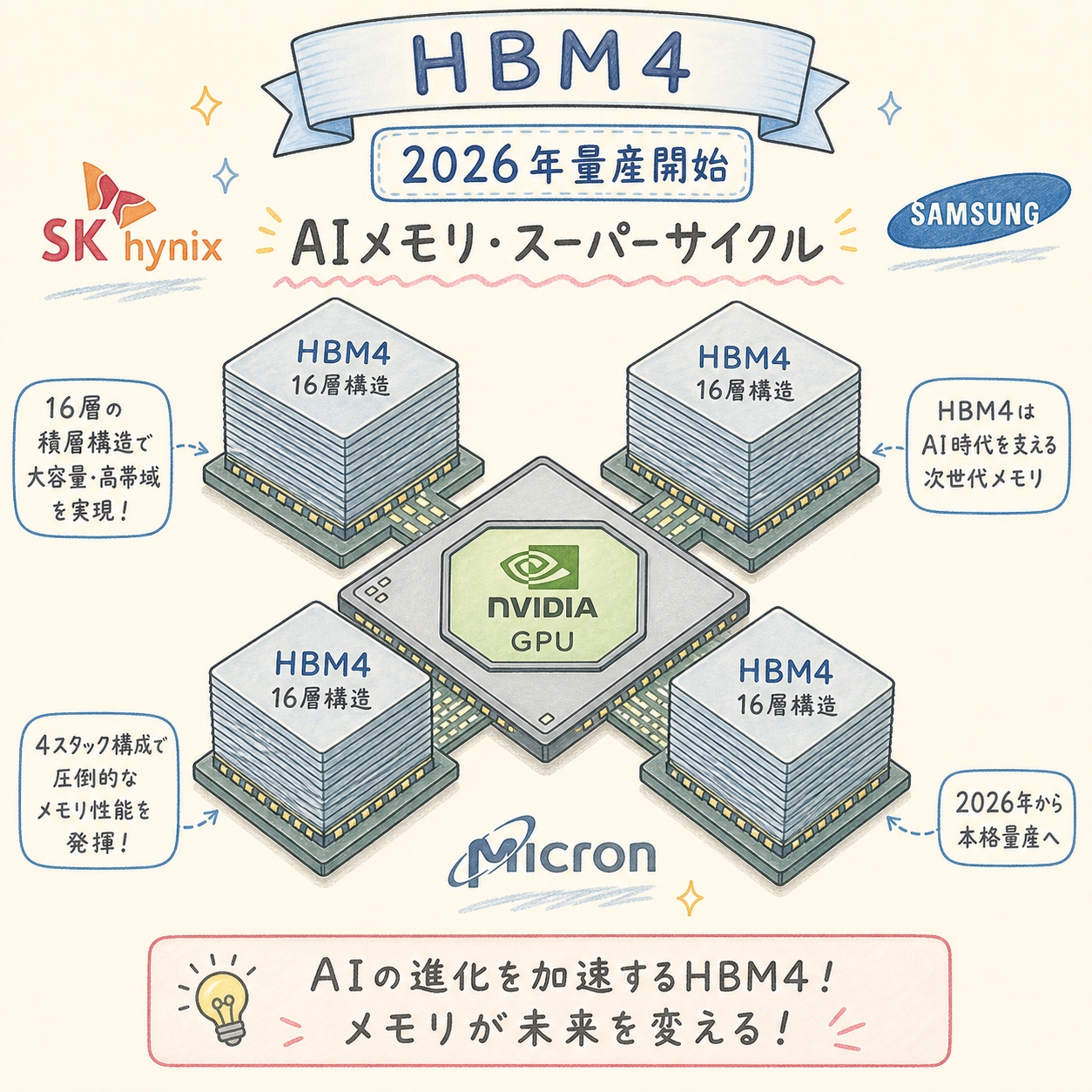
2026年、AIメモリは新時代に入りました。「HBM4」という言葉、最近のSK HynixやSamsung、NVIDIAのニュースで頻繁に登場するようになりましたよね。でも、こんなふうに感じていませんか?
- HBM3EとHBM4って何が違うの?「世代が変わった」だけ?
- 「バス幅が2倍」「16層積層」と聞いても、何がすごいのかピンとこない
- SK Hynix・Samsung・Micronの量産レース、結局どこが勝っているの?
- 「ベースダイにTSMC 3nm」って何の話?なぜTSMCが出てくるの?
- 投資家としてこのニュースを”次の一手”にどう活かせばいいかわからない
- HBM4の3つの新しさ(2048bitバス幅・ロジック統合ベースダイ・16層積層)
- HBM3EとHBM4の性能差を数値で完全比較
- SK Hynix・Samsung・Micronの量産レース最新状況(2026年3月時点)
- なぜTSMC 3nmがHBM4のベースダイに使われるのか
- NVIDIA Vera Rubinとの連動で起きる「メモリ・スーパーサイクル」の構造
- 投資家・学生・技術者にとっての意味と行動指針
HBM4とは、2025年4月にJEDECが規格を最終決定し、2026年に量産開始した第6世代の広帯域メモリです。最大の進化は3つ:①インターフェース幅が1024bit→2048bitに倍増、②ベースダイにTSMC 12nm(SK Hynix)/Samsung 4nm(Samsung)などロジック先端プロセスを採用、③スタックあたり最大2TB/sの帯域幅・最大64GB容量を実現。NVIDIAの次世代GPU「Vera Rubin」(2026年〜)の中核メモリとして採用される予定で、これがAIメモリ「スーパーサイクル」の主役となります。Samsungが2026年2月12日に「業界初」を称してHBM4量産開始を発表、Micronも2026年3月に量産出荷を開始、SK Hynixも量産準備を完了させ、3社の覇権争いが本格化しています(出典:EE Times Japan)。
この記事では「HBM4とは何か」を技術仕様だけでなく、3社の競争構造・サプライチェーン・投資判断まで含めて構造的に解説します。
📖 【完全図解】HBMとは?GPUの隣にある「AI最重要メモリ」を初心者向けに解説 →
HBMの定義・3D積層の仕組み・TSV・インターポーザーの基礎を先に押さえると、HBM4の進化が3倍わかります。
- HBM4とは?──まず定義と位置づけを30秒で理解する
- HBM3E vs HBM4|何がどう変わったのか
- HBM4の新しさ①|バス幅が1024bit→2048bitに「倍増」
- HBM4の新しさ②|ベースダイに「ロジック先端プロセス」を採用
- HBM4の新しさ③|12層積層から「16層積層」へ
- 3社の量産レース最新状況(2026年3月時点)
- NVIDIA Vera Rubinとの連動で起きる”スーパーサイクル”
- HBM4関連企業マップ|サプライチェーン3層で整理する
- あなたにとっての意味|投資家・学生・技術者の視点
- HBM4についてよくある誤解を整理する
- まとめ|HBM4を6点で整理する
- ❓ よくある質問(FAQ)
HBM4とは?──まず定義と位置づけを30秒で理解する
📖 HBM4 = 第6世代 High Bandwidth Memory(2026年量産開始)
HBM4とは、JEDEC(半導体技術の国際標準化団体)が2025年4月に最終仕様を策定し、2026年から量産が始まった第6世代の広帯域メモリ規格です。NVIDIAの次世代AI GPU「Vera Rubin」(2026年〜)の中核メモリとして採用される予定で、AIメモリ業界の「次の主役」と位置づけられています(出典:Introl)。
Joint Electron Device Engineering Council(電子デバイス技術合同会議)。半導体メモリの国際規格を策定する業界団体。HBM、DDR、LPDDRなど主要メモリ規格はすべてJEDECが標準化している。
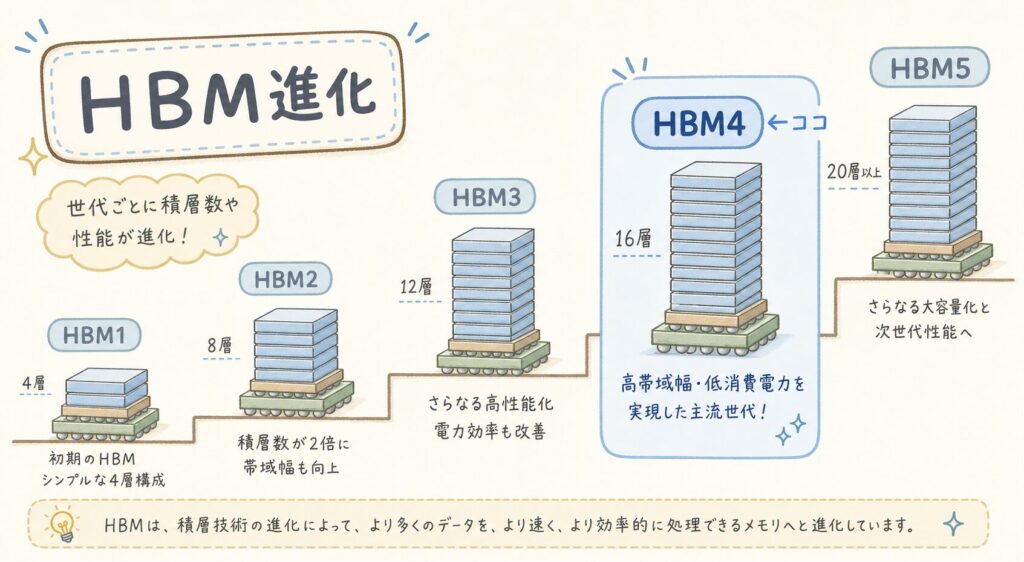
📅 HBM世代進化マップで位置を確認する
HBM1(2013年)から数えて約13年で帯域幅は約16倍に進化しました。HBM3E→HBM4の変化は、単なる世代交代ではなく、「同じ世代内で容量と速度が大きく跳ね上がる転換点」として業界で位置づけられています。
HBM3Eが「高速道路4車線」だとしたら、HBM4は「8車線に拡幅した高速道路」です。さらに、各車線の制限速度も上がっている。同じ時間に運べるデータ量がほぼ2倍になります。AI学習・推論で必要なデータ量が指数的に増えている今、この「道路拡幅」が業界全体の成長を左右します。
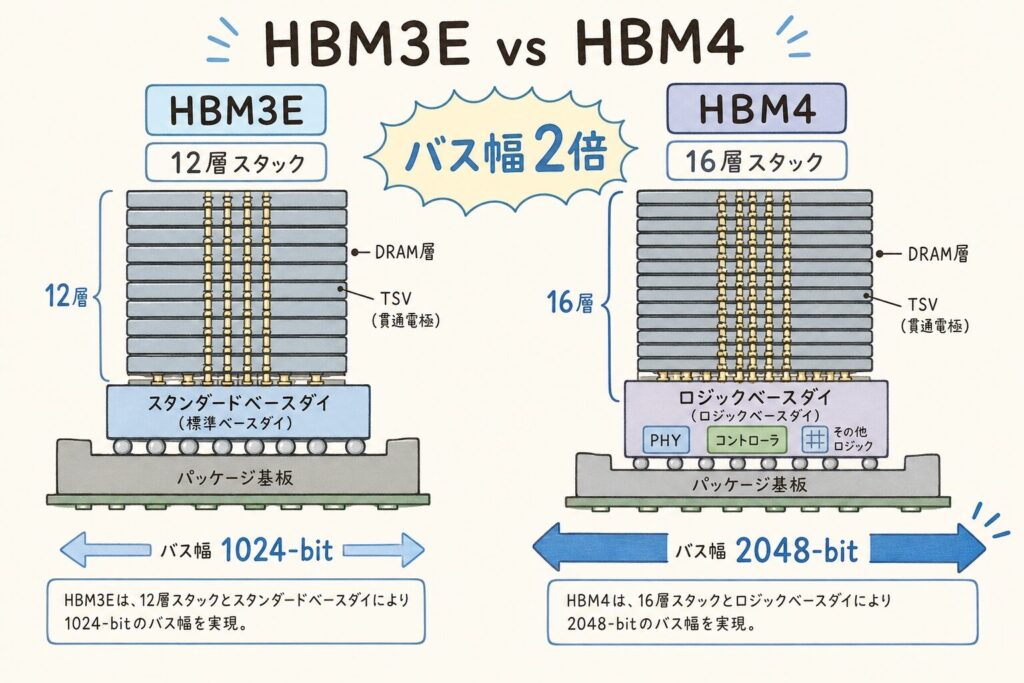
HBM3E vs HBM4|何がどう変わったのか
📊 主要スペック比較表
HBM3EとHBM4の違いを、JEDEC公式仕様とMicron・SK Hynixの公表値に基づいて整理します。
| スペック | HBM3E(現行) | HBM4(次世代) | 向上率 |
|---|---|---|---|
| インターフェース幅 | 1,024 bit | 2,048 bit | ×2倍 |
| チャネル数 | 16チャネル | 32チャネル | ×2倍 |
| ピンあたり速度 | 9.6 Gbps | 8〜11 Gbps以上 | 同等〜1.15倍 |
| スタック帯域幅 | 1.2 TB/s | 2.0〜2.8 TB/s | ×1.7〜2.3倍 |
| 最大積層数 | 12層(12-Hi) | 16層(16-Hi) | ×1.33倍 |
| スタック容量 | 24〜36GB | 36〜64GB | ×1.5〜1.8倍 |
| ベースダイ製造プロセス | DRAMプロセス | ロジック先端プロセス (TSMC 12nm/Samsung 4nm) |
構造変化 |
| 電力効率 | 基準 | 30〜40%削減 | 大幅改善 |
出典:JEDEC HBM4規格(2025年4月発表)、Micron HBM4公式、PC Watchを基に構成
注目すべきは「電力効率30〜40%削減」です。AI推論の電力問題が深刻化する中、HBM4は性能2倍+消費電力削減という、性能と省エネを両立した世代です。これがNVIDIA Vera Rubinの大幅な性能向上の土台となります。
HBM4の新しさ①|バス幅が1024bit→2048bitに「倍増」
🛣️ 「データの通り道」が2倍になった
HBM4最大の物理的変化は、インターフェース幅が1024bitから2048bitに倍増したことです。これがHBM4のすべての性能向上の出発点になっています。
1回のサイクルでメモリとGPU間に流せるビット数。バス幅が広いほど、同じ時間に多くのデータを運べる。HBM4の2048bitは、一般的なDDR5メモリ(64bit)の32倍のデータを同時転送できる「超広帯域バス」。
📊 数値で見るバス幅倍増のインパクト
T&Mコーポレーションの解説によると、バス幅を広げることで「1ビットあたりの動作周波数を抑えつつ高速転送を維持できる」ため、HBM3E比で30〜40%の電力削減が見込まれます(出典:T&Mコーポレーション)。
例えるなら「2車線の道路を時速100kmで走る」のと「4車線の道路を時速50kmで走る」のは、同じ時間に運べる荷物量が同じです。しかし、エンジンの回転数が低い後者のほうが燃費がいい。HBM4はこの「広くて遅め」の設計で、AIサーバーの消費電力問題に対応しています。
HBM4の新しさ②|ベースダイに「ロジック先端プロセス」を採用
🧠 メモリの底に「TSMC 12nm」「Samsung 4nm」が入る衝撃
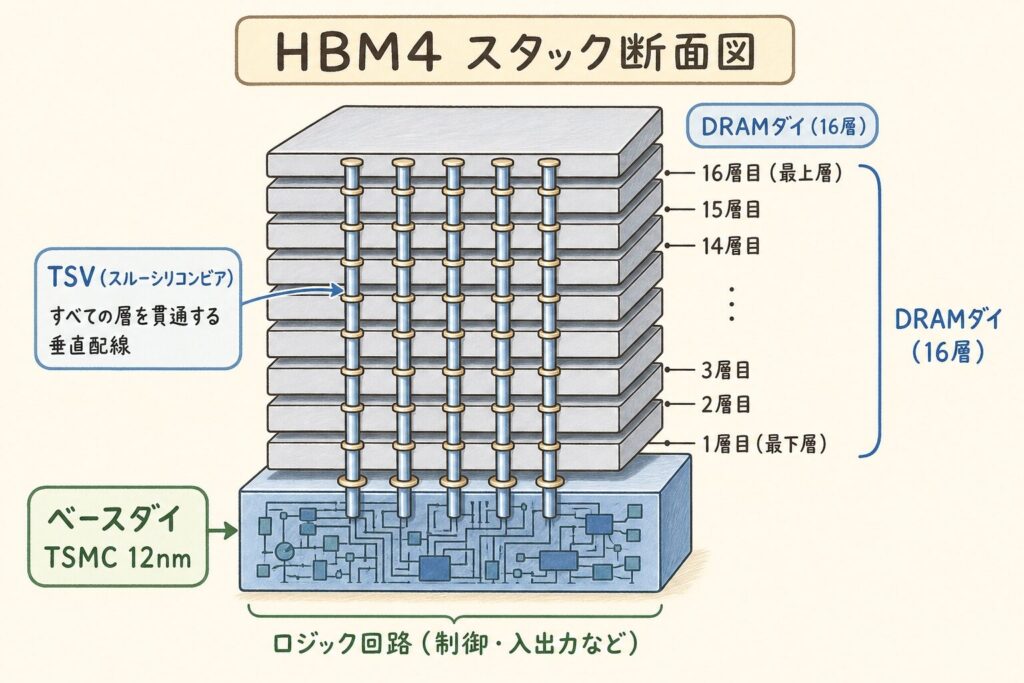
HBM4の最も革命的な変化は、スタックの最下部にある「ベースダイ」に、ロジック半導体の先端プロセス(TSMCの12nmやSamsungの4nmなど)を採用したことです。これまでのHBMはベースダイもDRAMプロセスで作られていましたが、HBM4から大きく変わりました。
HBMスタックの最下層にあるチップ。DRAMダイとGPUの間で信号を制御する「司令塔」の役割。HBM4ではここに先端ロジック機能(メモリ制御回路、I/O回路)を集積することで、性能と効率を大幅向上させる。
🏭 3社のベースダイ戦略
SK Hynix(000660.KS)
- TSMCとの戦略的提携
- HBM4Eでは3nm採用を検討
- NVIDIA向け供給で先行
Samsung(005930.KS)
- 自社ファウンドリの強み活用
- HBM4Eで2nm検討との報道
- 2026年2月「業界初」量産発表
Micron(MU)
- 2026年3月量産出荷開始
- 2.8TB/s超を公表
- NVIDIA供給継続を明言
出典:SK HynixのTSMC連携はChosunBiz、Samsung量産発表はEE Times Japan、MicronはChosunBizを参考
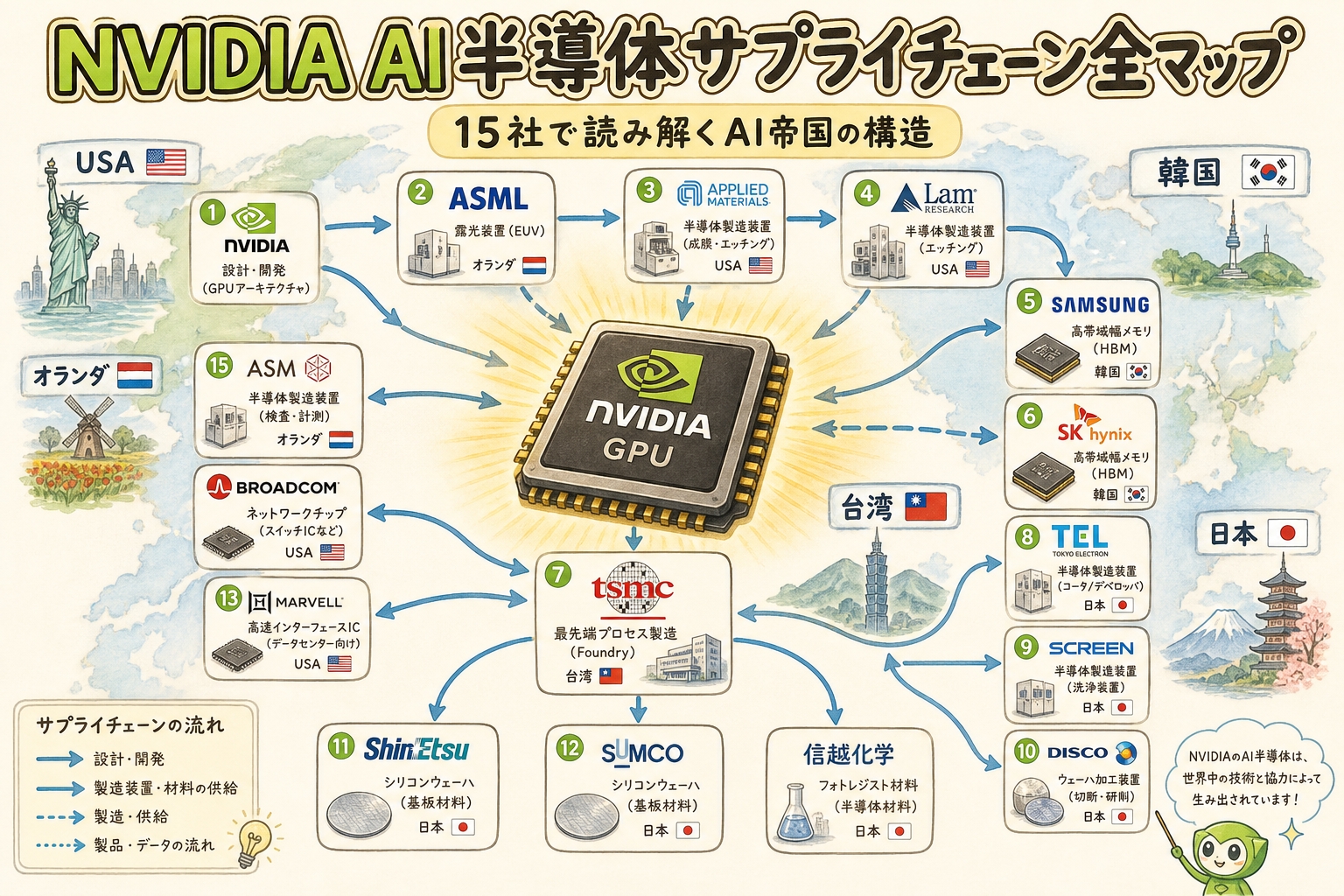
「HBMはメモリだから、メモリメーカーだけで作れる」と思われがちですが、HBM4ではSK Hynixが自社で全工程を完結できなくなりました。ベースダイをTSMCに製造委託する必要があり、これが業界構造を大きく変えています。「メモリ vs ファウンドリ」だった構図が「メモリ+ファウンドリの連合戦」へと変化したのです。
HBM4の新しさ③|12層積層から「16層積層」へ
🏗️ DRAMダイを「より高く積み上げる」技術革新
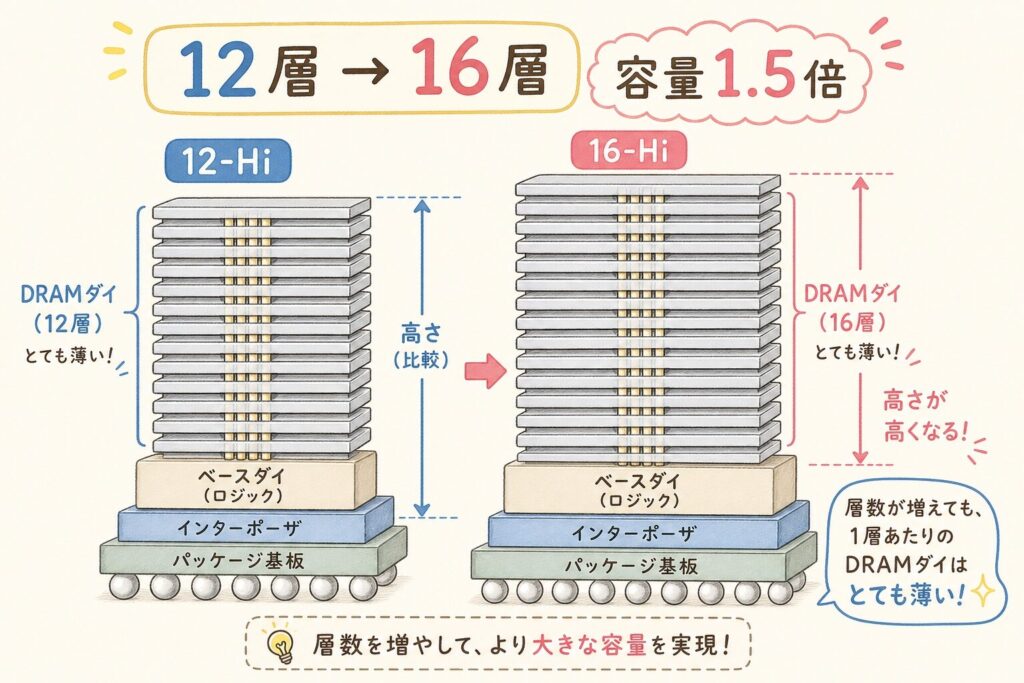
HBM4では、DRAMダイの積層数が12層(12-Hi)から16層(16-Hi)に拡張されます。スタック容量が最大64GBに達し、現行のHBM3E(36GB)と比較して約1.8倍の大容量化を実現します。SK HynixはCES 2026で16層48GBのHBM4を初公開しました(出典:Bloomberg)。
⚙️ 16層化を支える3つの製造技術
DRAMダイの極薄化
16層を積むには、各DRAMダイを物理的に薄くする必要があります。研磨技術(バックグラインド)で各ダイを約30μm以下まで薄くし、それでも電気特性を維持する精密制御が要求されます。
TCボンダーの高精度化
各ダイを熱と圧力で接合するTC(Thermal Compression)ボンダーが、16層分のミクロン単位の位置合わせを実現する必要があります。韓国ハンミ半導体(042700.KQ)が世界首位のシェアを持ちます。
熱管理の革新
16層に積み上げると、中央のダイから熱が逃げにくくなります。SK Hynixは独自の「MR-MUF」(液体素材を流し込んで一括硬化)技術で、熱伝導性と歩留まりを両立しています。
3社の量産レース最新状況(2026年3月時点)
🏁 HBM4量産レースのタイムライン
🥊 3社の競争マトリクス(2026年3月時点)
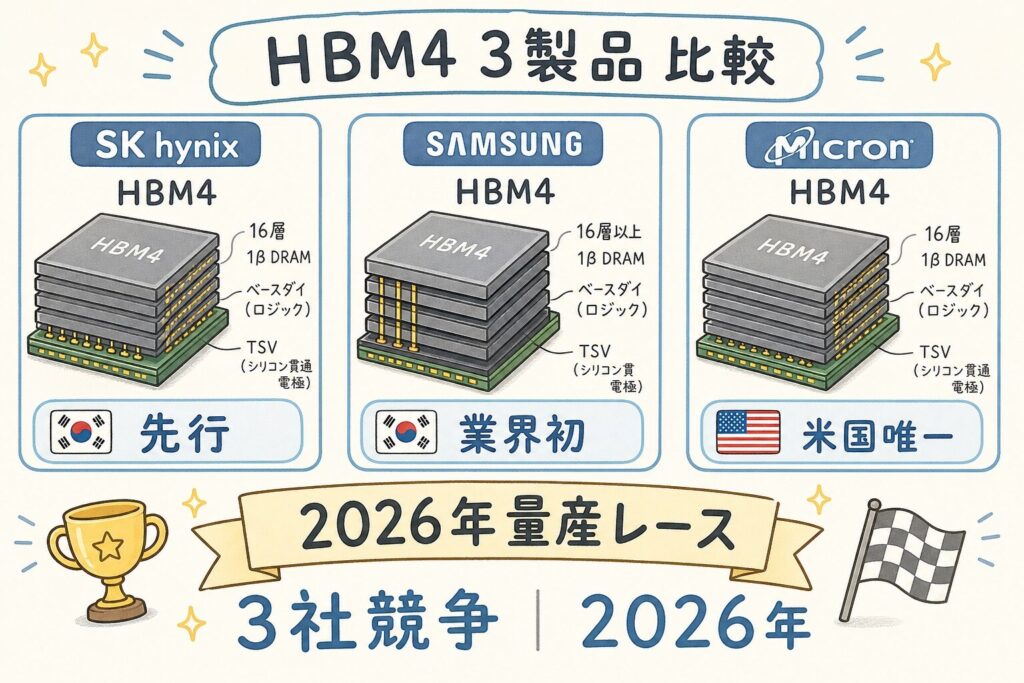
SK Hynix(000660.KS)
- HBM3Eで圧倒的シェア
- NVIDIA最大供給者
- 歩留まり業界最高水準
- HBM4も先行供給
Samsung(005930.KS)
- HBM4で「業界初」量産発表
- 自社4nmベースダイ採用
- NVIDIA認証を確保
- HBM4で巻き返し本格化
Micron(MU)
- 2026年3月量産開始
- 2.8TB/s帯域幅を公表
- NVIDIA向け供給継続
- 米国唯一のHBMメーカー
HBM3Eで圧倒的だったSK Hynix、HBM4で「業界初」を狙うSamsung、米国の砦Micron。3社が同時にHBM4量産に成功したのは業界初であり、過去のHBM世代以上に競争が激化しています。NVIDIAは複数サプライヤー化を進めており、3社それぞれに供給機会が生まれる構造です。
NVIDIA Vera Rubinとの連動で起きる”スーパーサイクル”
🚀 HBM4はVera Rubin(2026年〜)の心臓部
HBM4が量産元年を迎える2026年は、NVIDIAの次世代AI GPUプラットフォーム「Vera Rubin」がデビューする年でもあります。HBM4はVera Rubinの中核メモリとして採用される予定で、両者は表裏一体の関係にあります。
⚡ なぜ「スーパーサイクル」と呼ばれるのか
業界専門メディアと投資家が2026年を「メモリ・スーパーサイクル」と呼ぶ理由は、HBM4を起点に複数の構造要因が同時に重なるからです。
HBM需要の急増
NVIDIA Vera Rubin・AMD MI400・Google TPUなど、AI GPU各社がHBM4の大量採用を計画。需要が供給を大きく上回る見通し。
汎用DRAMへの波及
3社がDRAM生産能力をHBMに集中させた結果、汎用DRAMが供給不足に。TrendForceは2026年Q2のDRAM契約価格が58〜63%上昇と予測(出典:Digital Today)。
サプライチェーン全体への波及
HBMの製造には先端パッケージ(TSMC CoWoS)、検査装置(アドバンテスト)、TCボンダー(ハンミ半導体)、ABF基板(イビデン)、研磨装置(ディスコ)など多数の関連企業が必要。HBM4需要が業界全体を持ち上げる構造。
HBM4は「新型iPhoneの新色」のように単発で売れるものではなく、「家電量販店全体の客足を1〜2年間引き寄せ続けるアンカーテナント」のような存在です。HBM4そのものの市場規模も大きいですが、それ以上に関連サプライチェーン全体を持ち上げる効果が「スーパーサイクル」の本質です。
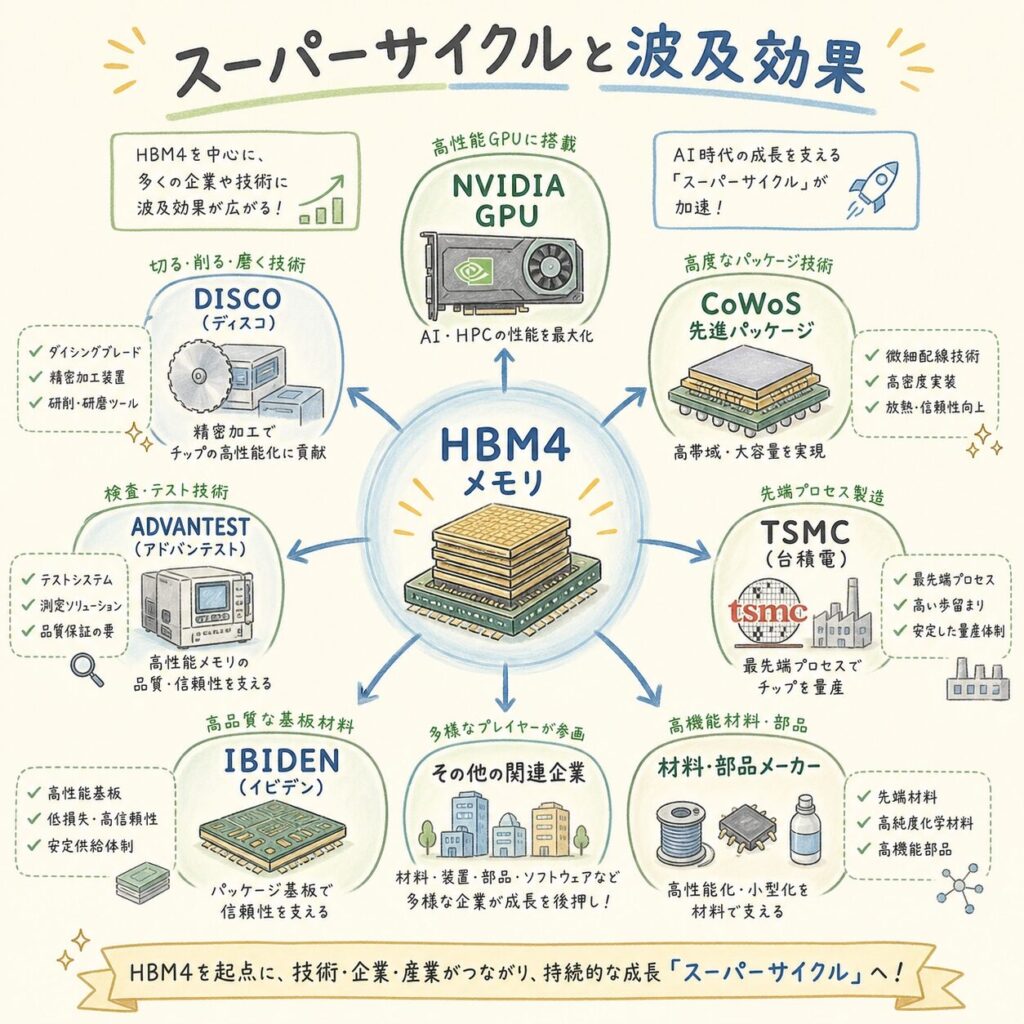
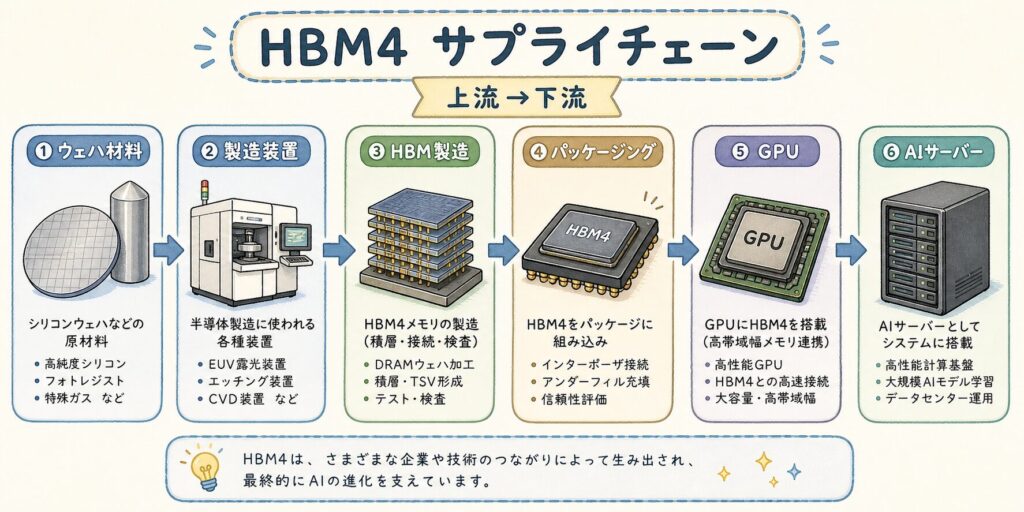
HBM4関連企業マップ|サプライチェーン3層で整理する
💼 上流(素材・装置)→ 中流(製造・パッケージ)→ 下流(GPU・ユーザー)
上流:素材・装置
- 信越化学(4063):シリコンウェーハ世界首位
- SUMCO(3436):シリコンウェーハ世界2位
- ハンミ半導体(042700.KQ):TCボンダー世界首位
- ディスコ(6146):研磨・ダイシング
- 東京エレクトロン(8035):成膜・エッチング装置
- レゾナック(4004):CMPスラリー・封止材
- 味の素(2802):ABFビルドアップフィルム
中流:HBM製造・パッケージ
- SK Hynix(000660.KS):HBM最大手
- Samsung(005930.KS):HBM4「業界初」量産
- Micron(MU):米国唯一のHBM
- TSMC(2330.TW):CoWoSパッケージング・HBM4ベースダイ
- イビデン(4062):ABF基板世界首位級
- アドバンテスト(6857):HBMテスター世界首位
- AIメカテック(6227):HBM関連検査装置
- 日本電子材料(6855):プローブカード
下流:GPU設計・ユーザー
- NVIDIA(NVDA):Vera RubinでHBM4採用予定
- AMD(AMD):Instinct MI400でHBM4採用
- Google(GOOGL):TPU向けにHBM4採用検討
- AWS(AMZN):Trainium向け検討
- Microsoft(MSFT):Maia向け検討
HBM4関連投資で見るべきは、メモリ3社だけではありません。上流の装置・素材(特に日本企業)がスーパーサイクルの構造的な恩恵を受けます。詳しくは別記事「HBM関連銘柄17選」で、各企業の役割と投資視点を整理します。
あなたにとっての意味|投資家・学生・技術者の視点
HBM4スーパーサイクルでは、「メモリ3社」だけでなく、その周辺サプライチェーン全体が動きます。SK Hynix(000660.KS)、Samsung(005930.KS)、Micron(MU)に加えて、TSMC(2330.TW・ベースダイ製造)、ハンミ半導体(042700.KQ・TCボンダー)、ディスコ(6146・研磨)、アドバンテスト(6857・検査)、イビデン(4062・ABF基板)、レゾナック(4004・素材)など、日本企業の上流ポジションを意識した投資視点が有効です。Samsungの「業界初」発表で短期的にSK Hynix一強が崩れる可能性も視野に。
HBM4は「メモリ技術」と「ロジック技術」が融合する象徴的な世代です。ベースダイにTSMC 12nm・Samsung 4nmを採用することで、従来の「メモリエンジニア」と「ロジックエンジニア」の境界が曖昧になっています。半導体メーカー(SK Hynix・Samsung・Micron・キオクシア)、装置メーカー(東京エレクトロン・ディスコ・アドバンテスト)、素材メーカー(信越化学・レゾナック・味の素ファインテクノ)すべてに就職機会が広がっています。研究室の研究テーマとして「3D積層の熱管理」「ハイブリッドボンディング」を選ぶ学生は、これから10年は需要が尽きません。
HBM4の16層化・2048bit化は、設計・製造・検査・実装のすべてに新しい技術課題を生んでいます。特に「熱管理」「歩留まり」「TCボンダー精度」「ベースダイ設計」は今後5年間の半導体産業の中核テーマです。ご自身の専門領域がHBMサプライチェーンのどこに位置するかを把握し、社内・社外で「HBM4でこの技術がボトルネックになる」と語れる人材は、組織内でのポジショニングが強くなります。

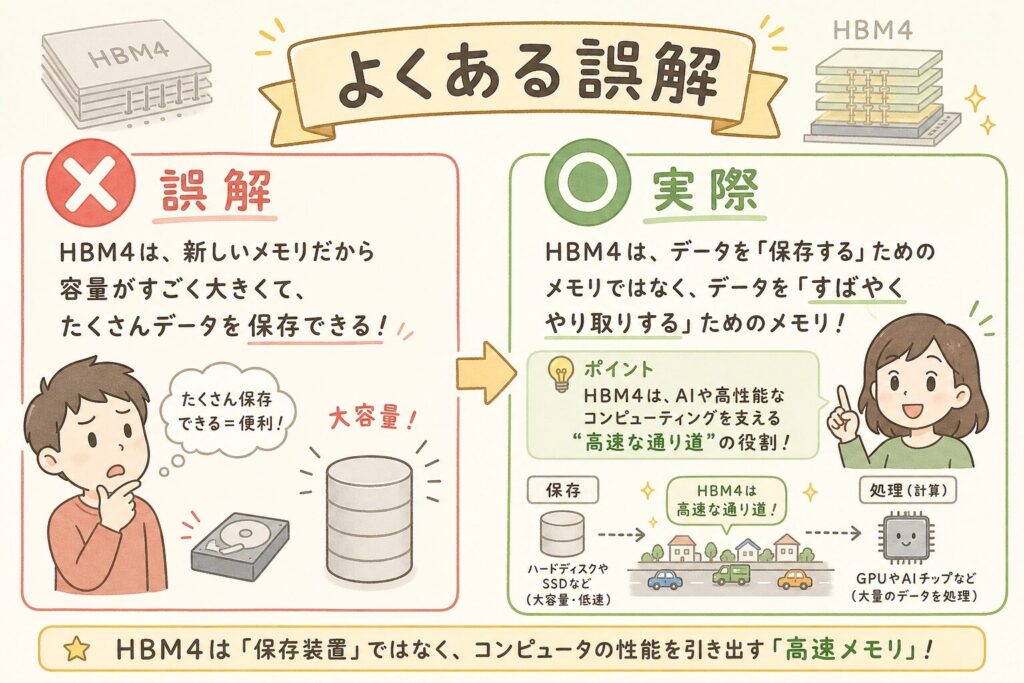
HBM4についてよくある誤解を整理する
| ❌ よくある誤解 | ✅ 実際はこう |
|---|---|
| 「HBM4はHBM3Eのマイナーチェンジ」 | バス幅倍増・ベースダイのロジック化・16層化と3つの根本的な変化を同時に実現。HBM3→HBM3E(マイナー)と異なる「メジャー世代交代」。 |
| 「HBM4はSK Hynixが圧倒的に先行する」 | 2026年2月にSamsungが「業界初」量産発表、3月にMicronも量産開始。3社が同時に量産レースに参入した初の世代で、勢力図は流動的。 |
| 「メモリの話だからメモリメーカーだけで完結する」 | ベースダイのロジック化により、TSMCの先端プロセス(12nm・3nm)が必須。HBM4はメモリ×ファウンドリの「合作品」となった。 |
| 「HBM4が出れば電力問題は解決する」 | HBM4単体の電力効率は30〜40%改善するが、NVIDIA Vera Rubinの絶対的な性能向上で消費電力は増加する。データセンター全体の電力問題は引き続き深刻。 |
| 「HBM4は2026年で完成形になる」 | SK HynixはHBM4Eに3nmベースダイを検討中。HBM5(2029年〜)、HBM5E(2031年〜)まで継続進化が予定されており、HBM4はあくまで通過点。 |
まとめ|HBM4を6点で整理する
① HBM4とは:2025年4月にJEDEC規格策定、2026年に3社が量産開始した第6世代の広帯域メモリ。NVIDIA Vera Rubinの中核メモリ。
② 3つの新しさ:①バス幅2048bit(HBM3Eの2倍)、②ベースダイにロジック先端プロセス(TSMC 12nm/Samsung 4nm)、③16層積層化で容量最大64GB。
③ 性能向上:スタック帯域幅2〜2.8TB/s(HBM3Eの約2倍)、容量1.5〜1.8倍、電力効率30〜40%改善。
④ 量産レース(2026年3月時点):Samsung(2/12量産発表)、Micron(3/17量産発表)、SK Hynix(量産準備完了)。3社同時参入は史上初。
⑤ スーパーサイクル:HBM4需要でDRAM全体に波及。2026年Q2のDRAM契約価格58〜63%上昇予測、汎用メモリ不足が2027年まで続く見通し。
⑥ サプライチェーン全体への恩恵:3社のHBMメーカーだけでなく、TSMC・ハンミ半導体・ディスコ・アドバンテスト・イビデン・レゾナック・味の素など、関連企業全体が「スーパーサイクル」の恩恵を受ける構造。
結局こういうことです。HBM4は「メモリのマイナーアップグレード」ではありません。AI半導体業界全体の構造を作り変える、メモリ×ロジック融合の象徴です。SK Hynixの先行、Samsungの巻き返し、Micronの参入、そしてTSMCとの連携──2026年はAIメモリの新しい競争秩序が始まる年です。
❓ よくある質問(FAQ)
📖 【完全図解】HBMとは?GPUの隣にある「AI最重要メモリ」を初心者向けに解説 →
HBMの定義・3D積層・TSV・インターポーザーの基礎を押さえると、HBM4の進化が3倍わかります。
📚 次に読むべき記事
HBM4で激化する3社競争の前提となる、各社のシェアと戦略を詳しく解説した記事です。
なぜHBM4が「普通のDRAMの延長線上」にないのか。基礎から理解するための比較記事。
HBM4とGPUを統合する先端パッケージ技術。Vera Rubinの心臓部を理解できます。
HBM4の本質的な背景である「半導体パッケージング革命」の全体像を俯瞰できます。
📩 記事の更新情報を受け取りたい方へ
新しい記事が公開されたら、Xアカウント @shirasusolo でお知らせします。AIインフラの構造を一緒に学んでいきましょう。

コメント