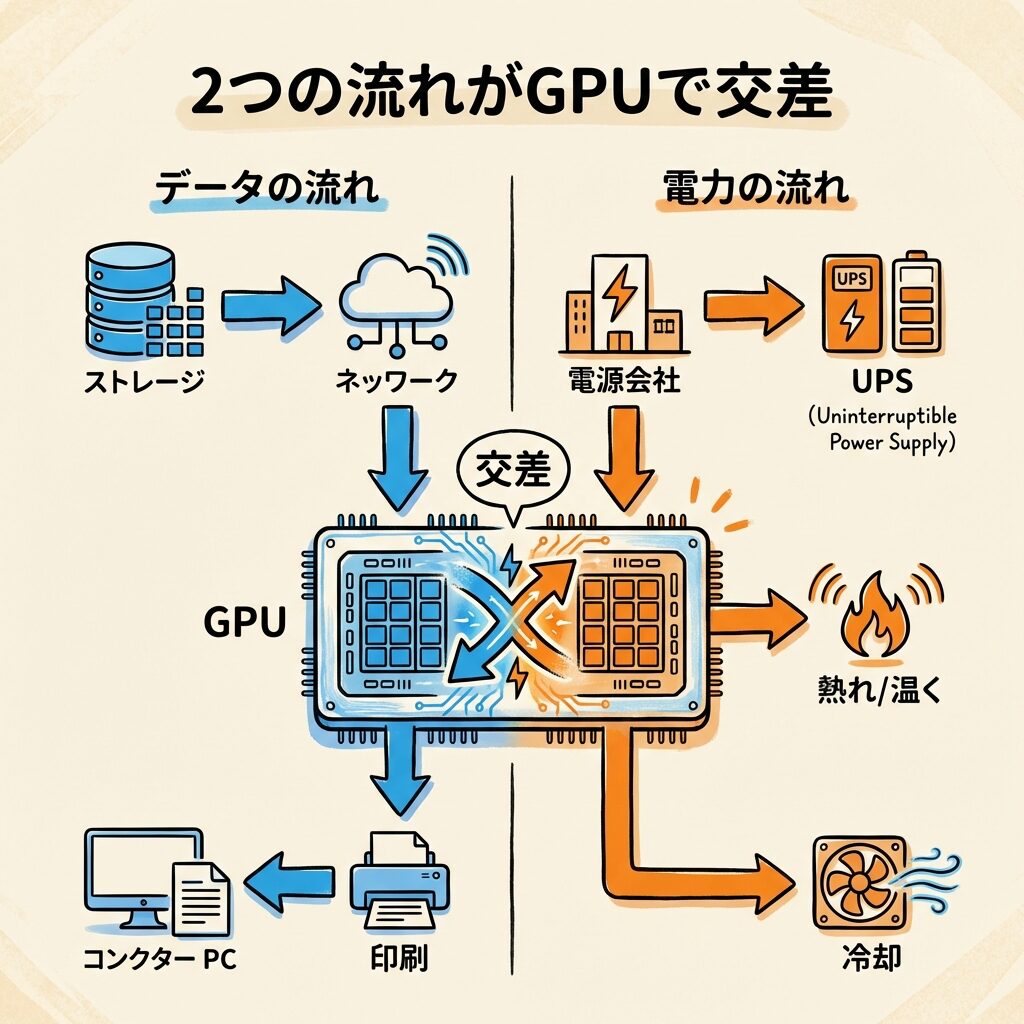
GPUサーバーは「データの流れ」と「電力の流れ」が交差する唯一のポイントです。GPUが動くにはデータ(入力)と電力(エネルギー)の両方が必要。そして動いた結果として「計算結果(出力)」と「熱(廃棄物)」が生まれる。だからGPU以外の4要素がすべて揃わなければ、GPUは動けないのです。
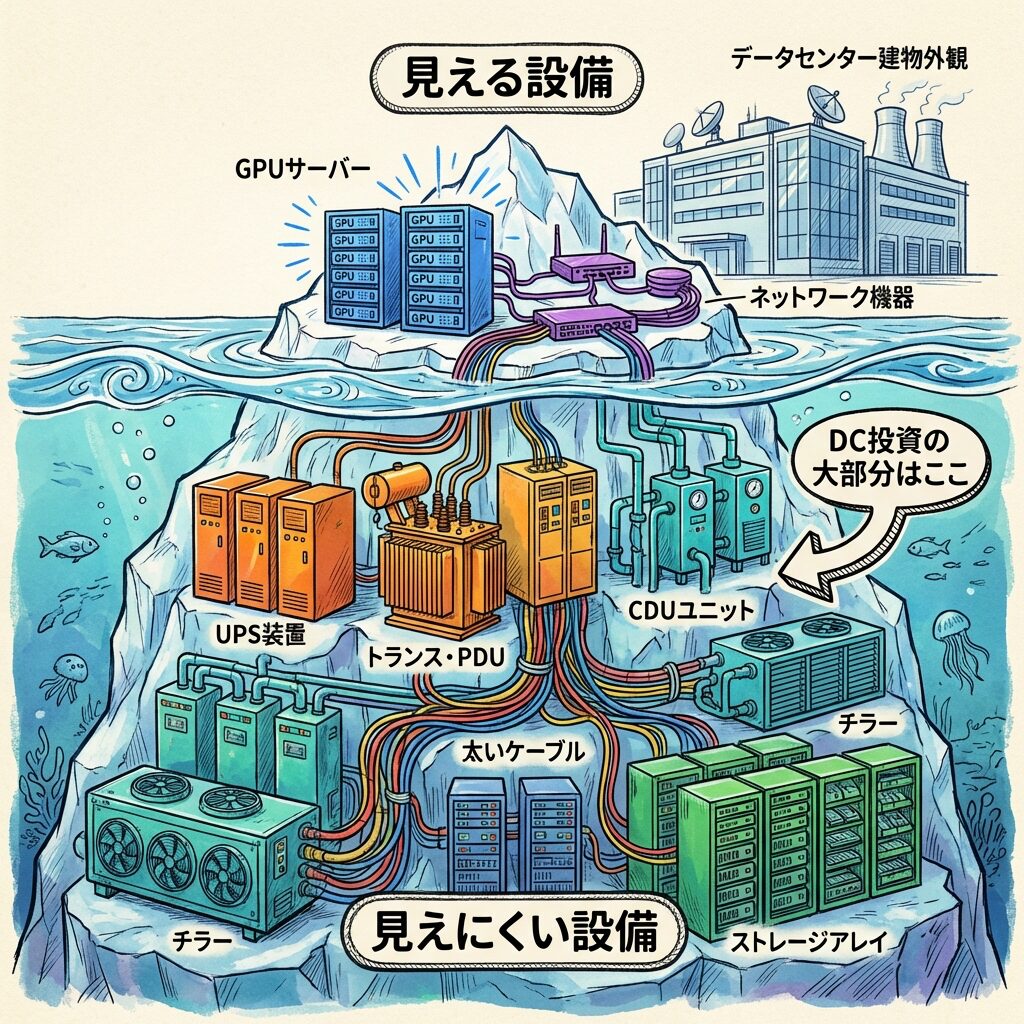
「見える設備」と「見えにくい設備」── ニュースに出ない裏方たち
AIデータセンターのニュースは、ほとんどが「GPU」の話です。しかし実際には、ニュースに登場しない「見えにくい設備」がデータセンターの大部分を占めています。
👁️ 見える設備 vs 👁️🗨️ 見えにくい設備
ニュースに出る「見える設備」
投資家・メディアの注目はここに集中
ニュースに出にくい「見えない設備」
実はDC投資額の大部分はこちら。技術者の需要もここ。
「AIデータセンター=GPUサーバーの集まり」と思われがちですが、GPUサーバーはデータセンターの構成要素のほんの一部です。電源・冷却・ネットワーク・ストレージ・ラック・ケーブルなど「見えにくい設備」がDC建設コストの大部分を占めており、それらを設計・施工・運用できる技術者こそが最も不足しているのです。
投資家:「NVIDIA(GPU)」だけがAI投資テーマではありません。受変電設備(富士電機)、UPS(富士電機、シュナイダー)、冷却設備(ニデック、ダイキン、カンネツ)、ラック(日東工業)、ケーブル(フジクラ、古河電工)──「見えにくい設備」の企業群にも構造的な需要があります。
学生:AIデータセンターの5要素を見れば、情報系だけでなく電気・機械・建築・材料の知識がどう活きるかがわかります。「自分の専門がAI時代に不要になるのでは?」と不安な方こそ、この全体図を見てください。
技術者:受変電、冷却、配管、施工管理──「見えにくい設備」を設計・運用できるのはあなたしかいません。ソフトウェアエンジニアにはできない、物理インフラの仕事がAI時代に最も求められています。
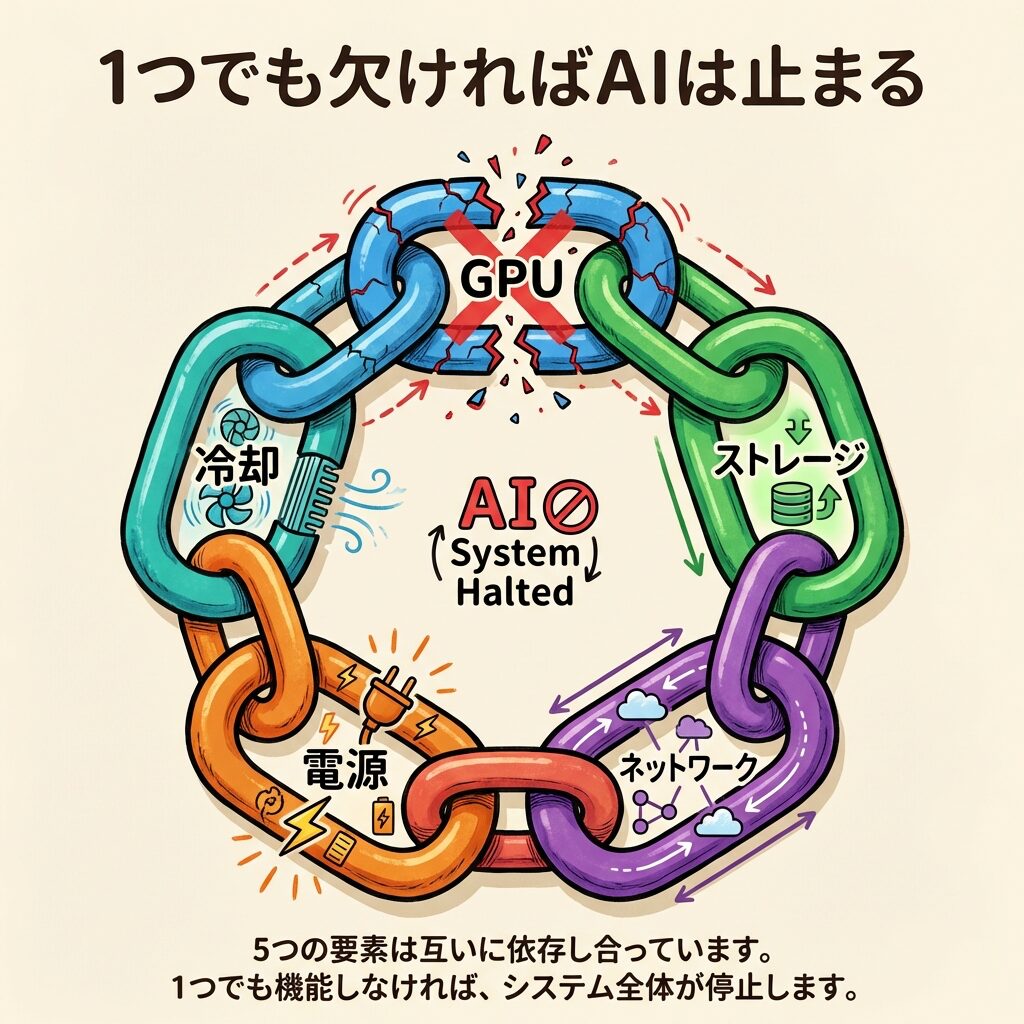
なぜ「1つ欠けても」AIは止まるのか?
5つの構成要素はバラバラに存在しているのではなく、因果関係で鎖のようにつながっています。どれか1つが止まると、連鎖的に全体が止まります。
→ GPUに学習データが届かない → 計算ができない → AI学習が停止
→ GPU同士が計算結果を共有できない → 分散学習が破綻 → 全GPUが手持ち無沙汰
→ すべての機器が停止 → 学習途中のモデルがロスト → 数週間分の計算が無駄に
→ GPU温度が急上昇 → 安全装置が自動停止 → 最悪の場合、数億円のGPUが損傷
→ 学習時間が数倍に延びる → 競合に遅れる → AIサービスの市場投入が遅延
5つの要素は「あれば便利」ではなく、すべてが「必須」です。最も弱い部分がシステム全体の性能を規定する──これを「律速段階」と言います。AIデータセンターでは今、電源(系統接続)と冷却が最大の律速段階になっています。
まとめ:AIデータセンターの構成要素の全体像
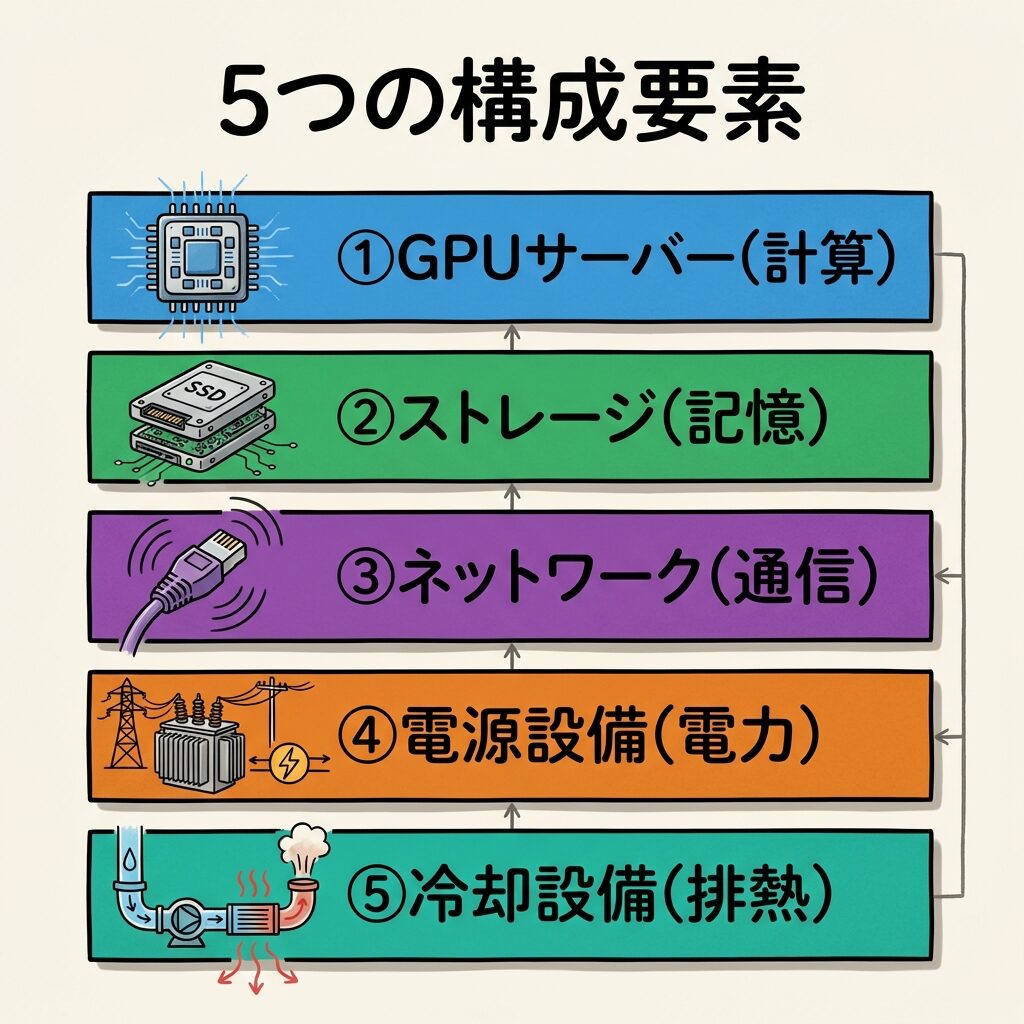
① 5つの構成要素:GPUサーバー(計算)、ストレージ(記憶)、ネットワーク(通信)、電源設備(電力供給)、冷却設備(排熱処理)。
② GPUサーバー:AIの学習・推論を実行する頭脳。消費電力は従来CPUの10倍以上。これが他の4要素すべてを桁違いに変えた起点。
③ ストレージ:NVMe SSDが標準。GPUDirect Storageで直接GPUにデータ供給。「食材倉庫」の速度がAI学習の効率を左右。
④ ネットワーク:NVLink(GPU間)→InfiniBand(サーバー間)→Ethernet(外部接続)の3層構造。遅いと全GPUが手持ち無沙汰に。
⑤ 電源設備:受変電→UPS→PDU→サーバーの順で電力を供給。数百MW級。1秒も止められない。
⑥ 冷却設備:DLC+空冷のハイブリッドが主流。GPUの消費電力の大部分は熱に変わり、冷却が止まればGPUは壊れる。
⑦ 2つの流れ:データの流れ(ストレージ→NW→GPU→出力)と電力の流れ(電力会社→UPS→GPU→発熱→冷却)がGPUで交差する。
⑧ 1つも欠けられない:5要素は鎖のようにつながっている。最も弱い部分が全体の律速段階。今は電源と冷却がボトルネック。
結局こういうことです。AIデータセンターは「GPUの集まり」ではありません。計算・記憶・通信・電力・排熱の5つが、1つも欠けることなく、すべて桁違いのスペックで揃って初めて機能するシステムです。この「1枚の地図」を手に入れたことで、これまでの個別記事(GPUサーバー、GPUラック、PUE、電力問題、空冷・液冷)がすべてつながったはずです。

❓ よくある質問(FAQ)
📚 次に読むべき記事
①計算層を深掘り。CPUとGPUの違い、消費電力、構成を図解で理解。
GPUサーバーが「ラック」に集積されたときに何が起きるか。120kWの衝撃。
⑤冷却層の効率を測る指標。電源と冷却の関係が数字で理解できます。
⑤冷却層を深掘り。空冷20kWの壁と液冷の必然性を図解で理解。
液冷の3方式(リアドア・DLC・液浸)の違いと使い分けを比較表で整理。
🗺️ 学習ロードマップ上の位置づけ
AIデータセンターの構成要素(この記事)
HBM(高帯域幅メモリ)とは?── 公開準備中
📩 記事の更新情報を受け取りたい方へ
新しい記事が公開されたら、Xアカウント @shirasusolo でお知らせします。AIインフラの構造を一緒に学んでいきましょう。

コメント