「NVIDIA GB300」「Blackwell Ultra」──2025〜2026年のAI半導体ニュースで急に見るようになったこのキーワード、こんなふうに感じていませんか?
- 「GB300」「B300」「Blackwell Ultra」──全部同じものなの?
- H100→H200→B200→GB300と進化が早すぎて、どこが何の世代かわからない
- 「HBM3E 288GB搭載」と聞いても、どれくらいすごいのか実感できない
- B200からGB300で「何が」「どれくらい」変わったのか整理したい
- SK Hynixの株価が動く理由、データセンター業界が騒ぐ理由を構造で知りたい
- GB300・B300・Blackwell Ultraの言葉の関係性を30秒で整理
- HBM3E 288GB・FP4 15 PFLOPS・TDP 1,400Wという怪物スペックの意味
- 「AI推論最強チップ」と呼ばれる理由を構造から理解
- GB300 NVL72──ラック1本150kWの完全液冷システム
- B200との違いを9項目で完全比較
- 次世代Vera Rubinまでのロードマップ
- 投資家・技術者・学生にとっての意味と注目ポイント
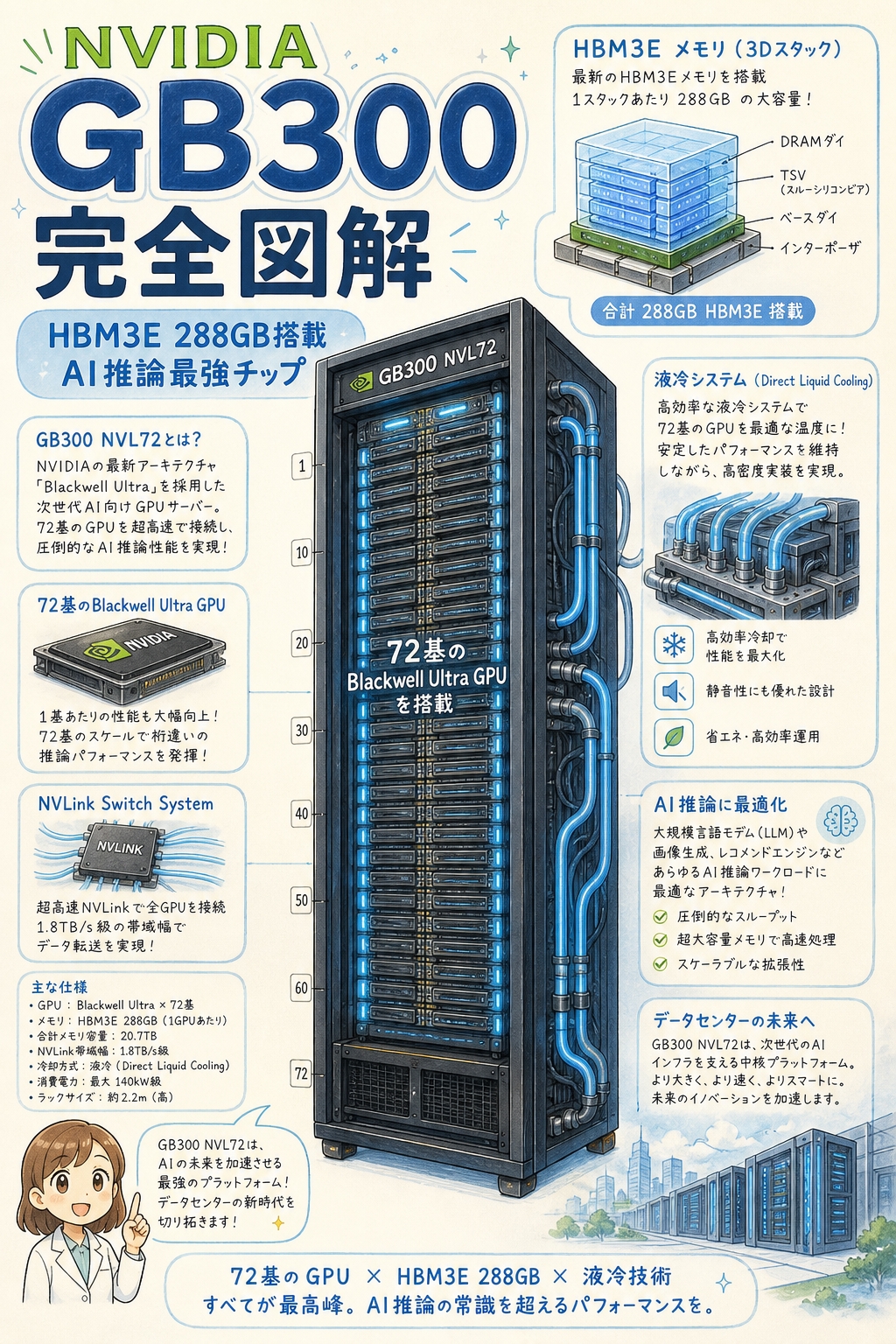
GB300(Blackwell Ultra)は、NVIDIAが2026年1月から量産出荷を開始した最新世代のAI GPUです。最大の特徴はHBM3E 288GB搭載(前世代B200の192GBから1.5倍)、FP4性能15 PFLOPS(B200の9 PFLOPSから1.55倍)、そしてTDP 1,400W(B200の1,000Wから1.4倍)。GB300は単体GPUの呼称、B300はGPUダイ単体、Blackwell Ultraはアーキテクチャ名、そしてGB300 NVL72は72個のGPUを1ラックに詰め込んだラックスケールシステムで、消費電力132〜150kW・重量1.5トン超の「完全液冷モンスター」。NVIDIAは週1,000台ペースで量産中で、Microsoft・Google・Meta・AWSなどハイパースケーラーが奪い合っています。GB300の登場で「AI推論(インファレンス)」性能が前世代Hopper(H100)の40倍に達し、ChatGPT級の大規模AI推論コストが激減──これがAI業界が騒ぐ本当の理由です。
この記事を読み終えたあと、あなたはGB300関連のニュースを「構造で読み解ける」ようになっています。NVIDIA決算、SK Hynix株価、データセンター電力問題──すべて1本の線でつながります。
- まず混乱を整理 ── B300、GB300、Blackwell Ultra、GB300 NVL72の違い
- GB300は「何世代目」か ── NVIDIA AI GPUロードマップで位置づけ
- GB300の中身を開ける ── 1個のチップに何が詰まっているか
- 【保存版】B200 vs GB300 ── 9項目で何が変わったか
- なぜ「AI推論最強」と呼ばれるのか ── Hopperの40倍の衝撃
- GB300 NVL72 ── 1ラックに72個のGPUを詰めた「モンスター」
- なぜGB300は「100%液冷」が必須なのか
- GB300を支えるサプライチェーン ── 誰が部品を作っているのか
- GB300は誰が買うのか ── ハイパースケーラーの争奪戦
- あなたにとっての意味──投資家・学生・技術者の視点
- よくある誤解を整理する
- まとめ:GB300の全体像
- ❓ よくある質問(FAQ)
まず混乱を整理 ── B300、GB300、Blackwell Ultra、GB300 NVL72の違い
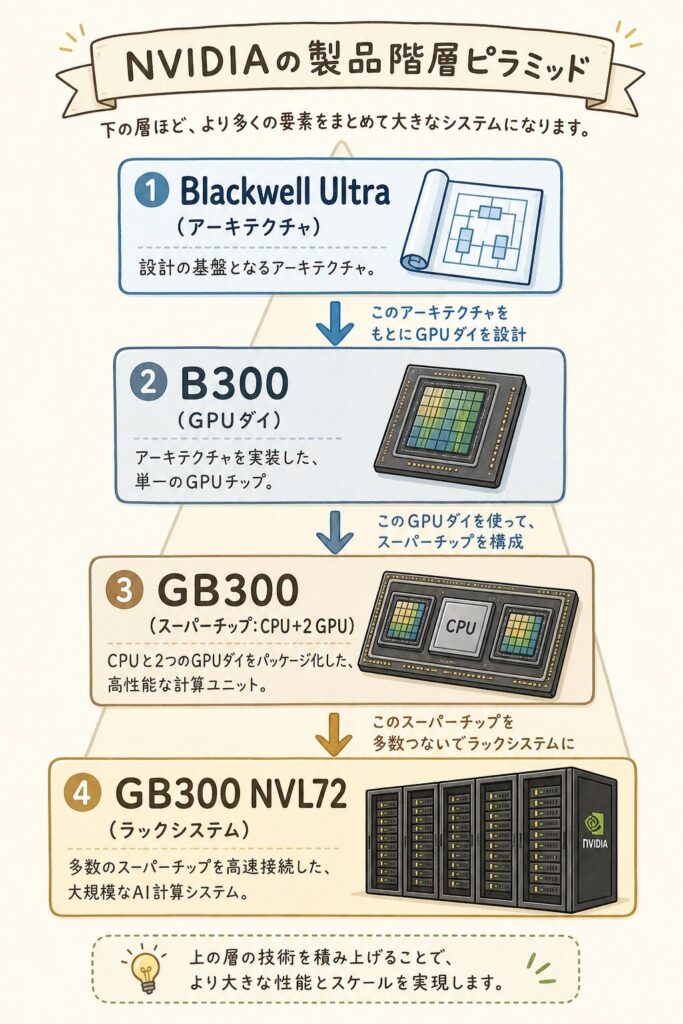
📖 似た言葉が4つある ── 何を指すのか30秒で理解
NVIDIAの最新世代を語るとき、4つの似た言葉が混在します。これを最初に整理しないと、ニュースを正確に読めません。
Blackwell Ultra
設計思想・回路アーキテクチャの名称。Blackwell世代の強化版。
B300
Blackwell Ultraアーキテクチャを採用したGPUチップそのもの。
GB300
B300×2基+Grace CPU×1基を1モジュールに統合した「スーパーチップ」。
GB300 NVL72
GB300×36個(B300 72基)を1ラックに詰めた完成品システム。
自動車に例えるとわかりやすいです。Blackwell Ultra=「エンジンの設計図」、B300=「エンジン本体」、GB300=「エンジン+トランスミッション一体ユニット」、GB300 NVL72=「そのユニットを72個積んだ完成車(モンスタートラック)」。同じBlackwell Ultraでも、どの粒度で語っているかで意味が変わります。
NVLinkで72個のGPUを接続したラックスケールシステムのこと。GB200 NVL72が前世代、GB300 NVL72が現行最新世代。1ラックに72個のB200/B300 GPUがNVLinkで超高速に接続され、まるで1つの巨大GPUのように動作する。
GB300は「何世代目」か ── NVIDIA AI GPUロードマップで位置づけ
📅 GB300は「Blackwell世代の強化版」── 5世代目のAI GPU
NVIDIAのデータセンター向けGPUは、約2年ごとに大型世代更新、その間に「強化版」を投入する戦略を取っています。GB300はBlackwell世代の強化版(Ultra)です。
HBM2e×5スタック・40〜80GB。AI研究用GPUの祖。ChatGPTの学習にも使われた。TDP 400W。
HBM3×5スタック・80GB・3.35TB/s。ChatGPTブームでAI GPUの代名詞に。TDP 700W。
HBM3E×6スタック・141GB・4.8TB/s。H100のメモリ大幅強化版。
2つのGPUダイ+HBM3E×8スタック・192GB。チップレット化の最初のNVIDIA GPU。CoWoS-L採用。TDP 1,000W。
HBM3E×8スタック・288GB・8TB/s。B200比でメモリ1.5倍、FP4性能1.55倍、AI推論特化で前世代Hopperの40倍の推論性能。TDP 1,400W。
HBM4採用予定。1チップTDP 2,300Wに到達予測。GB300比でさらに10倍効率を目標。

GB300の中身を開ける ── 1個のチップに何が詰まっているか
🔬 GB300スーパーチップの構成
GB300(正確にはGB300 Grace Blackwell Ultra Superchip)は、1つのモジュールに以下が統合されています。
36GB
36GB
(2つのダイ統合)
36GB
36GB
36GB
36GB
(2つのダイ統合)
36GB
36GB
合計:B300 GPU×2基 + Grace CPU×1基 + HBM3E 288GB
🔢 GB300の主要スペック一覧
| 項目 | スペック |
|---|---|
| アーキテクチャ | Blackwell Ultra |
| 製造プロセス | TSMC 4NPプロセス(CoWoS-L採用) |
| GPUダイ構成 | 2つのGPUダイをチップレットで統合(B300) |
| トランジスタ数 | 2,080億個(B200と同等) |
| HBM3E容量(GPU 1基あたり) | 288GB(HBM3E 36GB×8スタック) |
| HBM帯域幅 | 8 TB/s |
| FP4 Dense性能 | 15 PFLOPS |
| TDP(消費電力) | 1,400W |
| NVLink帯域 | 1.8 TB/s(5世代NVLink) |
| 統合CPU | NVIDIA Grace CPU(ARM v9・72コア) |
出典:NVIDIA公式、NVIDIA Developer Blog
288GBという数字、実感わきますか? 最新ゲーミングPC(RTX 4090)のVRAMが24GB。普通のサーバーCPUのメモリが128GB〜512GB。GB300 1基だけで、ハイエンドゲーミングPCの12台分・サーバー1台分のメモリを持っています。しかもこれは「メモリ」ではなく「GPUの隣に超高速で配置されたHBM」。普通のメモリと比べて読み書き速度が桁違いです。
📖 【完全図解】HBMとは?GPUの隣にある「AI最重要メモリ」を初心者向けに解説 →
なぜGPUの隣にHBMを置く必要があるのか、3D積層・TSV・帯域幅の仕組みを構造から解説。


【保存版】B200 vs GB300 ── 9項目で何が変わったか
📊 「強化版」と呼ばれる理由を数字で見る
GB300は「BlackwellのUltra(強化版)」と呼ばれます。何がどれだけ強化されたか、B200と並べて見ましょう。
| 比較項目 | B200(前世代) | GB300/B300(最新) | 向上率 |
|---|---|---|---|
| HBM容量 | 192GB | 288GB | 1.5倍 |
| HBM帯域幅 | 8 TB/s | 8 TB/s | 同等 |
| FP4 Dense性能 | 9 PFLOPS | 15 PFLOPS | 約1.55倍 |
| アテンション処理 | 基準値 | 2倍高速 | 2.0倍 |
| TDP(消費電力) | 1,000W | 1,400W | 1.4倍(注意) |
| NVLink帯域 | 1.8 TB/s | 1.8 TB/s | 同等 |
| パッケージング | CoWoS-L | CoWoS-L | 同等 |
| 主な狙い | 学習+推論バランス | 推論特化 | 用途変更 |
| 量産開始 | 2024年末 | 2026年1月 | 約1年後 |
💡 「メモリ容量」と「推論特化」がGB300の本質
9項目見比べると、GB300の本質的な変化は「メモリ容量1.5倍」と「推論特化」の2点に集約されます。なぜこの2つが重要なのか。
メモリ1.5倍 = 大規模モデルが「載る」
GPT-4・Llama 3.1 405Bなど超大規模AIモデルは、メモリに収まりきらないと「複数GPUに分散」が必要で速度が落ちる。288GBあれば、より多くのモデルが1GPU内に収まるようになり、推論速度が大幅向上。
推論特化 = ChatGPT級サービスのコスト激減
ChatGPT・Gemini・Claudeなどのサービスは、ユーザーへの「回答生成(=推論)」が膨大な計算量。GB300はFP4性能1.55倍+アテンション処理2倍で、推論コストを劇的に下げる。
AIの計算には2種類あります。学習(トレーニング)=AIモデルを作る作業、推論(インファレンス)=完成したモデルで回答を生成する作業。AIサービスが普及するほど、推論計算の量が爆発的に増えます。NVIDIAがGB300で「推論特化」を打ち出したのは、AI業界の重心が「学習」から「推論」に移っているからです。

なぜ「AI推論最強」と呼ばれるのか ── Hopperの40倍の衝撃
🚀 NVIDIA公式が示した「衝撃の数字」
NVIDIAのGTC 2025で、CEOジェンスン・フアン氏は驚きの数字を示しました──「GB300 NVL72は、DeepSeek R1のような推論モデルの処理で、前々世代Hopper(H100)の40倍の推論性能を発揮する」。
(Hopper比)
(推論速度)
(電力効率)
🧠 「推論モデル」の登場が業界を変えた
2025年初頭、OpenAI o1・DeepSeek R1・Claude 3.7 Sonnetなど、「考えてから回答するAI」(推論モデル)が登場しました。これらは回答前に「思考プロセス」を内部で展開するため、従来の数倍〜数十倍の計算量を必要とします。
従来のChatGPT(GPT-4)は「反射的に答える優等生」。推論モデル(o1・DeepSeek R1)は「じっくり考えてから答える哲学者」。哲学者は答えの質は高いけど、考えるのに時間と電力を食う。GB300は、この「哲学者」を高速で稼働させるために設計されたGPUです。
推論コストが10分の1になれば、ChatGPT・Gemini・Claudeなどのサービスが採算ベースで10倍のユーザーに提供できるようになります。NVIDIAがGB300を「AIファクトリーの中核」と呼ぶ理由は、AIサービスを「採算事業」として成立させる経済性をもたらすからです。
数値を表現するビット幅。FP32(32ビット)→FP16→FP8→FP4と少ないビットで計算するほど、同じ電力でより多くの計算ができる。AI推論ではFP4でも十分な精度が出せることが分かり、GB300はFP4性能を大幅強化することで推論を高速化した。


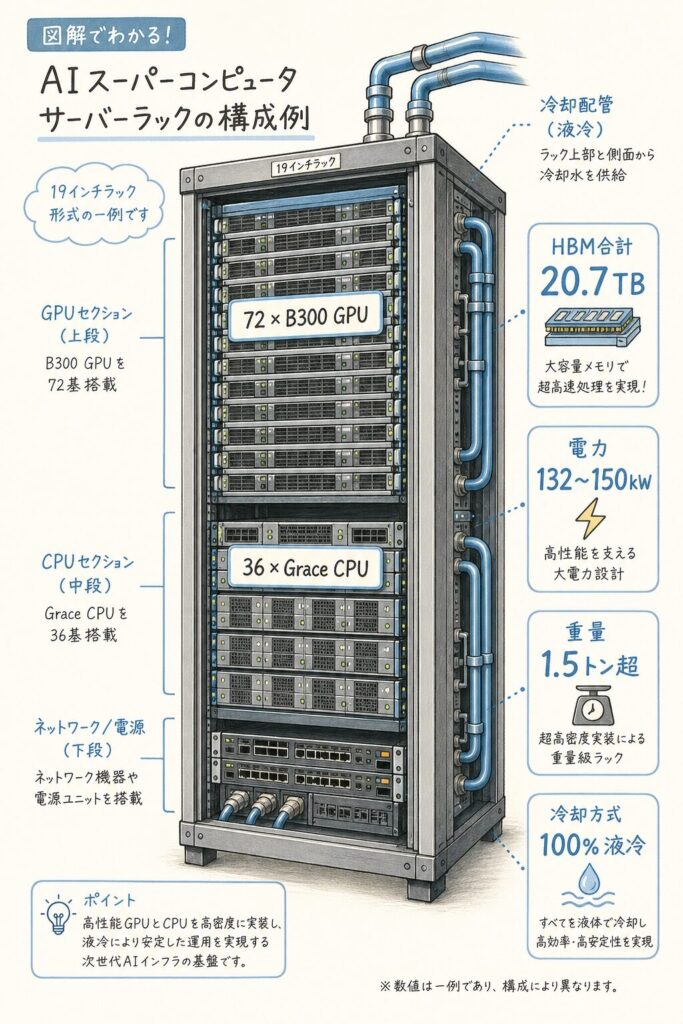
GB300 NVL72 ── 1ラックに72個のGPUを詰めた「モンスター」
🏢 ラックスケールシステムとは
GB300の真の威力は、単体GPUではなく「GB300 NVL72」というラックスケールシステムで発揮されます。これは1つの19インチラック(高さ約2m)に72個のB300 GPUと36個のGrace CPUを詰め込んだ完成品です。
総重量1.5トン超 / 100%液冷必須 / 1ラック価格約400〜500万ドル
📊 GB200 NVL72とGB300 NVL72の違い
| 項目 | GB200 NVL72(前世代) | GB300 NVL72(最新) |
|---|---|---|
| GPU構成 | B200×72 | B300×72 |
| HBM合計容量 | 13.8 TB | 20.7 TB(1.5倍) |
| FP4 Dense性能 | 720 PFLOPS | 1,100 PFLOPS(1.5倍) |
| 消費電力 | 約120 kW | 132〜150 kW |
| 冷却方式 | 100%液冷 | 100%液冷 |
| CPU構成 | Grace×36 | Grace×36 |
従来型データセンターのラック電力は2〜8kW。GB300 NVL72はその20〜75倍。一般家庭50世帯分の電力を、1ラックで消費します。これがAIデータセンターの電力問題・冷却問題の根本原因です。
📖 【完全図解】GPUラックとは?「高密度化」でデータセンターが変わる理由 →
ラック120kW級のGPUがデータセンター設計をどう変えたのか、構造から解説。
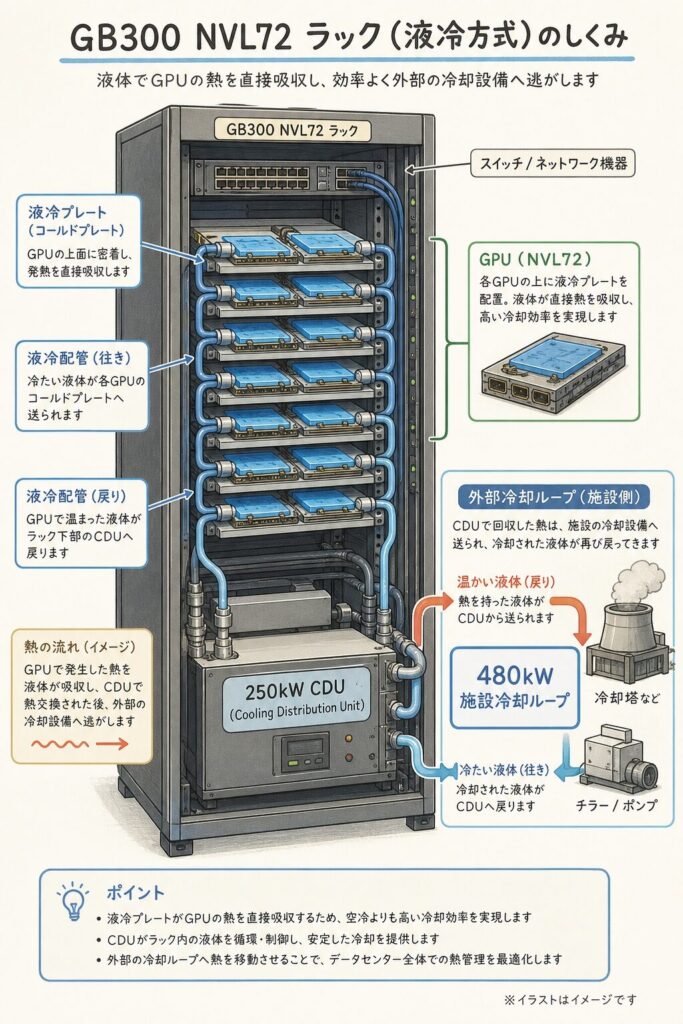
なぜGB300は「100%液冷」が必須なのか
❄️ 1,400Wのチップを冷やす ── 空冷では物理的に不可能
GB300はTDP 1,400W。1チップで電気ストーブ1.4台分の熱を出します。これを72基詰めたNVL72ラックは、合計100kW以上の発熱量になります。
1.5畳のスペース(19インチラック)に、電気ストーブを100台フル稼働させている状態を想像してください。エアコン(空冷)でこの熱を取れますか? 物理的に無理です。だから、水(または冷却液)を直接チップに当てて熱を奪う「液冷」しか選択肢がないのです。
💧 GB300 NVL72の液冷システム
GB300 NVL72は100%液冷(ダイレクト液冷/DLC)を採用しています。GPU・CPU・NVSwitchすべてに液冷プレートが直接取り付けられ、冷却液が循環します。
DLC(Direct Liquid Cooling)──冷却液がチップのすぐ上の金属プレートを直接冷やす。空冷の数十倍の冷却効率。
250kW CDU内蔵──Cooling Distribution Unit(冷却液分配ユニット)をラック内に統合。施設側の準備負担を軽減。
480kW級施設冷却ループ──データセンター側にも大規模な冷却水循環システムが必須。既存DCの大半は対応不可。
GB300の登場で、世界中のデータセンター事業者が「既存施設では物理的に置けない」事態に直面しています。新設DCは設計段階から液冷前提に、既存DCは大改修が必要──これがAIデータセンター建設ラッシュの根本原因です。
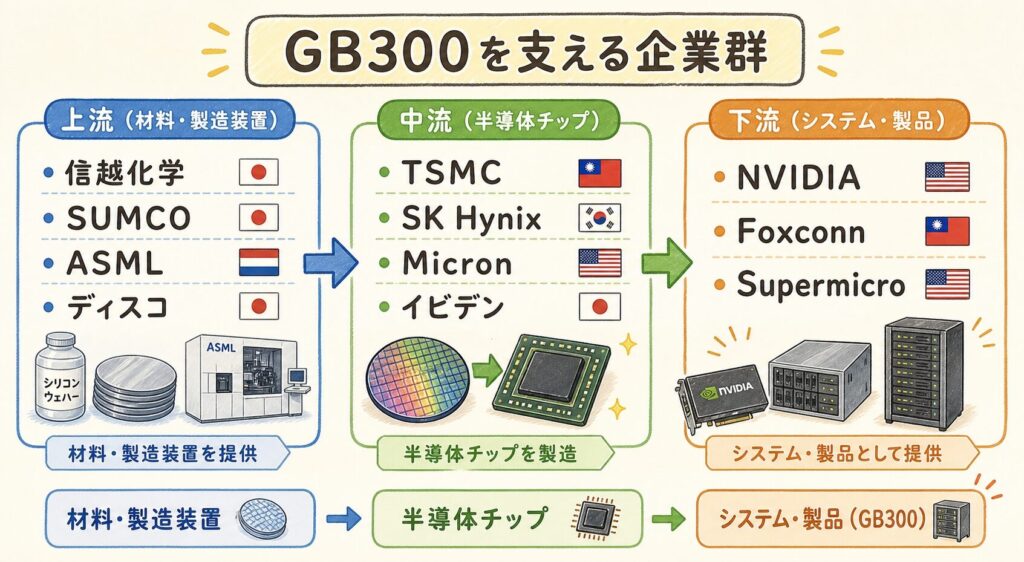
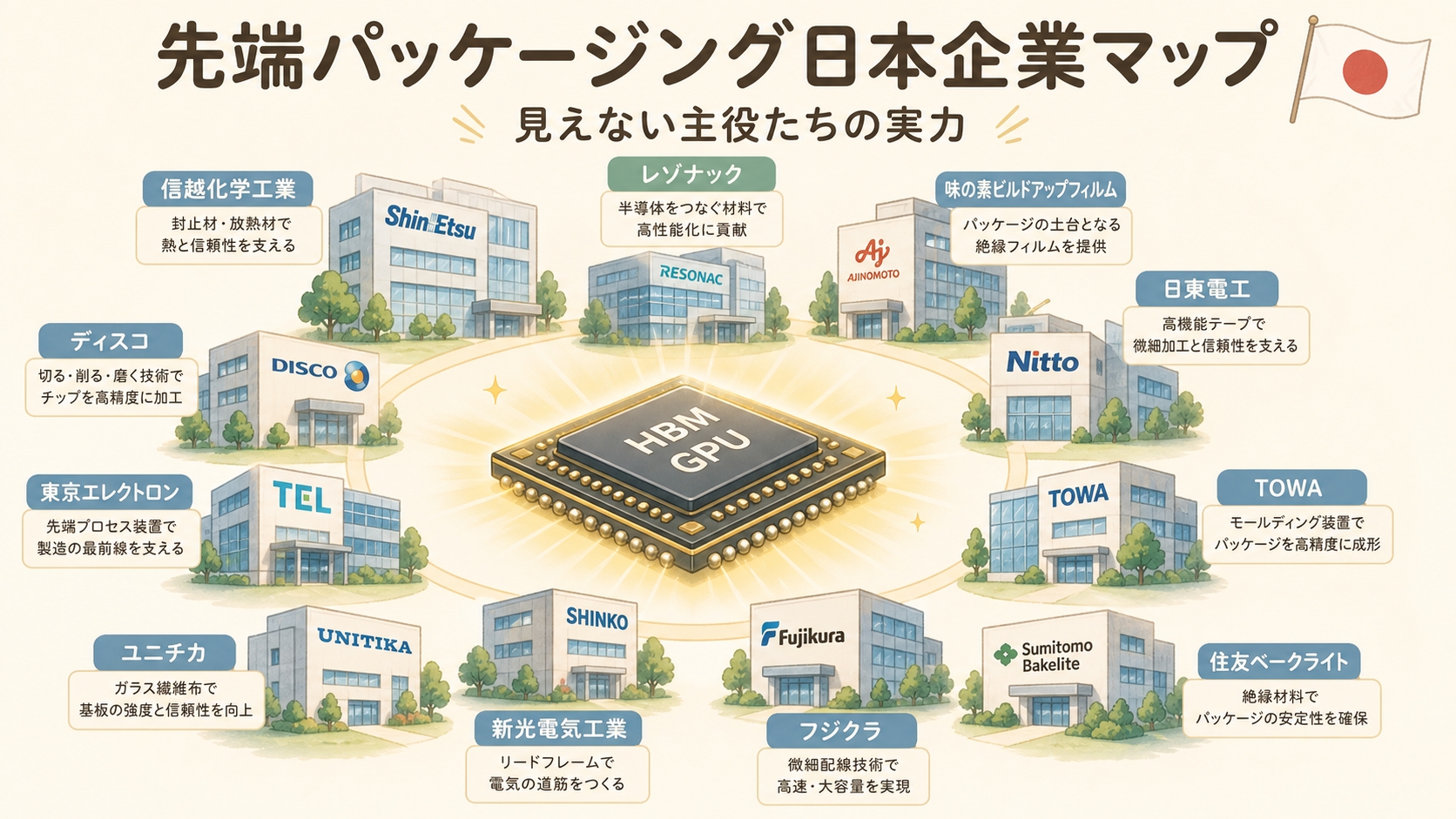
GB300を支えるサプライチェーン ── 誰が部品を作っているのか
🏭 GB300 1個の中に「世界トップ企業の技術」が詰まっている
NVIDIAは「設計」しかしていません。GB300 1個を作るには、世界中の数十社が連携しています。主要サプライヤーを3層で整理します。
上流:素材・装置
- 信越化学(4063):シリコンウェーハ
- SUMCO(3436):シリコンウェーハ
- レゾナック(4004):CMPスラリー
- 味の素(2802):ABFフィルム
- ASML:EUV露光装置
- ディスコ(6146):ダイシング
中流:製造・メモリ・パッケージ
- TSMC(2330.TW):B300ダイ製造(4NPプロセス)
- TSMC(CoWoS-L):パッケージング
- SK Hynix(000660.KS):HBM3E 12層スタック主供給
- Micron(MU):HBM3E補助供給
- イビデン(4062):ABFパッケージ基板
下流:設計・組立・販売
- NVIDIA(NVDA):GB300設計・統括
- Foxconn:NVL72ラック組立
- Quanta / Wistron:サーバーODM
- Supermicro(SMCI):NVL72システム販売
- Dell(DELL)/ HPE:エンタープライズ販売
GB300のHBM3Eは「12層スタック」(HBM3E-12H)と呼ばれる最新世代で、現時点でSK Hynix(000660.KS)がほぼ独占供給しています。Samsung・Micronも追従中ですが、量産歩留まりで先行するSK HynixがNVIDIAの最重要パートナーとなっています。
📖 【決定版】NVIDIA AI半導体サプライチェーン全マップ|15社で読み解く”AI帝国”の構造 →
NVIDIAを支える15社の役割と関係性を、サプライチェーン6階層で完全解説。
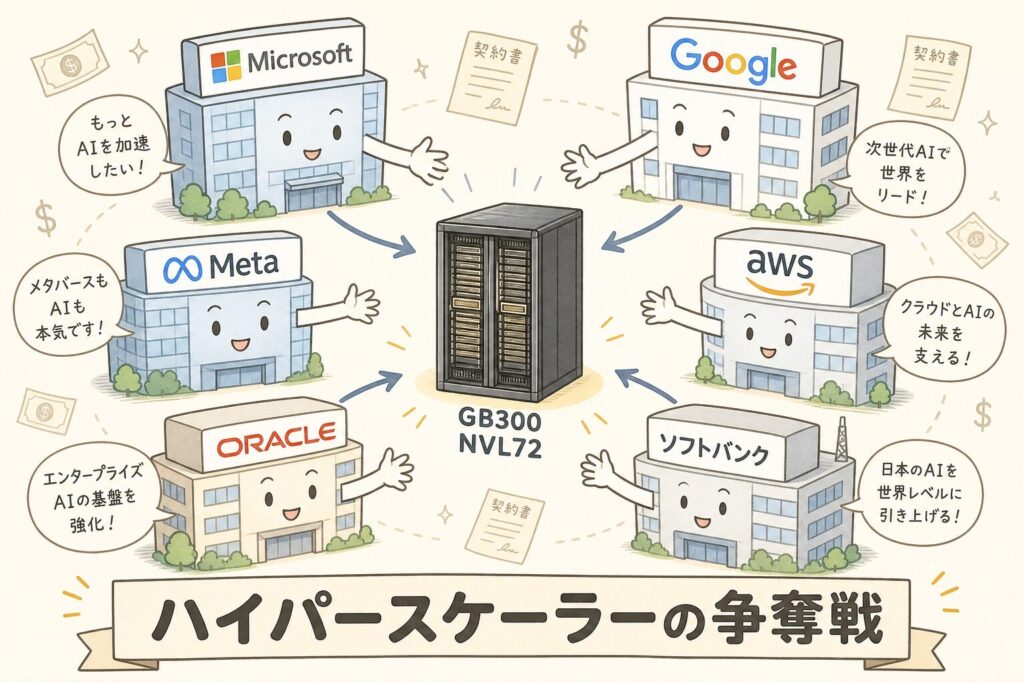
GB300は誰が買うのか ── ハイパースケーラーの争奪戦
💰 1ラック400〜500万ドルの「特売品」を世界中が奪い合う
GB300 NVL72は1ラックあたり約400〜500万ドル(約6〜7.5億円)と推定されています。それでもNVIDIAは週1,000台ペースで量産しており、注文は数年先まで埋まっています。
| 買い手 | 用途 | 注目ポイント |
|---|---|---|
| Microsoft(MSFT) | OpenAI(ChatGPT)の推論基盤 | 最大顧客の1社 |
| Google(GOOG) | Gemini推論・Google Cloud | 自社TPUと併用 |
| Meta(META) | Llama 4学習・推論 | 大量発注で先頭集団 |
| AWS(AMZN) | Bedrock・SageMaker | 自社Trainiumと併用 |
| Oracle(ORCL) | OCI AI Cloud | エンタープライズ向け強化 |
| CoreWeave / Lambda | AI特化型クラウド | 急成長中の新興勢力 |
| ソフトバンク | 北海道苫小牧AIデータセンター | 日本最大規模のGB300導入 |
あなたにとっての意味──投資家・学生・技術者の視点
GB300の量産加速は、NVIDIA(NVDA)の業績を直接押し上げますが、注目すべきはサプライチェーン全体です。SK Hynix(000660.KS)のHBM3E 12層独占供給、TSMC(2330.TW)のCoWoS-L生産能力、イビデン(4062)・味の素(2802)の基板素材、ディスコ(6146)・アドバンテスト(6857)の装置──すべてGB300需要に連動します。一方、注意点として「Vera Rubinへの世代交代」が2026年後半に迫っており、GB300の現役期間は短い可能性があります。NVIDIA決算では「GB300受注 vs Vera Rubin予約」のバランスが重要指標になります。なお特定銘柄の推奨ではありません。
GB300は「半導体技術の最先端」のショーケースです。チップレット設計、HBM3E 12層スタック、CoWoS-L、液冷システム──就活の半導体・AI関連企業の面接で必ず問われるトピックがすべて凝縮されています。情報系だけでなく、材料工学(HBM・ABF)、機械工学(液冷配管)、電気工学(電力供給・NVLink)、化学(冷却液・CMP)の知識がGB300のどの部分で活きるかを語れると、面接の説得力が変わります。
GB300 NVL72の「ラック150kW・100%液冷・1.5トン」というスペックは、データセンター設計のあらゆる前提を変えます。受変電設備、配管設計、床荷重、UPSバックアップ──全てが従来基準では足りません。AI需要が続く限り、こうした「物理インフラの再設計」を担える技術者の需要は爆発的に増加します。電気・機械・建築・冷却の実務スキルを持つ方は、AI時代に最も希少な人材です。
よくある誤解を整理する
| ❌ よくある誤解 | ✅ 実際はこう |
|---|---|
| 「GB300はB200の単純な後継機」 | GB300は「推論特化の強化版」。メモリ1.5倍、FP4性能1.55倍だが、製造プロセスやアーキテクチャは同じBlackwell系。世代スキップではなく中間強化。 |
| 「HBM3Eは普通のメモリのちょっと速い版」 | HBM3EはDRAMを12層も縦に積み重ねた特殊メモリ。普通のDDR5の20倍以上の帯域幅。GB300の288GB HBM3Eは、製造できるのが世界2〜3社のみ。 |
| 「GB300があれば既存DCで使える」 | ラック150kW・100%液冷・480kW級冷却ループが必要。既存データセンターの大半は物理的に対応不可。新設または大改修が必須。 |
| 「NVIDIAがGB300を作っている」 | NVIDIAは設計のみ。製造はTSMC、HBMはSK Hynix、組立はFoxconn。NVIDIAは「司令塔」で、実体は世界中の分業。 |
| 「GB300は長く現役」 | 2026年後半にVera Rubinが登場予定。GB300の現役期間は実質1年程度。NVIDIA AI GPUの世代交代は2年→1年に加速中。 |
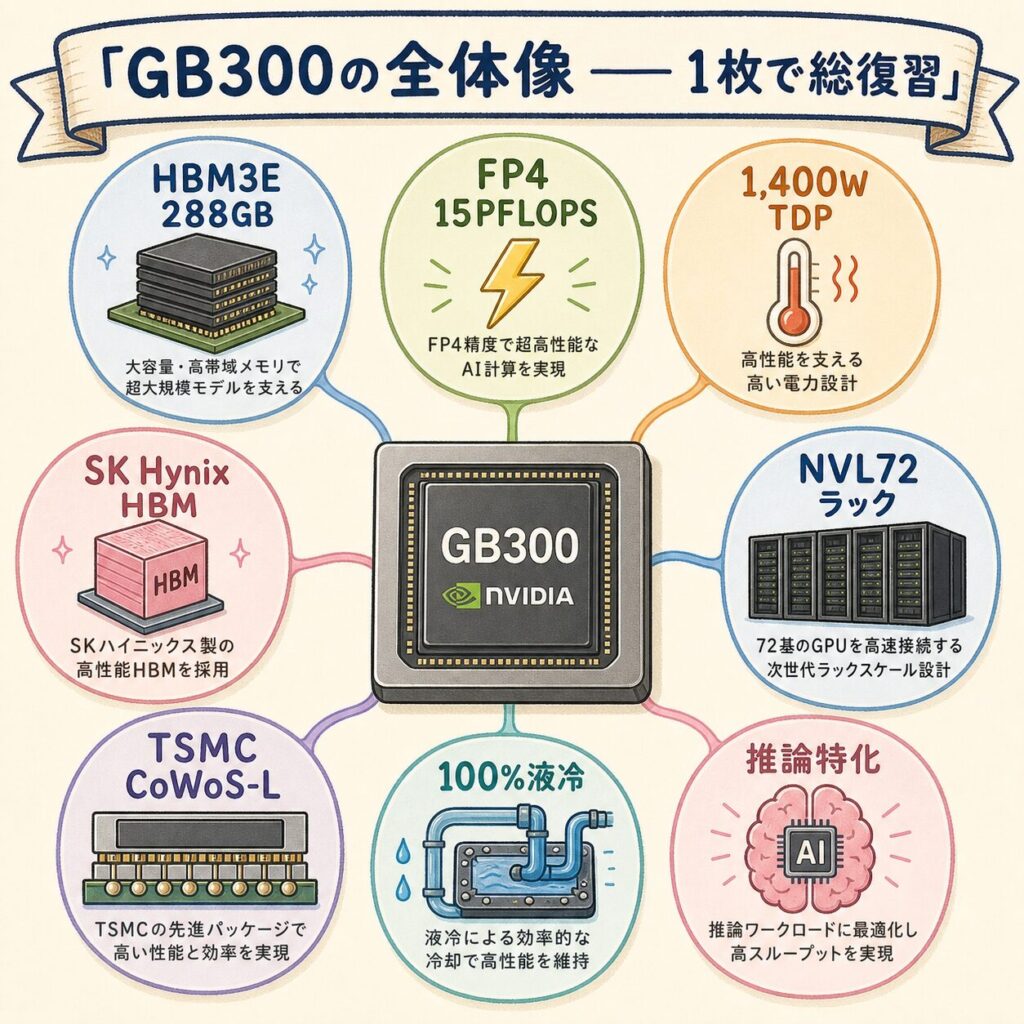
まとめ:GB300の全体像
① GB300とは:NVIDIAのBlackwell Ultraアーキテクチャを採用した最新AI GPU。2026年1月量産開始、週1,000台ペース。
② 主要スペック:HBM3E 288GB(B200比1.5倍)、FP4 15 PFLOPS(B200比1.55倍)、TDP 1,400W、CoWoS-Lパッケージング。
③ 4つの呼称:Blackwell Ultra(アーキ)→ B300(GPUダイ)→ GB300(CPU+GPU統合)→ GB300 NVL72(ラック完成品)。
④ NVL72ラック:72個のB300+36個のGrace CPUを1ラックに。HBM合計20.7TB、消費電力132〜150kW、完全液冷必須。1ラック約400〜500万ドル。
⑤ なぜ「推論最強」か:大規模AIモデルが1GPU内に収まるメモリ容量、FP4性能向上、アテンション処理2倍で、前々世代Hopperの40倍の推論性能。
⑥ 主要顧客:Microsoft・Google・Meta・AWS・Oracle・CoreWeave・ソフトバンクなど、ハイパースケーラーが奪い合う構造。
⑦ サプライチェーン:NVIDIA設計、TSMC製造、SK Hynix HBM、Foxconn組立。日本企業(信越化学・レゾナック・味の素・イビデン・ディスコ等)も上流で関与。
⑧ 次世代との関係:2026年後半にVera Rubin登場予定。GB300の現役期間は実質1年程度の見込み。
結局こういうことです。GB300は単なる「速いGPU」ではありません。AIサービスを「採算事業」として成立させる経済性を、推論コストの劇的削減で実現する戦略的製品です。だからこそ、世界中のハイパースケーラーが奪い合い、SK Hynix・TSMC・日本素材企業の業績が連動し、AIデータセンターの設計まで変わる──これがGB300を中心にAI産業全体が動いている本当の理由です。
❓ よくある質問(FAQ)
📚 次に読むべき記事
📘 【決定版】NVIDIA AI半導体サプライチェーン全マップ|15社で読み解く”AI帝国”の構造 →
GB300を支える15社の役割と関係性を、サプライチェーン6階層で完全解説するハブ記事。
📘 【完全図解】GPUサーバーとは?AIサーバーとの違いを初心者向けにやさしく解説 →
GB300がどんなサーバーに組み込まれてAI計算を担うのか、構成と消費電力を基礎から理解。
📘 【完全図解】GPUラックとは?「高密度化」でデータセンターが変わる理由 →
GB300 NVL72のような150kWラックが、データセンターをどう変えたのか構造から解説。
📘 【完全図解】HBMとは?GPUの隣にある「AI最重要メモリ」を初心者向けに解説 →
GB300の288GB HBM3Eの仕組み・3D積層・TSV・なぜ作れる企業が少ないのかを解説。
📘 【完全図解】CoWoSとは?NVIDIAのGPUを支える先端パッケージ技術 →
GB300のパッケージング技術CoWoS-Lの仕組みと、なぜTSMCが独占しているのかを解説。
📩 記事の更新情報を受け取りたい方へ
新しい記事が公開されたら、Xアカウント @shirasusolo でお知らせします。AIインフラの構造を一緒に学んでいきましょう。

コメント